
F-Curator 是一个跨平台应用程序,支持Mac和Windows系统,用来管理您自己的网络收藏夹,永久保存数据,解决用户的URL收藏需求。特点: 离线支持,高效运行; 轻松实现数据持久化; 自动提取远程资源(比如图标); 拖放排序与列表类别管理; 导出HTML方便在任何地方使用收藏夹; 支持快速搜索; URL和网络校验等。
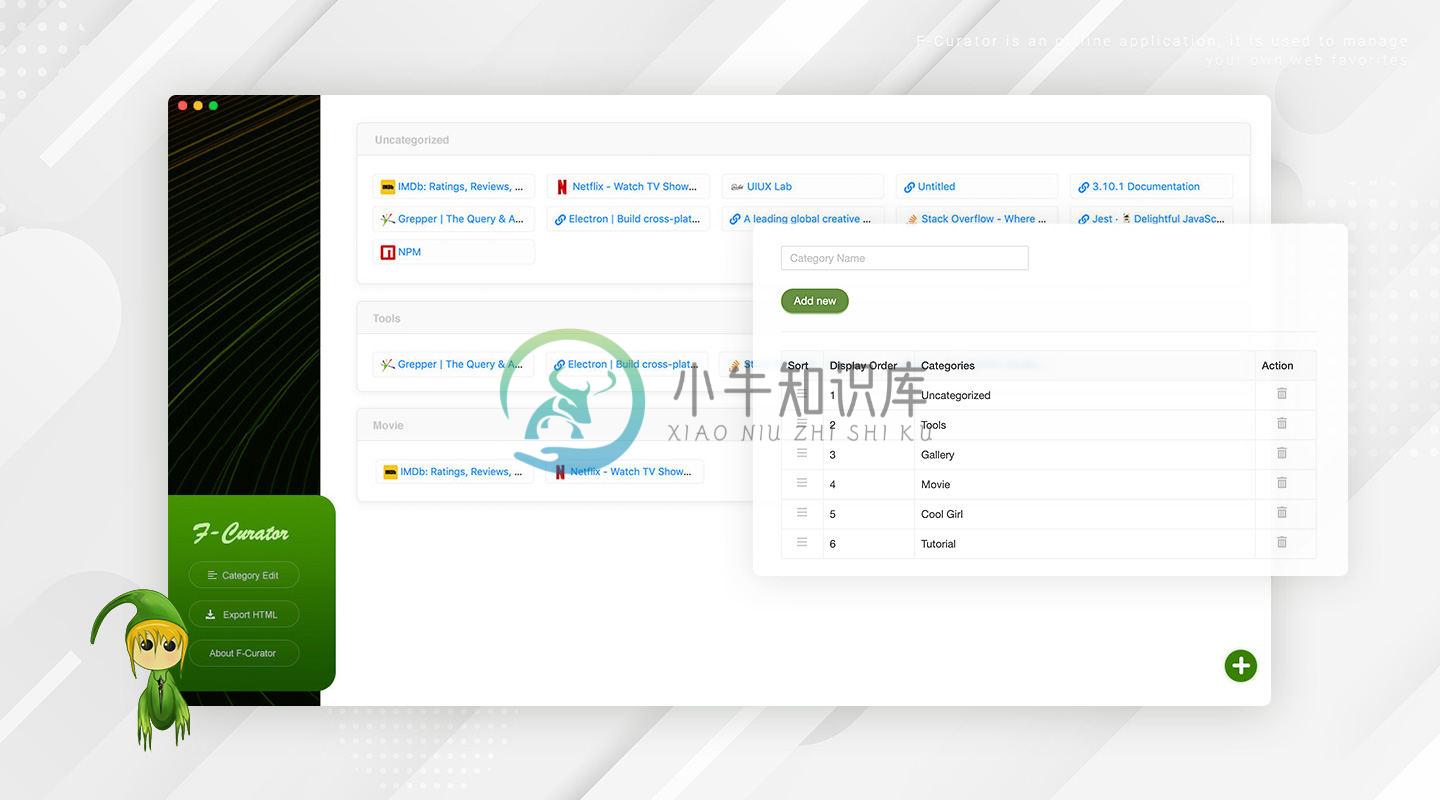
主要功能:
- 离线支持和快速的响应速度
- 轻松实现数据持久化
- 获取远程资源到本地数据库
- 类别管理和列表块管理
- 简单的拖放排序
- 导出独立的HTML文件,可以脱离APP在任意操作系统中使用收藏夹
- 支持导入数据库包
- 支持快速搜索URL和站点名称
- URL有效性和重复性的判断
- 自动提取远程资源,例如图标
-
安装pip [root 180-9 ~]$wget https://bootstrap.pypa.io/get-pip.py --2020-12-26 15:39:41-- https://bootstrap.pypa.io/get-pip.py Resolving bootstrap.pypa.io (bootstrap.pypa.io)... 151.101.228.175, 2a04:4e
-
在部署es集群收集日志,以及用prometheus实现监控的遇到很多的坑,大概花了两个礼拜的时间,走通了,希望可以对读者的有一定的帮助。 一、部署集群k8s, 这个需要自行部署,我选择的k8s 1.16 二、部署es集群 1、添加ECK自定义资源 kubectl apply -f all-in-one.yaml (说明,我设置的命名空间为logging-system) kubectl apply
-
前言 Curator 是 Elastic 官方发布的一个管理 Elasticsearch 索引的工具,可以完成许多索引生命周期的管理工作,例如清理创建时间超过7天的索引、每天定时备份指定的索引、定时将索引从热节点迁移至冷节点等等。 官网 https://www.elastic.co/guide/en/elasticsearch/client/curator/current/index.html
-
分布式系统中,对于一个复杂的任务,我们经常会选举一个Master节点,借助zk我们可以轻易的实现此项任务,在kafka以及spark的standalone模式下都是使用zk来实现Master选举,本文先从原理方面介绍为什么zk可以实现Master选举,然后利用curator的api进行Master选举实战。 zk进行Master选举原理 zookeeper的节点有两种类型: 持久节点和临时节点。临
-
原文内容: 文档:Zookeeper框架Curator使用.note 链接:http://note.youdao.com/noteshare?id=a5189de7d4f76a882ef52a6baabecd51&sub=F25E83B51A1A46E889F7C58B9B999360 理论内容来自:Zookeeper框架Curator使用 - 扎心了,老铁 - 博客园 (cnblogs.com)
-
Apache Curator入门实战 Curator是Netflix公司开源的一个Zookeeper客户端,与Zookeeper提供的原生客户端相比,Curator的抽象层次更高,简化了Zookeeper客户端的开发量。 1.Zookeeper安装部署 Zookeeper的部署很简单,如果已经有Java运行环境的话,下载tarball解压后即可运行。 [root@vm Temp]$ wget ht
-
好久没来了,一是在研究Zookeeper没时间,二是个人感觉没啥干货。 zookeeper号称是最好的配置管理服务器,最近平台准备将集群的配置信息迁移到上面,做成无状态集群。 其客户端基本都使用Curator作为包装,简便使用。 Curator能操作选举、分布式锁、服务发现、节点变动监听等非常简便的操作。 目前想法是集群中每个节点启动时,都注册到ZKServer上,然后每个节点都接收节点改变的
-
master选举原理 利用zookeeper节点特效,有序性,最先处理最小的节点 自定义实现队列具体代码 maven项目引入 <dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-framework</artifactId> <version>4.1.0</version> </dep
-
curator-recipes 2.7.1中的PathChildrenCache一般使用POST_INITILAIZED_MODE模式启动,RECONNECTED时会自动做rebuild操作,listener都在一个后台executor中完成。 因为可能出现false-positive(误报)和false-negative(漏报),一般需要定期做rebuild。 另外这个实现有个潜在问题,比较数据
-
一、简介 Curator是Netflix公司开源的一套Zookeeper客户端框架。了解过Zookeeper原生API都会清楚其复杂度。Curator帮助我们在其基础上进行封装、实现一些开发细节,包括接连重连、反复注册Watcher和NodeExistsException等。目前已经作为Apache的顶级项目出现,是最流行的Zookeeper客户端之一。从编码风格上来讲,它提供了基于Fluent的
-
Curator Framework操作zookeeper(1)-基本操作 1 SessionConnectionStateListener /** * 监听Session连接状态 */ public class SessionConnectionStateListener implements ConnectionStateListener { private static fina
-
Emacs 可以在当前位置创建一个书签,以便能够快速的返回。 与存储光标位置的寄存器略有不同 书签可以使用单词来命名,而不限于一个字符。起一个容易记住的名字 退出 Emacs 后,书签不会消失,下次还可以使用 表 25.13. Emacs 书签 C-x r m (name) M-x bookmark-set 设置书签 C-x r b (name) M-x bookmark-jump 跳转到书签 C
-
1. 创建站点 一般情况下,您需要在百度统计中创建站点才能获取跟踪代码及查看网站数据。 具体创建步骤: 登录百度统计,选择“管理->网站列表”标签; 点击页面右上方“新增网站”按钮,弹出新建对话框: 输入网站域名,域名格式不正确,将无法创建。 可输入如下4种域名形式: 主域名(如:www.baidu.com) 二级域名(如:sub.baidu.com) 子目录(如:www.baidu.com/su
-
对书签进行搜索、排序、修攺描述、删除、查看等操作 打开书签管理界面 操作步骤: 菜单栏: Navigate —> Bookmarks —> Show Bookmarks 快捷键: Mac: Fn + Command + F3 Windows\/Linux: Shift + F11 修攺书签描述 给书签加上描述信息 操作步骤: 在书签管理界面点击左上角的编辑按钮 —> 在弹窗中输入描述 快捷键: M
-
1. 创建站点 一般情况下,您需要在百度统计中创建站点才能获取跟踪代码及查看网站数据。 具体创建步骤: 登录百度统计,选择“管理->网站列表”标签; 点击页面右上方“新增网站”按钮,弹出新建对话框: 输入网站域名,域名格式不正确,将无法创建。 可输入如下4种域名形式: 主域名(如:www.baidu.com) 二级域名(如:sub.baidu.com) 子目录(如:www.baidu.com/su
-
我一直有一个问题与网站管理员工具API。我试图让脚本没有用户交互,并获得我需要的信息。我有谷歌分析与服务帐户,但这是不支持的网站管理员工具。 我目前正在尝试使用API服务器密钥,但当我尝试查询API返回时: 代码403:“用户没有足够的网站权限” 然而,我是我试图查询的网站的所有者。我已经检查了www.google.com/webmasters/tools/home,网站已经验证。 所以我在问我的
-
1. 预置事件和属性 系统默认为用户提供了预置事件和属性。预置事件包含页面浏览、元素点击和session。预置属性包含统计API能够自动获取的信息,如地域、来源、访问页面、访问时长等,详细内容可在“分析云-管理-数据管理-属性”查看。 2. 自定义事件和属性 2.1 定义属性 您也可以跳过这一步,在定义事件的过程中添加属性。步骤如下: 打开“分析云-管理-数据管理-属性”,点击“新建属性” 定义属