
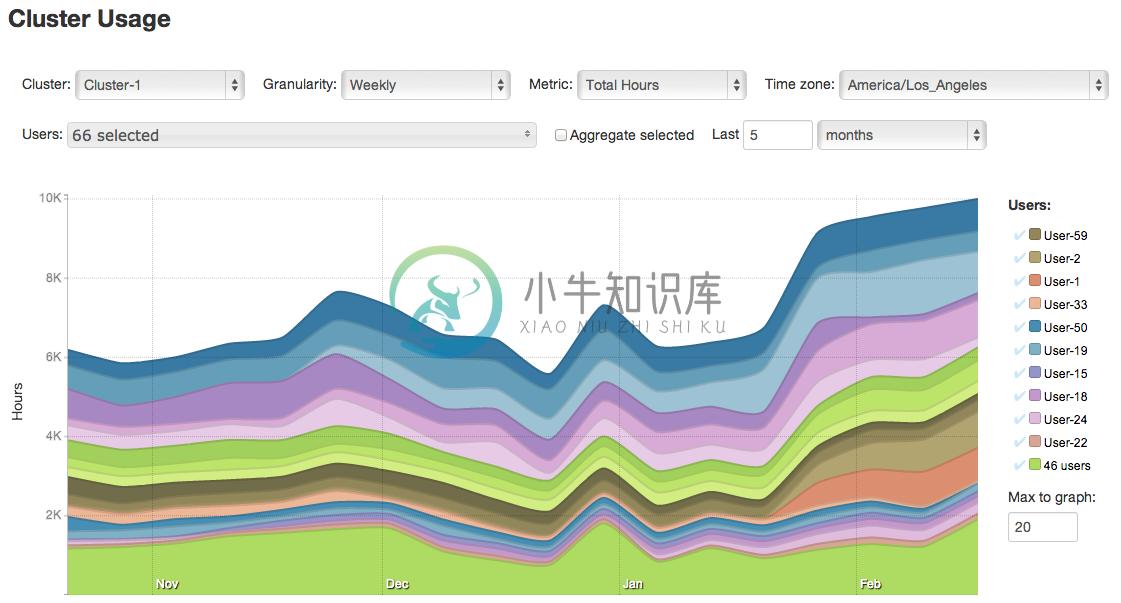
White Elephant 是一个 Hadoop 的日志聚合器和操作面板,可对 Hadoop 集群进行可视化监控。目前还不支持 Hadoop 2.0 版本。
-
One of the tasks administrators, including department chairs, often undertake is donor relations. I don't mean donors who bring checks but rather donors who bring "things." I have heard story after st
-
The Little Elephant loves chess very much. One day the Little Elephant and his friend decided to play chess. They've got the chess pieces but the board is a problem. They've got an 8 × 8 checkered boa
-
在本文中,我们将学习如何使用fluent-plugin-s3插件结合MinIO做为日志聚合器。 1. 前提提件 从这里下载MinIO Server。 从这里下载mc。 2. 安装 安装并运行Apache server 。 安装fluentd 和 fluent-plugin-s3。 3. 步骤 第一步:创建存储桶。 fluentd将会实时聚合半结构化apache日志到这个存储桶。 mc mb mym
-
我正在遵循这个关于通过java API创建YarnApp的示例。 https://github.com/hortonworks/simple-yarn-app 工作正常,但日志只存在于执行中,之后日志就消失了。 我怎么能通过代码捕捉到这个?或者启用一个选项?
-
我有一个窗口化的每小时聚合的数据流。 Datastreamds=.....
-
我试图将聚合操作的结果映射到DTO。它没有正确地映射,并且没有错误或日志消息来指示什么/哪里出错。 我已经试过_ID了;和字段作为id字段的替代品。
-
Django数据库抽象API描述了使用Django查询来增删查改单个对象的方法。然而,你有时候会想要获取从一组对象导出的值或者是聚合一组对象。这份指南描述了通过Django查询来生成和返回聚合值的方法。 整篇指南我们都将引用以下模型。这些模型用来记录多个网上书店的库存。 from django.db import models class Author(models.Model): na
-
问题内容: 我想从dnsmasq收集和处理日志,因此决定使用ELK。Dnsmasq用作DHCP服务器和DNS解析器,因此它为这两种服务创建日志条目。 我的目标是将所有包含请求者IP,请求者主机名(如果有)和请求者mac地址的DNS查询发送到Elasticsearch。这样一来,无论设备IP是否更改,我都可以按mac地址对请求进行分组,并显示主机名。 我想做的是以下几点: 1)阅读以下条目: 2)临
-
我正在Azure云服务上运行一个Java应用程序。我看过这篇文章,它展示了如何使用log4j:https://Azure.microsoft.com/en-us/documentation/articles/app-insights-java-trace-logs/配置java项目以向Azure insights发送日志。我的java应用程序已经在日志目录(application.log,erro
-
问题内容: 我有一个包含时间戳名为RDD 时间 长整型: 我正在尝试按值1,值2和时间分组为YYYY-MM-DD。我尝试按演员分组(时间为日期),但随后出现以下错误: 这是否意味着无法按日期分组?我什至尝试添加另一级别的强制转换以将其作为字符串: 哪个返回相同的错误。 我已经读到我可以在RDD上使用gregationByKey,但我不明白如何在几列中使用它并将其转换为YYYY-MM-DD字符串。我