
docker部署rabbitmq集群的实现方法

拉取rabbitmq management镜像
docker pull rabbitmq:3.7-rc-management
若不使用Rabbitmq的management功能,可以拉取镜像:rabbitmq:3.7-rc
参考: https://hub.docker.com/_/rabbitmq/
创建网络
创建rabbitmq私有网络
# docker network create rabbitmqnet # docker network ls NETWORK ID NAME DRIVER SCOPE 65b44ea8847c rabbitmqnet bridge local ...
创建节点
通过docker命令创建三个Rabbitmq nodes;
注意这里使用相同的 RABBITMQ_ERLANG_COOKIE 值
# docker run -d \ --name=rabbitmq1 \ -p 5672:5672 \ -p 15672:15672 \ -e RABBITMQ_NODENAME=rabbitmq1 \ -e RABBITMQ_ERLANG_COOKIE='YZSDHWMFSMKEMBDHSGGZ' \ -h rabbitmq1 \ --net=rabbitmqnet \ rabbitmq:3.7-rc-management # docker run -d \ --name=rabbitmq2 \ -p 5673:5672 \ -p 15673:15672 \ -e RABBITMQ_NODENAME=rabbitmq2 \ -e RABBITMQ_ERLANG_COOKIE='YZSDHWMFSMKEMBDHSGGZ' \ -h rabbitmq2 \ --net=rabbitmqnet \ rabbitmq:3.7-rc-management # docker run -d \ --name=rabbitmq3 \ -p 5674:5672 \ -p 15674:15672 \ -e RABBITMQ_NODENAME=rabbitmq3 \ -e RABBITMQ_ERLANG_COOKIE='YZSDHWMFSMKEMBDHSGGZ' \ -h rabbitmq3 \ --net=rabbitmqnet \ rabbitmq:3.7-rc-management
组建rabbitmq集群
登陆Rabbitmq的后两个节点,执行命令加入第一个Rabbitmq节点集群
### Disk Node # docker exec rabbitmq2 bash -c \ "rabbitmqctl stop_app && \ rabbitmqctl reset && \ rabbitmqctl join_cluster rabbitmq1@rabbitmq1 && \ rabbitmqctl start_app" ### Ram Node # docker exec rabbitmq3 bash -c \ "rabbitmqctl stop_app && \ rabbitmqctl reset && \ rabbitmqctl join_cluster --ram rabbitmq1@rabbitmq1 && \ rabbitmqctl start_app"
退出集群
# docker exec rabbitmq3 bash -c \ "rabbitmqctl stop_app && \ rabbitmqctl reset && \ rabbitmqctl start_app"
拉取haproxy镜像
拉取haproxy镜像
# docker pull haproxy
启动haproxy
# cat haproxy-create.sh #! /bin/bash docker run -d \ --name rabbitmq-haproxy \ -p 1080:80 -p 5677:5677 -p 8001:8001 \ --net=rabbitmqnet \ -v /root/rabbitmq/haproxy-etc:/usr/local/etc/haproxy:ro \ haproxy:latest
haproxy的配置文件如下:
root@node0:~/rabbitmq# cat haproxy-etc/haproxy.cfg # Simple configuration for an HTTP proxy listening on port 80 on all # interfaces and forwarding requests to a single backend "servers" with a # single server "server1" listening on 127.0.0.1:8000 global daemon maxconn 256 defaults mode http timeout connect 5000ms timeout client 5000ms timeout server 5000ms listen rabbitmq_cluster bind 0.0.0.0:5677 option tcplog mode tcp balance leastconn server rabbit1 rabbitmq1:5672 check inter 2s rise 2 fall 3 server rabbit2 rabbitmq2:5672 check inter 2s rise 2 fall 3 server rabbit3 rabbitmq3:5672 check inter 2s rise 2 fall 3 listen http_front bind 0.0.0.0:80 stats uri /haproxy?stats listen rabbitmq_admin bind 0.0.0.0:8001 server rabbit1 rabbitmq1:15672 server rabbit2 rabbitmq2:15672 server rabbit3 rabbitmq3:15672
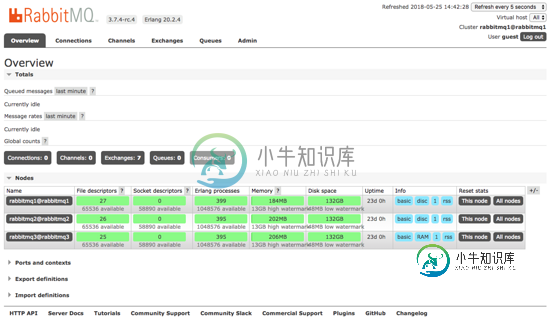
启动haproxy后,可以通过haproxy来访问rabbitmq集群:http://external-ip:8001
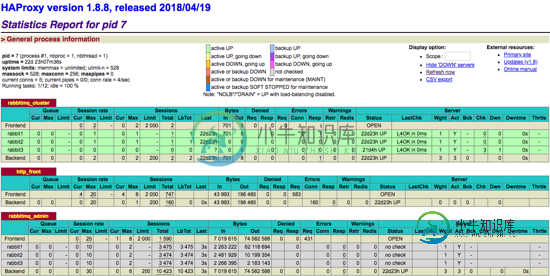
获取haproxy的状态:http://external-ip:1080/haproxy?stats
rabbitmq exporter部署
要收集rabbitmq的metrics给prometheus使用的话,可以使用开源的rabbitmq-exporter
参考如下:
https://html" target="_blank">github.com/kbudde/rabbitmq_exporter
https://hub.docker.com/r/kbudde/rabbitmq-exporter/
拉取镜像
# docker pull kbudde/rabbitmq-exporter
启动rabbitmq实例
# docker run -d --name=rabbitmq1 -p 5672:5672 -p 15672:15672 -e RABBITMQ_NODENAME=rabbitmq1 -e RABBITMQ_ERLANG_COOKIE='YZSDHWMFSMKEMBDHSGGZ' -h rabbitmq1 --net=rabbitmqnet -p 9090:9090 rabbitmq:3.7-rc-management
开启9090端口,这个是rabbitmq exporter的默认PUBLISH_PORT
启动rabbitmq exporter实例
# docker run -d --net=container:rabbitmq1 kbudde/rabbitmq-exporter
获取rabbitmq的metrics
# wget http://localhost:9090/metrics
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
本文向大家介绍docker-compose部署zk+kafka+storm集群的实现,包括了docker-compose部署zk+kafka+storm集群的实现的使用技巧和注意事项,需要的朋友参考一下 集群部署总览 172.22.12.20 172.22.12.21 172.22.12.22 172.22.12.23 172.22.12.24 zoo1:2181 zoo2:2182 zoo3:2
-
本文向大家介绍使用docker快速部署Elasticsearch集群的方法,包括了使用docker快速部署Elasticsearch集群的方法的使用技巧和注意事项,需要的朋友参考一下 本文将使用Docker容器(使用docker-compose编排)快速部署Elasticsearch 集群,可用于开发环境(单机多实例)或生产环境部署。 注意,6.x版本已经不能通过 -Epath.config 参数
-
本文向大家介绍docker搭建rabbitmq集群环境的方法,包括了docker搭建rabbitmq集群环境的方法的使用技巧和注意事项,需要的朋友参考一下 本文主要讲述如何用docker搭建rabbitmq的集群。分享给大家,希望此文章对各位有所帮助。 下载镜像 采用bijukunjummen该镜像。 运行 启动集群 默认启动了三个节点 查看 访问 http://192.168.99.100:15
-
主版本和次版本升级 Seafile 在主版本和次版本中添加了新功能。有可能需要修改一些数据库表,或者需要更新搜素索引。一般来说升级集群包含以下步骤: 更新数据库 更新前端和后端节点上的符号链接以指向最新版本。 更新每个几点上的配置文件。 更新后端节点上的搜索索引。 一般来说,升级集群,您需要: 在一个前端节点上运行升级脚本(例如:./upgrade/upgrade_4_0_4_1.sh) 在其他所
-
按照Seafile 集群文档中给出的推荐架构,Seafile 集群需要使用一个分布式、高可用的数据库和缓存集群。在本文档中,我们给出一个在 3 台服务器上部署 MariaDB 和 Memcached 集群的案例。 硬件和操作系统需求 最少使用3台服务器部署来集群,每台机器都应该有: 2核、4GB内存。 1个SATA磁盘用来存储操作系统。 1个SATA磁盘用来存储MariaDB数据。也可以把 Mar
-
本系列文档介绍使用二进制部署最新 kubernetes v1.6.2 集群的所有步骤,而不是使用 kubeadm 等自动化方式来部署集群。 在部署的过程中,将详细列出各组件的启动参数,它们的含义和可能遇到的问题。 部署完成后,你将理解系统各组件的交互原理,进而能快速解决实际问题。 所以本文档主要适合于那些有一定 kubernetes 基础,想通过一步步部署的方式来学习和了解系统配置、运行原理的人。