
Coherence是Oracle为了建立一种高可靠和高扩展集群计算的一个关键部件,集群指的 是多于一个应用服务器参与到运算里。Coherence的主要用途是共享一个应用的对象(主要是java对象,比如Web应用的一个会话java对象)和 数据(比如数据库数据,通过OR-MAPPING后成为Java对象)。
简单来说,就是当一个应用把它的对象或数据托管给Coherence管理的时候,该对象或数据就能够在整个集群环境(多个应用服务器节点)共享,应 用程序可以非常简单地调用get方法取得该对象,并且由于Coherence本身的冗余机制使得任何一个应用服务器节点的失败都不会影响到该对象的丢失。 其实如果不使用coherence,对于一个会话在多个应用服务器节点的共享一般是通过应用服务器本身的集群技术,而Coherence的创造者则认为基 于某种应用服务器技术的集群技术来共享会话变量的技术并不完整,而专门开发出Coherence这个产品(原来称为tangosol)并且最后被 Oracle收购,这个产品既有原来各种应用服务器集群所具有的各种技术特点,而且又增加了原来各种应用服务器集群技术所没有的各种特性。
要学习这个产品,需要记住并注意的一点是:Coherence所有的设计都是基于多个(可以是非常多)的JVM,很多Coherence的测试都是使用几十甚至上百个节点来进行的。
Coherence的一些技术特点
Coherence产品首先是被设计用于高扩展性:
所谓高扩展性就是当一个应用服务器能够处理2000笔交易,则10个应用服务器应该能够处理20000笔交易。
一般而言,整个应用架构的扩展性由架构里的最不能扩展的部位(称之为瓶颈)决定,这个瓶颈一般而言都是数据源的处理,Coherence针对这种理 解提供了应用层的数据共享缓冲,任何一个时候如果应用能够从这个数据缓冲里满足要求,则不会将请求发给数据源,从而极大地增强一般的瓶颈(数据)的扩展 性。
为了加强数据的写处理性能,Coherence还设计了延迟写的功能,就是应用的写会先缓存在Coherence的缓冲区,然后延迟写到数据 库里,为了减轻数据源的写压力,Coherence只把最近的更改写到数据源,比如一条数据被更改了多遍,则只有最后的更改会被提交到数据源。而且,如果 可能,多个SQL语句会被变成一个SQL语句批,一次提交给数据源,这样又极大地降低了对数据源的压力。
熟悉于数据库应用程序,参加过性能测试的有经验的朋友应该知道这非常多的场合,上述Coherence的特点刚好是对应了非常多的经常遇到的应用出现问题的场景。
一个典型的使用Coherence的架构图是:
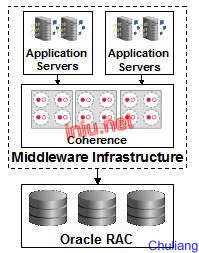
即Coherence被放在应用服务器和数据库服务器之间,从而解决通常应用架构里的瓶颈(数据瓶颈)来提高整个应用架构的可扩展性。
Coherence的第二个非常重要的特地是支持数据的分区处理,就是如果有N个处理节点,则每个节点只管理1/N的数据,当一个节点失效时,该节 点的数据会在剩下的节点均分,每个节点将管理1/(N-1)的数据。同样的,当一个节点增加进来时,则每一个节点都会分配一部分数据给新的节点,则最终每 个节点只管理1/(N+1)的数据。大家知道,一般应用服务器的集群都有只能缓冲共享2G java对象的缺点,而Coherence这种设计让Coherence能够处理非常多的数据,只需要通过增加节点的数量,就可以处理更多的数据。
如果安装了Coherence,则应用服务器不需要配置专有的服务器集群技术,因为Coherence*web模块提供了可用于处理http会话信 息在Coherence集群内共享的功能,当一个节点需要读取HTTP会话信息而发现自己没有该会话信息的时候,它会把请求同时发给所有的节点 (multicast),而当一个节点需要写HTTP会话信息的同时,它也会把写请求发给所有的节点,所以2个节点的处理和100个节点的处理都是一样 的。
Coherence的使用场景
Coherence可以用于下面图示的一些技术场景:
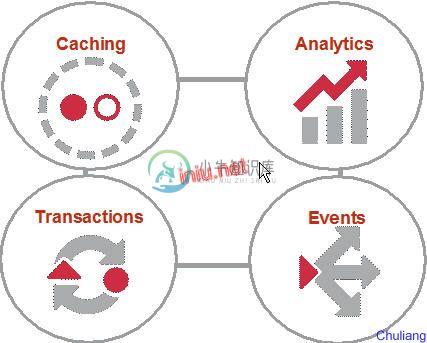
1. Caching: 正如Coherence的别名是Data Grid,Coherence在这种场景主要是被用于缓存数据源的数据,当应用需要数据时,直接从Coherence里面取得而不是从后台数据源取得。比 如用于缓存用户的个人设置信息。这种使用方式可以极大降低对后台数据源的压力,并且甚至当后台数据源不可用的时候也不影响系统的可用性。
2. Analytics:用于查询,从简单查询到复杂查询,比如用于查询金融交易系统的投资者持仓信息(非常密集的查询)。这种使用方式还可以使用多个节点的并发查询。
3. Transactions:在Coherence直接处理交易,可以在Coherence直接提交交易,从而得到极快的响应速度和高可扩展性。
4. Events:Coherence里可以使用事件驱动的架构,能够对事件做出实时的处理。比如在线游戏使用EDA架构处理“武器”,“装备”的买卖交易。
-
摘要:Oracle Coherence是一个企业级的分布式集群缓存框架。具有自管理,自恢复,高可用性,高扩展性等优良特点,在电信BOSS等项目中有很大的应用价值。本文对它的特点,架构,基本使用方法,JMX管理,调优等进行简要但快捷的介绍,并对于Hibernate的集成过程进行说明,为BOSS,CMP等移动项目提供一个的参考。 关键词:分布式缓存 Coherence 网上除了官方用户指南,关于Coh
-
转自:http://bbs.weblogicfans.net/thread-3488-1-1.html coherence Coherence是Oracle为了建立一种高可靠和高扩展集群计算的一个关键部件,集群指的是多于一个应用服务器参与到运算里。Coherence的主要用途是共享一个应用的对象(主要是java对象,比如Web应用的一个会话java对象)和数据(比如数据库数据,通过OR-MAP
-
一.Coherence是什么 Oracle官方网站的描述是:Coherence 在可靠的、高度可伸缩的对等集群协议之上提供了复制的、分布式的(分区的)数据管理和缓存服务。Coherence 不存在单点故障,当某台服务器无法操作或从网络断开时,它可以自动且透明地进行故障切换并重新分布它的集群化数据管理服务。当新服务器加入或故障服务器重 启时,它会自动加入集群,Coherence 会
-
tangosol-coherence.xml---提供了operational 和run-time设置,用来创建和配置cluster,通讯和数据管理服务。这个文件通常被称为operational deployment descriptor。 。。。。 tangosol-coherence-override-dev.xml---当Coherence启动在dev模式时,这个文件覆盖了tangosol-
-
两者都是Oracle的产品,Chris Jenkins的这段描述要言不烦,直击重点: These are very different technologies. Coherence is not specifically a cache, though it can be used as one in some circumstances. Coherence is a distributed
-
Cache lines The data in a cache is grouped into blocks called cache-lines, which are typically 64 or 128 bytes wide. These are the smallest units of memory that can be read from, or written to, main m
-
在大多数情况下通过put和get可以满足我们的需求,但是有时候我们并不知道key,在这种情况下,我们需要通过属性的条件查询来获取相应的entry. coherence允许我们通过QueryMap定义的接口执行指定过滤器的集合操作. public interface QueryMap extends Map { Set keySet(Filter
-
使用Coherence Query语言 本章介绍如何使用连贯性的查询语言(CohQL)互动与连贯性高速缓存。 CohQL是一个重量轻语法(SQL的传统),用于执行高速缓存操作上的连贯群集。语言可用于以编程方式或从一个命令行工具。 本章包含以下各节: 了解连贯性查询语言语法 使用命令行工具CohQL 大厦过滤器在Java程序 其他相干查询语言范例 注意事项:
-
原厂:说coherence可以实现session缓存,想试试. 理由:由于业务系统,需要实现会话复制功能,而业务系统用户较多经常发生单结点宕机出前台白屏。 经检查发现,结点业务较多,由于软件proxy无法同时出现大理session,资源 1、先安装一个JDK 2、修改cache-server.cmd添加set JAVA_HOME=C:\Oracle\Middleware\jdk160_
-
Memory coherence is an issue that affects the design of computer systems in which two or more processors or cores share a common area of memory.[1][2][3][4] In a uniprocessor system (whereby, in today
-
系统架构上用coherence来缓存用户session和一些数据字典的信息。用户在登陆的时候报超时,应用系统日志如下: <Error> <HTTP> <BEA-101020> <[ServletContext@754103289[app:EAR module:web path:/web spec-version:2.5]] Servlet failed with Exception co
-
1. 环境参数检查与设置环境参数检查与设置 具体请参考Oracle® Coherence Administrator's Guide的第6章:Performance Tuning。针对本次项目的AIX环境,建议调整下面这些参数: 1.1. AIX操作系统参数 1.1.1. SocketBuffer Sizes 默认的socket buffer sizes一般都比较小,Coherence会报下面
-
本文向大家介绍集群计算与网格计算之间的区别,包括了集群计算与网格计算之间的区别的使用技巧和注意事项,需要的朋友参考一下 集群计算 群集计算机是指目标是作为同一单元工作的相同类型计算机的网络。当资源匮乏的任务需要较高的计算能力或内存时,可以使用这种网络。将两个或更多相同类型的计算机组合在一起以组成集群并执行任务。 网格计算 网格计算是指由相同或不同类型的计算机组成的网络,其目标是提供一种环境,在该环
-
主版本和次版本升级 Seafile 在主版本和次版本中添加了新功能。有可能需要修改一些数据库表,或者需要更新搜素索引。一般来说升级集群包含以下步骤: 更新数据库 更新前端和后端节点上的符号链接以指向最新版本。 更新每个几点上的配置文件。 更新后端节点上的搜索索引。 一般来说,升级集群,您需要: 在一个前端节点上运行升级脚本(例如:./upgrade/upgrade_4_0_4_1.sh) 在其他所
-
按照Seafile 集群文档中给出的推荐架构,Seafile 集群需要使用一个分布式、高可用的数据库和缓存集群。在本文档中,我们给出一个在 3 台服务器上部署 MariaDB 和 Memcached 集群的案例。 硬件和操作系统需求 最少使用3台服务器部署来集群,每台机器都应该有: 2核、4GB内存。 1个SATA磁盘用来存储操作系统。 1个SATA磁盘用来存储MariaDB数据。也可以把 Mar
-
有没有一种方法可以暂停Dataproc群集,这样当我不积极运行火花外壳或火花提交作业时就不会收到账单?此链接处的群集管理说明:https://cloud.google.com/sdk/gcloud/reference/beta/dataproc/clusters/ 仅演示如何销毁群集,但我安装了spark cassandra连接器API。这是我创建每次都需要安装的映像的唯一选择吗?
-
Seafile 集群中,各seafile服务器节点之间数据共享的一个常用方法是使用NFS共享存储。在NFS上共享的对象应该只是文件,这里提供了一个关于如何共享和共享什么的教程。 如何配置NFS服务器和客户端超出了本wiki的范围,提供以下参考文献: Ubuntu: https://help.ubuntu.com/community/SettingUpNFSHowTo CentOS: http://
-
本系列文档介绍使用二进制部署最新 kubernetes v1.6.2 集群的所有步骤,而不是使用 kubeadm 等自动化方式来部署集群。 在部署的过程中,将详细列出各组件的启动参数,它们的含义和可能遇到的问题。 部署完成后,你将理解系统各组件的交互原理,进而能快速解决实际问题。 所以本文档主要适合于那些有一定 kubernetes 基础,想通过一步步部署的方式来学习和了解系统配置、运行原理的人。