
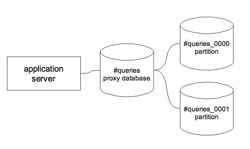
PL/Proxy和PostgreSQL集群的结构关系可以用下图清楚地表示
下面是详细的安装方法:
以下操作是在三台不同机器上执行的情况,其中plproxy节点的机器名是P1,数据库节点的机器名分别是D1和D2。机器硬件配置如下,同时需要Linux-4.2、postgresql-8.3.0和plproxy-2.0.4,pgbouncer的安装过程略去。
plproxy节点:
hostname: P1
inet addr:10.0.0.1
OS: Linux 2.6.9-42.ELsmp
CPU:Intel(R) Xeon(R) CPU L5320 @ 1.86GHz
MemTotal: 514440 kB
node1节点:
hostname:D1
inet addr:10.0.0.2
OS: Linux 2.6.9-42.ELsmp
CPU:Intel(R) Xeon(R) CPU L5320 @ 1.86GHz
MemTotal: 254772 kB
node2节点:
hostname:D2
inet addr:10.0.0.3
OS: Linux 2.6.9-42.ELsmp
CPU:Intel(R) Xeon(R) CPU L5320 @ 1.86GHz
MemTotal: 254772 kB
1. 在P1, D1,D2上安装postgresql-8.3.0,并创建URTCluster数据库
## Compile and install
gunzip postgresql-8.3.0.tar.gz
tar xf postgresql-8.3.0.tar
cd postgresql-8.3.0
./configure –prefix=/home/y/pgsql –with-perl
gmake
gmake check
sudo gmake install
## Add Unix User
sudo adduser postgres
sudo mkdir /home/y/pgsql/data
sudo chown postgres /home/y/pgsql/data
## Init DB and Start service
sudo -u postgres /home/y/pgsql/bin/initdb -D /home/y/pgsql/data
sudo -u postgres /home/y/pgsql/bin/postgres -D /home/y/pgsql/data >logfile 2>&1 &
## Create DB and Use Local Connection
sudo -u postgres /home/y/pgsql/bin/createdb URTCluster
##检查数据库是否已经创建
sudo -u postgres /home/y/pgsql/bin/psql -d URTCluster
#D1,D2必须允许P1访问
#编辑postgresql.conf,打开tcp连接端口
sudo vim /home/y/pgsql/data/postgresql.conf
listen_addresses = ‘*’
port = 5432
#添加postgres用户的认证
sudo vim /home/y/pgsql/data/pg_hba.conf
host URTCluster postgres 10.0.0.0/16 trust
# 重起服务器
sudo -u postgres /home/y/pgsql/bin/pg_ctl -D /home/y/pgsql/data stop
sudo -u postgres /home/y/pgsql/bin/postgres -D /home/y/pgsql/data >logfile 2>&1 &
sudo -u postgres /home/y/pgsql/bin/pg_ctl -D /home/y/pgsql/data reload
2. 在P1上安装plproxy-2.0.4
#检查$PATH变量里是否有/home/y/pgsql/bin目录,如果没有,修改你的.bash_profile文件,添加/home/y/pgsql/bin到path里。
echo $PATH
gunzip plproxy-2.0.4.tar.gz
tar xf plproxy-2.0.4.tar
cd plproxy-2.0.4
gmake
sudo gmake install
#创建plproxy
sudo -u postgres /home/y/pgsql/bin/psql -f
/home/y/pgsql/share/contrib/plproxy.sql URTCluster
3. 在P1, D1,D2上安装plpgsql
sudo -u postgres /home/y/pgsql/bin/createlang plpgsql URTCluster
4. 在P1上创建schema
sudo -u postgres /home/y/pgsql/bin/psql -d URTCluster
URTCluster=# create schema plproxy;
5. 在P1上初始化设置
#plproxy的配置是通过三个函数(过程)实现的,这三个函数的标准模版如下:
#这个函数是让plproxy可以找到对应的集群
CREATE OR REPLACE FUNCTION plproxy.get_cluster_partitions(cluster_name text)
RETURNS SETOF text AS $$
BEGIN
IF cluster_name =’URTCluster’ THEN
RETURN NEXT ‘dbname=URTCluster host=10.0.0.2′;
RETURN NEXT ‘dbname=URTCluster host=10.0.0.3′;
RETURN;
END IF;
RAISE EXCEPTION ‘Unknown cluster’;
END;
$$ LANGUAGE plpgsql;
#这个函数是plproxy用于判断是否给前端返回已经cache过的结果用的
CREATE OR REPLACE FUNCTION plproxy.get_cluster_version(cluster_name text)
RETURNS int4 AS $$
BEGIN
IF cluster_name = ‘URTCluster’ THEN
RETURN 1;
END IF;
RAISE EXCEPTION ‘Unknown cluster’;
END;
$$ LANGUAGE plpgsql;
#这个函数是获取不同的集群的配置
create or replace function plproxy.get_cluster_config(cluster_name text, out key text, out val text)
returns setof record as $$
begin
key := ’statement_timeout’;
val := 60;
return next;
return;
end;
$$ language plpgsql;
#把这三个函数放在一个URTClusterInit.sql文件里,并执行
sudo -u postgres /home/y/pgsql/bin/psql -f URTClusterInit.sql -d URTCluster -h 10.0.0.1
6. 在D1,D2节点上设置
#给每个数据库节点都创建一张表users
CREATE TABLE users (
username text,
email text
);
#给每个数据库节点都创建一个插入函数
CREATE OR REPLACE FUNCTION insert_user(i_username text, i_emailaddress text)
RETURNS integer AS $$
INSERT INTO users (username, email) VALUES ($1,$2);
SELECT 1;
$$ LANGUAGE SQL;
#把函数保存在 URTClusterNodesInit_1.sql文件里,并执行
sudo -u postgres /home/y/pgsql/bin/psql -f URTClusterNodesInit_1.sql -h 10.0.0.2 -d URTCluster
sudo -u postgres /home/y/pgsql/bin/psql -f URTClusterNodesInit_1.sql -h 10.0.0.3 -d URTCluster
7. 在P1节点上设置
#在 plproxy 节点上创建一个同名的插入函数,用于进行集群检索
CREATE OR REPLACE FUNCTION insert_user(i_username text, i_emailaddress text)
RETURNS integer AS $$
CLUSTER ‘URTCluster’;
RUN ON hashtext(i_username);
$$ LANGUAGE plproxy;
#在 plproxy 节点上创建一个查询函数,用于进行集群检索
CREATE OR REPLACE FUNCTION get_user_email(i_username text)
RETURNS text AS $$
CLUSTER ‘URTCluster’;
RUN ON hashtext(i_username) ;
SELECT email FROM users WHERE username = i_username;
$$ LANGUAGE plproxy;
#把函数保存在 URTClusterProxyExec.sql文件里,并执行
sudo -u postgres /home/y/pgsql/bin/psql -f URTClusterProxyExec_1.sql -h 10.0.0.1 -d URTCluster
8. 在P1上测试结果
sudo -u postgres /home/y/pgsql/bin/psql -d URTCluster
SELECT insert_user(’Sven’,’sven@somewhere.com’);
#被保存到D2, 可以用select hashtext(’Sven’) & 1验证,被hash到 partition 1
SELECT insert_user(’Marko’, ‘marko@somewhere.com’);
#被保存到D2, 可以用select hashtext(’Marko’) & 1验证,被hash到 partition 1
SELECT insert_user(’Steve’,’steve@somewhere.cm’);
#被保存到D1, 可以用select hashtext(’Steve’) & 1验证,,被hash到 partition 0
SELECT get_user_email(’Sven’);
SELECT get_user_email(’Marko’);
SELECT get_user_email(’Steve’);
-
最近朋友要上一个系统,设计百亿级数据。我去帮着搭建系统,采用pg/proxy集群,业务相关就不说了,这里就把简单技术验证放出来。相关人员比较保守,就用了OS官方的安装包,pg版本9.1. 规划中两台服务器上验证,一个上三个实例(一个实例做代理,另外两个做数据节点),一个上两个实例(做数据节点) 数据节目录如下,不过是在两台服务器上,如上所说。 /opt/pg91/pgdata0 /opt/pg91
-
下载安装包 http://pgfoundry.org/projects/plproxy tar -zxvf plproxy-2.5.tar.gz [root@node2 upload]# chown highgo:highgo plproxy-2.5 -R yum install flex bison -y [highgo@node2 plproxy-2.5]$ make [highgo@node
-
看了一下pl/proxy,文档很多,都当参考吧,转载其中两篇,这是其一 参考: http://plproxy.projects.pgfoundry.org/doc/tutorial.html http://www.tbdata.org/archives/723 http://bbs.chinaunix.net/thread-1859285-1-1.html http://blog.chinauni
-
在postgresql安装编译pl/ploxy-2.5报错 postgres@node2 plproxy-2.5]$ make flex -osrc/scanner.c src/scanner.l bison -b src/parser -d src/parser.y gcc -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-afte
-
主要为ES6标准入门的内容归纳。 Proxy Proxy 用于修改某些操作的默认行为,等同于在语言层面做出修改,所以属于 种“元编程”( meta programming ),即对编程语言进行编程。 Proxy 可以理解成在目标对象前架设 个“拦截”层 ,外界对该对象的访问都必须先通过这层拦截,因此提供了 种机制可以对外界的访问进行过滤和改写。 具体用法 ES6原生提供了Proxy构造函数,用于生
-
Zabbix安装 标签(空格分隔):Zabbix Zabbix安装 Zabbix配置 平台 设备信息: Linux内核: Linux 2.6.39.4 #1 SMP Wed Aug 17 15:27:12 CST 2016 i686 i686 i386 GNU/Linux zabbix安装包下载 zabbixRPM包下载路径 Zabbix-3.2.6 + mysql 所需压缩包 fping
-
java.lang.ClassCastException: com.sun.proxy.$Proxy9 cannot be cast to com.link.test.service.impl.TestService http://www.cnblogs.com/MrSaver/p/6104130.html 定义代理类: public UserDaoImpl implements UserDao{
-
代写CMPSC 311作业、代做C/C++,web语言作业、代写HTML/WEB课程设计作业、代做Web Proxy作业 CMPSC 311, Fall 2018 Proxy Lab: Writing a Caching Web Proxy Assigned: Wed, Nov 14, 2018 Due: Wed, Dec 5, 11:59 PM Last Possible Time to Tur
-
ProxyPool启动出现错误:redis.exceptions.ConnectionError: Error 111 connecting to 127.0.0.1:6379. Connection refused. 可能与您的问题没有直接关系,但是我遇到了同样的错误,结果发现我的系统上未安装redis-server软件包,或者是没有启动。 解决方法是sudo apt-get install r
-
Name 3proxy.cfg - 3proxy configuration file Description Common structure: Configuration file is a text file 3proxy reads configuration from. Each line of the file is a command executed immediately, as
-
视频地址:https://www.youtube.com/watch?v=3EG9FgYaf8M&list=PL9Q0S-CmtAhJVjwnK5ip6H84sCuRQcACY&index=27 之前在依赖注入那章讲过了。proxy是一种设计模式。就是这个对象虽然被依赖注入到了另一个对象中。但是如果没有调用这个依赖注入对象的方法。那么即使在构造函数内初始化了这个对象。也不会对这个对象进行实例化。
-
Error:Connection timed out: connect. If you are behind an HTTP proxy, please configure the proxy set
问题详情 具体怎么产生的记不清了,使用下面的代码可以解决。 解决方案 在gradle.properties文件中添加相关代理 systemProp.http.proxyHost=some.proxy.adress.com systemProp.http.proxyPort=3128 systemProp.https.proxyHost=some.proxy.adress.com systemPro
-
代理模式(Proxy) SpringAOP和SpingMVC底层实现使用了代理模式。 代理模式的定义与特点 代理模式的定义:由于某些原因需要给某对象提供一个代理以控制对该对象的访问。这时,访问对象不适合或者不能直接引用目标对象,代理对象作为访问对象和目标对象之间的中介。 代理模式的主要优点有: 代理模式会造成系统设计中类的数量增加 在客户端和目标对象之间增加一个代理对象,会造成请求处理速度变慢;