
moloch是一个开源的、大型的IPv4 PCAP,用于索引和收集数据库系统。Moloch目的并不是替换IDS引擎,而是它们一起工作,以标准PCAP的格式来存储和索引所有网络流量,提供快速访问。
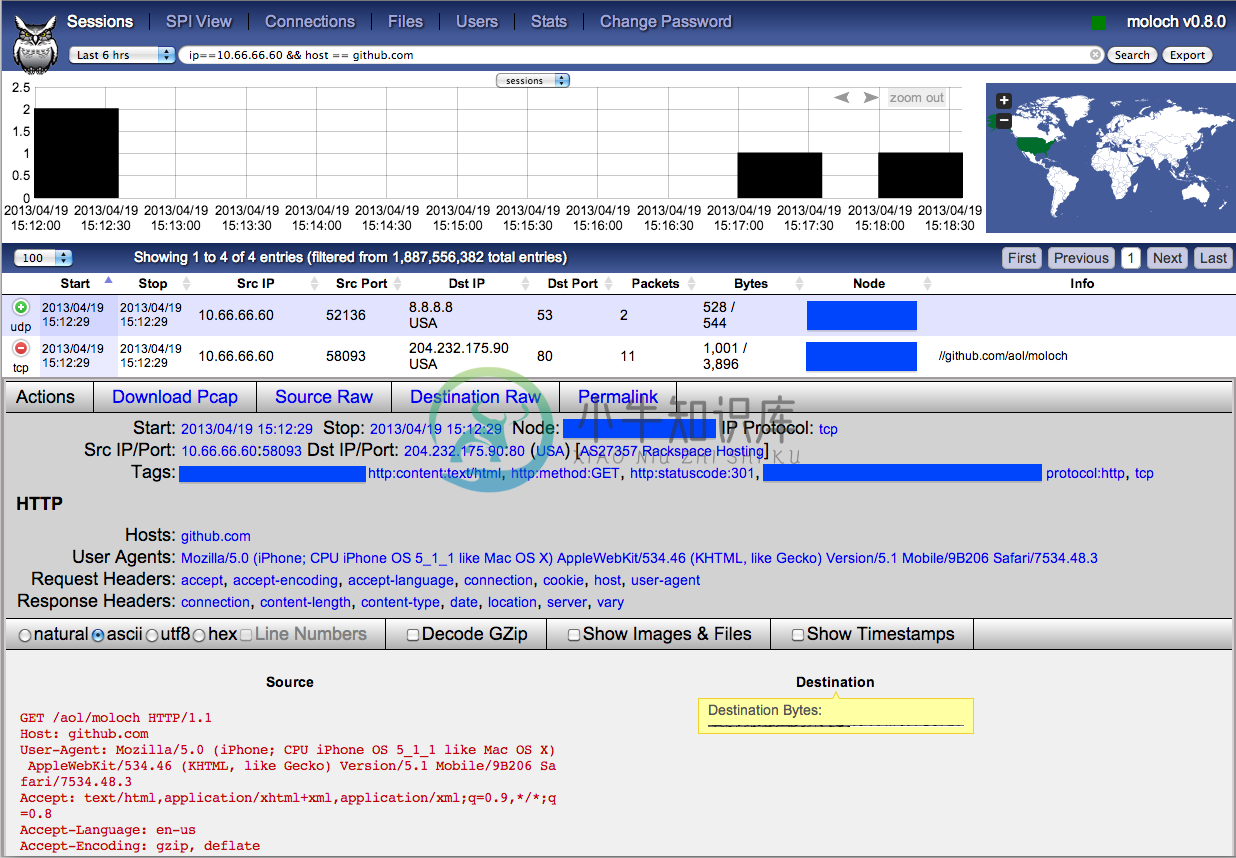
Sessions Tab
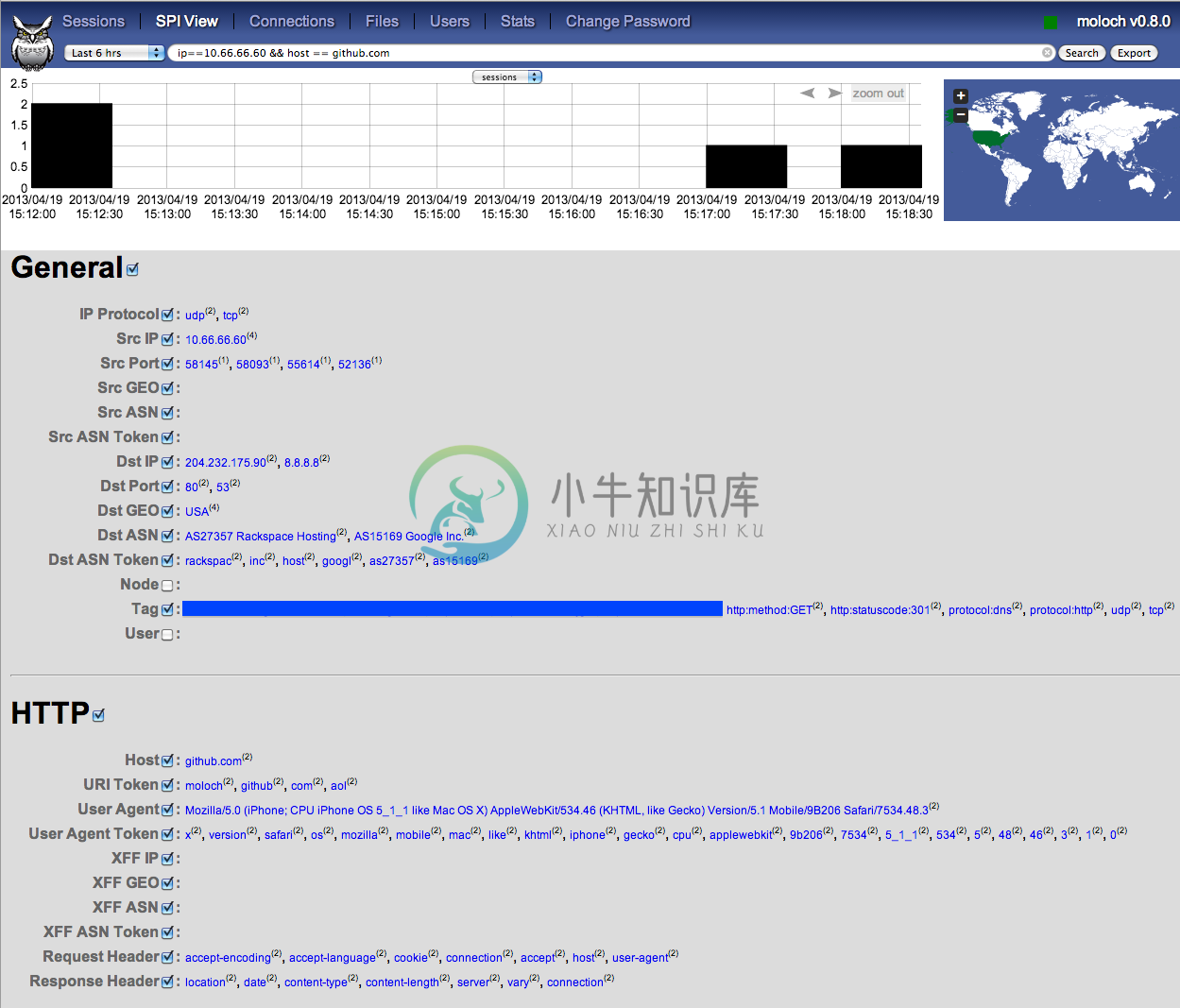
SPI View Tab
-
官网: https://molo.ch/ github:https://github.com/aol/moloch Moloch网络流量分析工具 介绍 moloch安装配置 #打包命令 ./easybutton-build.sh --install #简单打包查看页面 项目路径 :xPacket/viewer/vueapp 下 创建tmp.sh 文件 node ./build/build.j
-
准备: Elasticsearch 首先,Arkime对数据库Elasticsearch有版本要求,这可以使用现有的docker镜像来提供,这里就不多说了,附上docker-compose配置: Arkime 2.7 requires ES 7.4+ version: '2.2' services: elasticsearch: image: elasticsearch:7.8.1
-
0X01 moloch简介 Moloch是一款由 AOL 开源的,能够大规模的捕获IPv4数据包(PCAP)、索引和数据库系统。所以我的Capture Machines和Elasticsearch Machines都放在一台上面, 有条件的强烈推荐把这2个组件分离开来。 根据官方介绍,需要留意一下事情: 1.Moloch不支持32位 2.内核4.X 有助于抓包性能提升 0x02 Moloch安装
-
搜索栏 字符串搜索 通配符: 如果表达式中出现*,则假定使用通配符匹配。支持的通配符是*,它匹配任何字符序列(包括空字符),以及?,它匹配任何单个字符。 通配符查询针对全文字符串运行,如果字段启用大小写规范化,则在大小写规范化之后运行。 例如http.uri == "www.f*k.com"将捕获http.uri字符串,它包含www.fork
-
一、安装moloch 的环境 [root@clusternode0x86 moloch]# uname -r
-
一、安装 1.1下载 wget https://files.molo.ch/builds/centos-7/moloch-1.5.2-1.x86_64.rpm 1.2 安装(按提示操作) rpm -ivh moloch-1.5.2-1.x86_64.rpm Instructions for using the prebuilt Moloch packages. Please report any
-
Dec 6 19:04:28 main.c:610 main(): THREAD 0x7fb975476800 Dec 6 19:04:28 main.c:169 parse_args(): WARNING: gethostname doesn't return a fully qualified name and getdomainname failed, this may cause is
-
https://molo.ch/faq Moloch is not working 1、curl http://ES-IP:9200/_cat/health,检查ES的工作状态 2、/data/moloch/db/db.pl http://ES-IP:9200 info 是否进行初始化 3、浏览测试网页http://viewerhostname:8005,考虑是
-
数据库创建索引能够大大提高系统的性能。 第一,通过创建唯一性的索引,可以保证数据库表中每一行数据的唯一性。 第二,可以大大加快数据的检索速度,这也使创建索引的最主要的原因。 第三,可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。 第四,在使用分组和排序子句进行数据检索时,同样可以显著的减少查询中查询中分组和排序的时间。 第五,通过使用索引,可以在查询的过程中,使用优化隐藏器,
-
基本概念 在数据库中,索引的含义与日常意义上的“索引”一词并无多大区别(想想小时候查字典),它是用于提高数据库表数据访问速度的数据库对象。 索引可以避免全表扫描。多数查询可以仅扫描少量索引页及数据页,而不是遍历所有数据页。 对于非聚集索引,有些查询甚至可以不访问数据页。 聚集索引可以避免数据插入操作集中于表的最后一个数据页。 一些情况下,索引还可用于避免排序操作。 索引的存储 一条索引记录中包含的
-
我的Ionic 5应用程序中有以下Firestore数据库结构。 书(集合) {bookID}(带有book字段的文档) 赞(子集合) {userID}(文档名称作为带有字段的用户ID) 集合中有文档,每个文档都有一个子集合。Like collection的文档名是喜欢这本书的用户ID。 我正在尝试进行查询以获取最新的,同时尝试从子集合中获取文档以检查我是否喜欢它。 我在这里做的是用每个图书ID调
-
我正在实验/学习Spring数据neo4j。我有一个非常简单的应用程序,可以存储来自推特的推文。请参阅下面的片段。 问题是,存储哈希标签的最佳方式是什么,这样我就可以快速获取它们所属的推文?我能想到的是要么在Set上使用@索引,要么实际上创建一个单独的标签NodeEntity,并在它和推文之间建立关系。我找不到在NodeEntity中索引集合的任何留档,所以我不确定是否在set对象上创建了索引,或
-
问题内容: 似乎在elasticsearch中,您将在集合上定义索引,而在关系数据库中,您将在列上定义索引。如果整个集合都已建立索引,为什么需要对其进行定义? 问题答案: 不幸的是,使用了“索引”一词,这意味着ES和关系数据库中的一些事物(在编辑中非常不同),因为它们针对不同的用例进行了优化。 数据库中的“索引”是辅助数据结构,它使查询和查询变得快速,并且它们通常存储的值与表中显示的值完全相同。您
-
我正在使用: neo4j 2.0。1 我有一个具有属性名称的节点人员,我想用Lucene语法搜索该属性。我在我的存储库中使用findByNamelike方法,它非常适合像value*或*value或*etc这样的查询。 但是我需要这样的查询{A*TO D*}。我发现了一个弃用的方法findAllByQuery(名称,查询),用这个方法我可以实现我的需求。 > 我还注意到,如果我从cypher创建节