
Panda.SimpleExcel 是一个简便操作 excel 的类库,包括读取、创建、修改等,支持直接从 DataSet、IEnumerable 以及 linq 语句转换成 excel 工作表,并支持通过特性控制工作表样式。
Hello World
var workbook = new WorkBook();
var sheet = workbook.NewSheet("Hello");
sheet.Rows[0][0].Value = "Hello World";
workbook.Save(@"F:\test.xls");
效果图
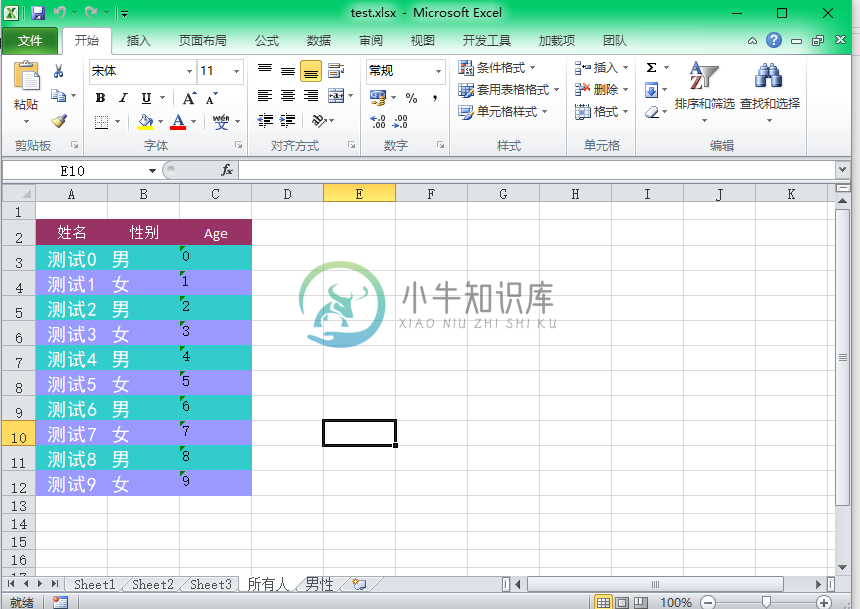
-
panda之excel操作总结(个人总结) 前言 收集了一些经济数据,这个是关于excel的一部分总结 在特定位置插入列 data.insert(2,'c','') # 2 :插入的列的位置 # ‘c':待插入列的列名 # ‘ ’:插入的值,这里插入的是空值 data Out[56]: a b c 0 1 2 1 3 4 ################# data.in
-
import pandas as pd #excel文件和pandas的交互读写,主要使用到pandas中的两个函数,一个是pd.ExcelFile函数,一个是to_excel函数 #使用pandas读取excel文件 file=pd.ExcelFile('lalla.xls') #显示所有的sheet的名字 print(file.sheet_names) #显示第
-
将对象写入Excel工作表。 要将单个对象写入Excel .xlsx文件,仅需要指定目标文件名。要写入多张纸,必须创建一个ExcelWriter对象和目标文件名,并在文件中指定要写入的工作表。 通过指定唯一可以写入多张纸sheet_name。将所有数据写入文件后,必须保存更改。请注意,创建一个ExcelWriter文件名已存在的对象将导致现有文件的内容被删除。 参数: excel_writer:s
-
import pandas as pd pd.set_option('display.max_columns', None) import re # finallist=[] # for i in range(0,len(ISIN)): # DMdata = DM[i] # QBdata = QB[i] # DMdata = DMdata.split(';') #
-
pandas 在数据分析方面功能强大,最近公司用到excel的调用。被迫营业,呜呜~~ 基础知识 import pandas as pd # header:列索引,index_col:行索引 # usecols:str-list:['名字','年龄'] pf = pd.read_excel("test.xlsx",sheet_name="学生",index_col=0,usecols="A:B"
-
最近 写了一个脚本处理excel,发现pandas处理数据的时候真的很强大, 首先 导入pandas库 import pandas # 导入文件 data = pandas.read_excel('***.xlsx') # df是一个dataform对象,类似一个二维表格 df = pandas.DataFrame(data) printf(df) # 显示结果是 a_ b_
-
【功能一】 姓名 体重 A 100 S 200 D 300 F 400 G 500 姓名 体重 S 100 D 200 F 500 G 600 H 600 两个excel,需要找到姓名相同的输出历史体重和当前体重,想要的结果为: 姓名 历史体重 当前体重 A 100 S 200 100 D 300 200 F 400 500 G 500 600 H 600 import tkinter as t
-
import xlrd import pandas as pd import numpy as np import os from pandas import DataFrame,Series import re # data = xlrd.open_workbook(r'C:\Users\Admin\Desktop\test.xls') # table = data.sheets()[2]
-
从昨天开始在网易云课堂学习 Python数据分析-pandas玩转Excel 课程,python玩转excel,视频中所用资料在蔓藤教育。 excel读取写入 def readExcel(): people = pd.read_excel('D:/study/pythonTest/people.xlsx') print(people.shape)#行数 列数 print(p
-
Pandas: Python界的Excel 前言 在日常工作中使用Excel可以非常方便地进行数据分析,但是在数据量变大时(超过10000行)时Excel会变得很慢,并且Excel分析出来的数据难以给其它程序(比如用于机器学习的模型训练)使用。 本文以Excel的角度来对照Pandas的相应功能,以帮助快速掌握Pandas进行数据分析。 Excel vs. Pandas 在Jupyter Note
-
本文向大家介绍C#实现的Excel文件操作类实例,包括了C#实现的Excel文件操作类实例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了C#实现的Excel文件操作类。分享给大家供大家参考,具体如下: 更多关于C#相关内容感兴趣的读者可查看本站专题:《C#操作Excel技巧总结》、《C#程序设计之线程使用技巧总结》、《C#常见控件用法教程》、《WinForm控件用法总结》、《C#数据结构
-
主要内容:to_excel(),read_excel()Excel 是由微软公司开发的办公软件之一,它在日常工作中得到了广泛的应用。在数据量较少的情况下,Excel 对于数据的处理、分析、可视化有其独特的优势,因此可以显著提升您的工作效率。但是,当数据量非常大时,Excel 的劣势就暴露出来了,比如,操作重复、数据分析难等问题。Pandas 提供了操作 Excel 文件的函数,可以很方便地处理 Excel 表格。 to_excel() 通过 to_ex
-
本文向大家介绍asp导出excel文件最简单方便的方法,包括了asp导出excel文件最简单方便的方法的使用技巧和注意事项,需要的朋友参考一下 由于excel软件能识别table格式的数据,所以asp只需要输出table格式的html代码,同时设置好contenttype,增加保存为附件的响应头即可将输出的html代码保存为xls文件。 asp导出excel文件源代码如下:
-
该包定义了一些操作 byte slice 的便利操作。因为字符串可以表示为 []byte,因此,bytes 包定义的函数、方法等和 strings 包很类似,所以讲解时会和 strings 包类似甚至可以直接参考。 说明:为了方便,会称呼 []byte 为 字节数组 2.2.1 是否存在某个子slice // 子slice subslice 在 b 中,返回 true func Contains(
-
15.5 利用SimpleJdbc类简化JDBC操作 SimpleJdbcInsert类和SimpleJdbcCall类主要利用了JDBC驱动所提供的数据库元数据的一些特性来简化数据库操作配置。这意味着可以在前端减少配置,当然你也可以覆盖或是关闭底层的元数据处理,在代码里面指定所有的细节。 15.5.1 利用SimpleJdbcInsert插入数据 让我们首先看SimpleJdbcInsert类可
-
虽然 io 包提供了不少类型、方法和函数,但有时候使用起来不是那么方便。比如读取一个文件中的所有内容。为此,标准库中提供了一些常用、方便的IO操作函数。 说明:这些函数使用都相对简单,一般就不举例子了。 NopCloser 函数 有时候我们需要传递一个io.ReadCloser的实例,而我们现在有一个io.Reader的实例,比如:strings.Reader,这个时候NopCloser就派上用场