
MatchZoo 是中科院开源的一个文本匹配工具包。 它着重于让大家更直观地了解深度文本匹配模型的设计、对比和共享。
架构
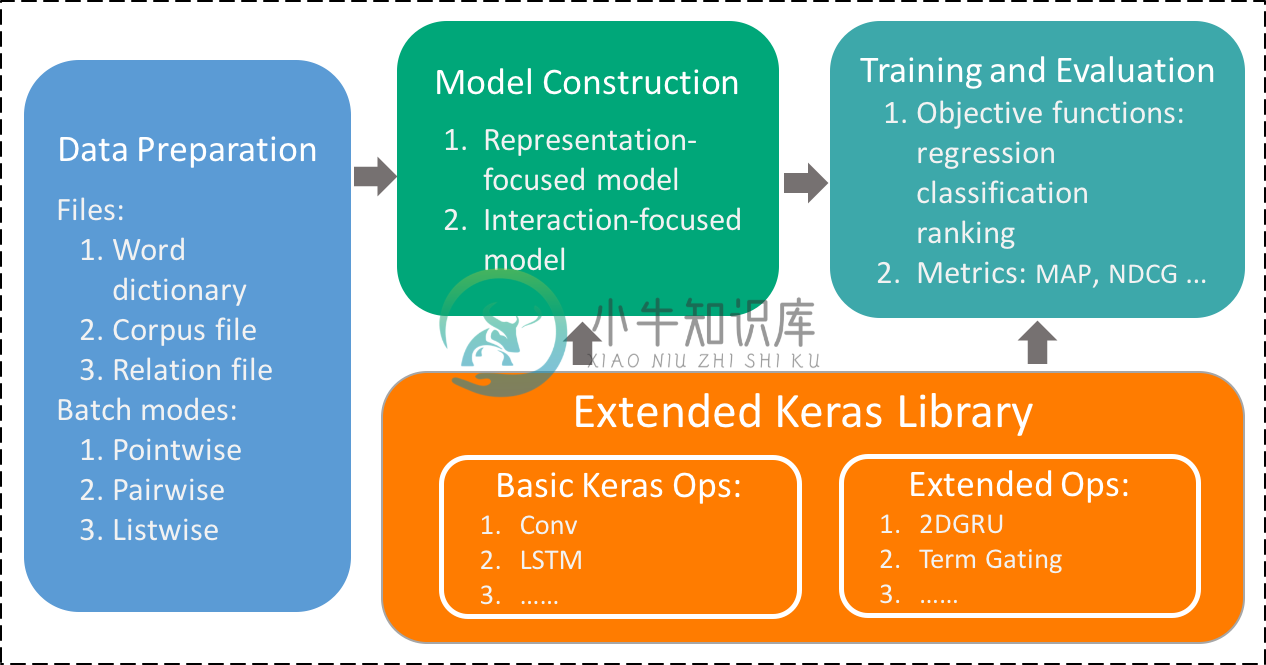
MatchZoo 有三个主要模块,分别为数据预处理、模型构建 和 训练与评测。它基于 Keras 开发,支持 TensorFlow、CNTK 及 Theano,并能在 CPU 与 GPU 上无缝运行。
基准测试
下面,以 WikiQA 数据集来举例说明 MatchZoo 的用法。
以 DRMM 为例,运行:
python main.py --phase train --model_file models/wikiqa_config/drmm_wikiqa.config
在测试时可运行:
python main.py --phase predict --model_file models/wikiqa_config/drmm_wikiqa.config
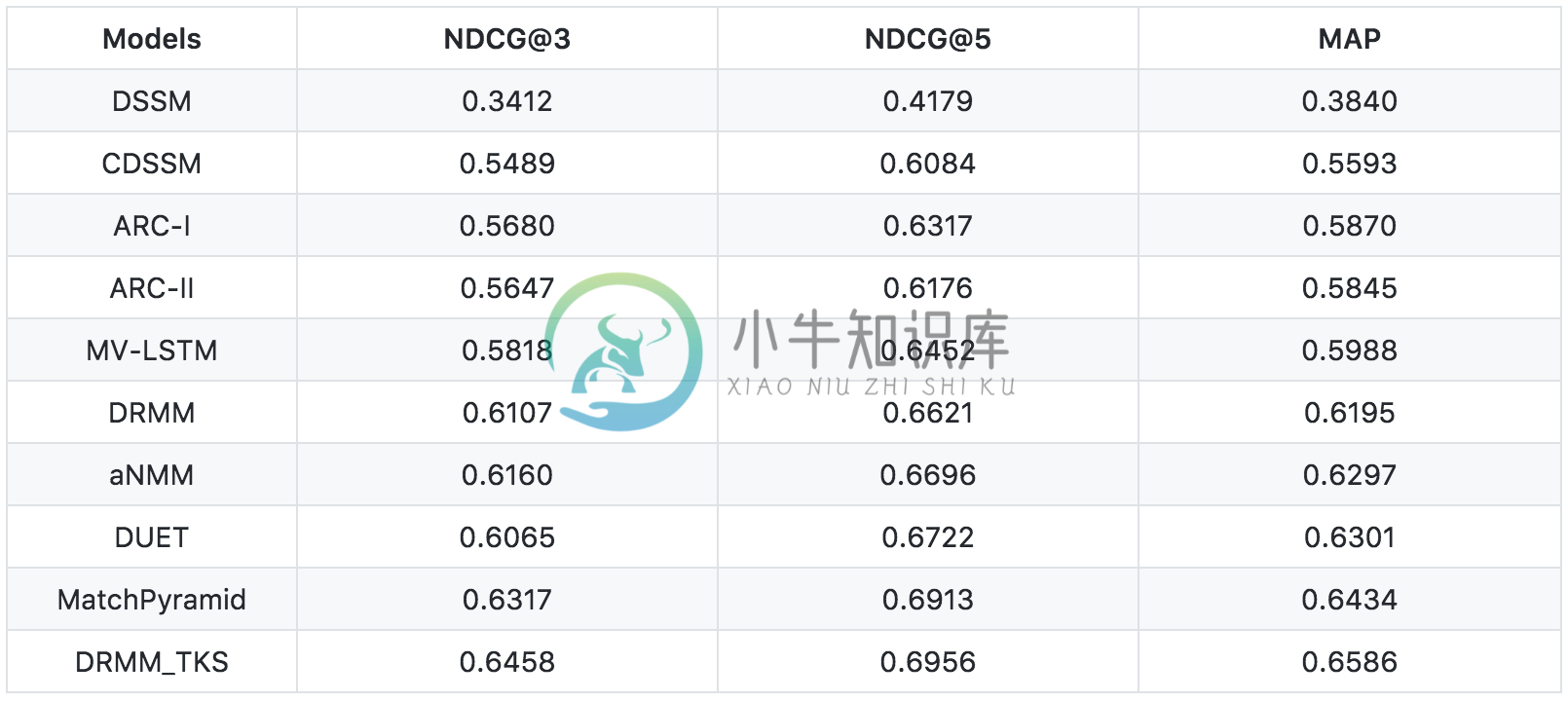
十个模型的比较结果如下:
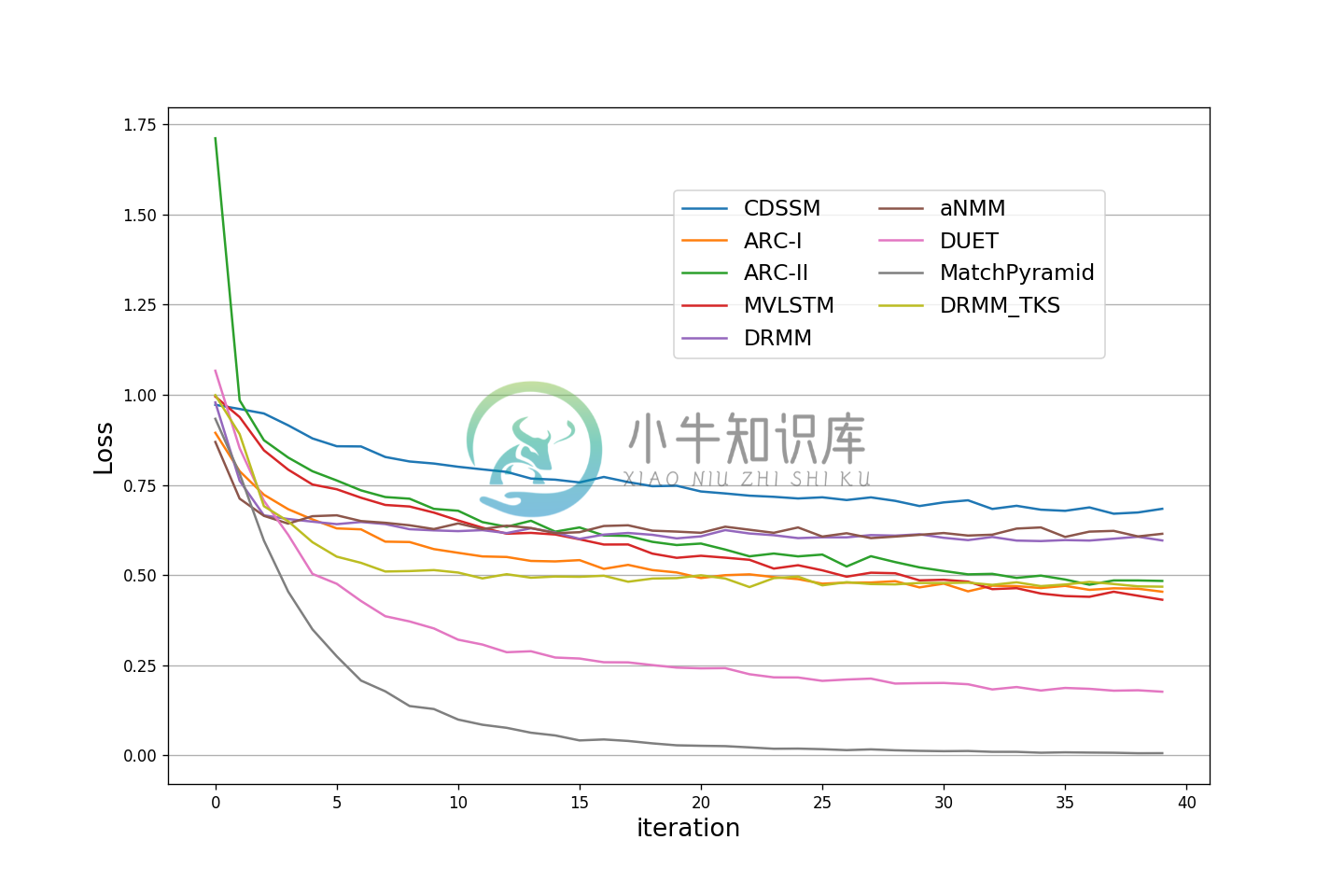
loss 训练曲线图如下:
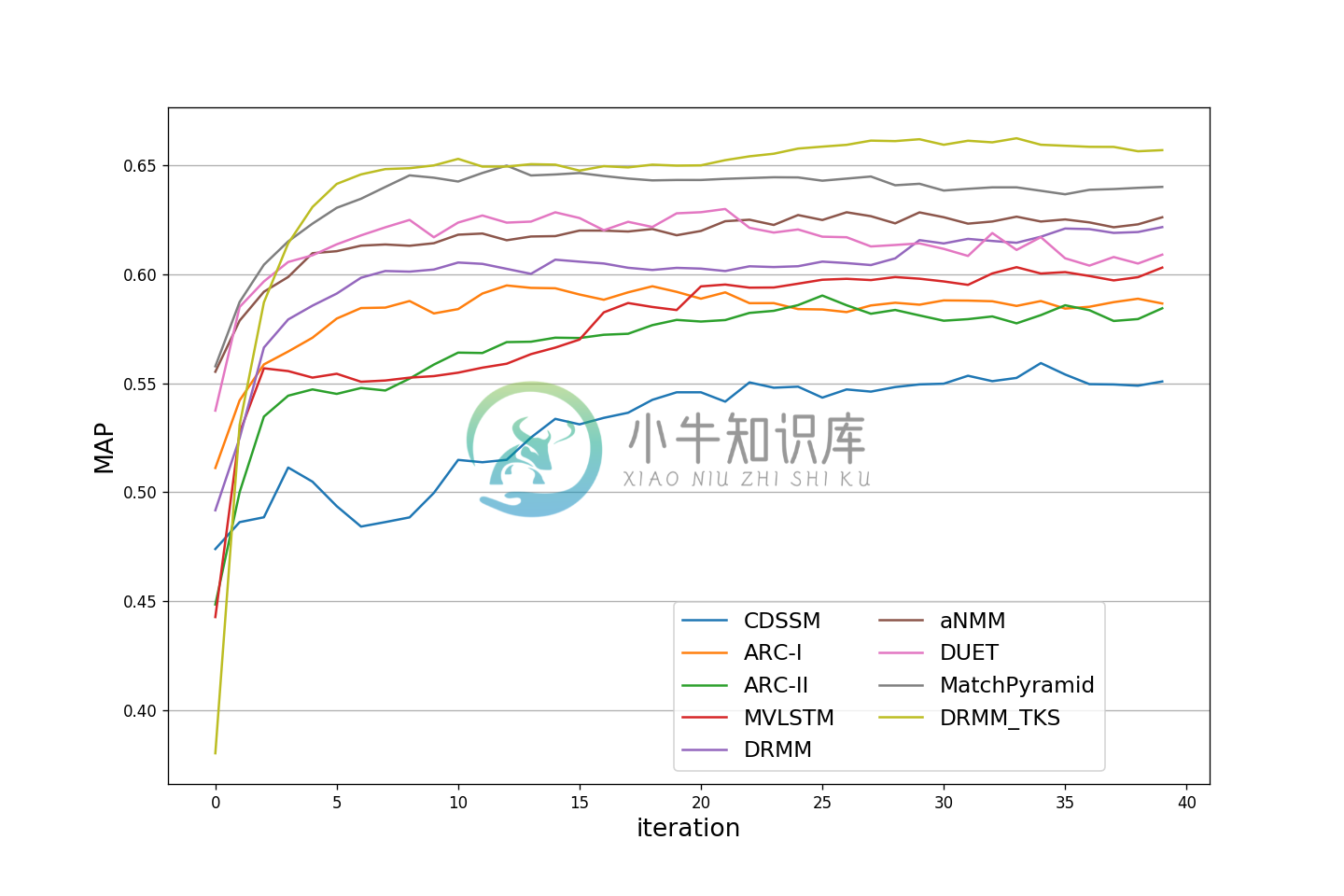
MAP 性能测试曲线图如下:
-
简介 最近在调研文本相似度计算方法的时候,突然看到有关MatchZoo有关的内容,MatchZoo 是一个通用的文本匹配工具包,它旨在方便大家快速的实现、比较、以及分享最新的深度文本匹配模型,貌似比较好玩,于是乎,看了一下MatchZoo的使用方法。在此简单记录一下我的使用过程,运行totorials里面的示例代码。如果之前没接触过MatchZoo,直接看github中README.md中的示例代
-
中文适配需要参考源代码,同时修改源码,可以分两种情况使用 1、下载源码修改然后当项目运行, 2、pip install matchzoo 参考源码把中文需要改的地方都重新实现一遍,代码中调用matchzoo使用。 一、修改源代码 参考tutorials中的init 1、首先修改获取数据的文件,添加文件matchzoo/datasets/chinese_qa/load_data.py """Wiki
-
mzcn 中文版本的matchzoo-py 本库包是基于matchzoo-py的库包做的二次开发开源项目,MatchZoo 是一个通用的文本匹配工具包,它旨在方便大家快速的实现、比较、以及分享最新的深度文本匹配模型。 由于matchzoo-py面向英文预处理较为容易,中文处理则需要进行一定的预处理。为此本人在借鉴学习他人成功的基础上,改进了matchzoo-py包,开发mzcn库包。 mzcn库包
-
MatchZoo是封装了一系列文本匹配的框架包含以下算法: 官网地址:https://github.com/kouunn/MatchZoo Model Detail: 1. DRMM this model is an implementation of A Deep Relevance Matching Model for Ad-hoc Retrieval. model file: models/
-
本人在这里已经给出了MatchZoo的一个简单上手,这一次我会给出为模型自动调参的方法。 这一次使用的变量,和简单上手中的变量是一样的,所以我都是直接复制,并删掉一些不需要的地方。 加载数据: train_pack_processed = preprocessor.fit_transform(train) # 其实就是做了一个字符转id操作,所以对于中文文本,不需要分词 dev_pack_pro
-
和师弟联手利用了matchzoo框架搭建了11套文本匹配模型,作为一个新框架的出现,以后会在我们的github上对这个框架逐渐进行拓展。 我们做的作品的github地址是: https://github.com/yingdajun/matchzooExample- 我们搭建了BiMPM、ConvKNRM、DenseBaseline-model、DRMMTKS.DUET、ESIM、HBMP、KNRM
-
从matchzoo中反向推导深度学习文本匹配模型,以后会逐渐增加新模型,就当是练手了。 有源码,有数据,有导出的模型图片,有模型参数结构,可以方便下载。 github地址如下: https://github.com/yingdajun/ReverseMatchZoo
-
python3函数注解和类型注解 https://www.zhihu.com/tardis/sogou/art/37239021 Python中的.pkl文件 https://blog.csdn.net/BockSong/article/details/81234058
-
本文向大家介绍OCaml 否定范式:深度模式匹配,包括了OCaml 否定范式:深度模式匹配的使用技巧和注意事项,需要的朋友参考一下 示例 模式匹配允许解构复杂的值,并且绝不限于值表示的“最外部”级别。为了说明这一点,我们实现了将布尔表达式转换为布尔表达式的函数,其中所有否定都仅存在于原子上,即所谓的否定范式和谓词可识别这种形式的表达式: 我们定义布尔表达式的类型,其原子由字符串标识为 让我们首先定
-
类似定位器参数,文本模式是另一种常用的 Selenium 命令参数。需要使用文本模式的命令,例如:verifyTextPresent, verifyTitle, verifyAlert, assertConfirmation, verifyText, verifyPrompt。上面已经提到,LinkText 定位器可使用文本模式。文本模式使用特殊字符来模糊匹配预期的文本,而不必准确的描述该文本。
-
dir=“某物”\temp。 我是新来的,任何帮助都很感激。我认为这是字符转义…但我不确定,我想使用正则表达式,但我想我会遇到同样的问题。 预期 C:\\users\\admin\\appdata\\local\\ dir=c:\\users\\admin\\appdata\\local\\temp
-
我尝试为配置文件编写Xtext BNF(已知扩展名为) 例如,我想成功地解析 我的问题是匹配属性值(在“=”右边)。 如果属性与终端匹配(例如),则我当前的语法有效。 我不知道如何概括语法以匹配任何文本(例如)。 我当然需要引入一个新的终端属性:name=ID (':' | '=') value=TEXT ';'?; 问题是:我应该如何定义这个终端? 我试过了 >
-
我和ElasticSearch一起工作。当我执行此查询时: 我得到了我想要的(所有的结果,其中有参考黑莓,但不是Q10)。 但是,我想限制搜索的字段只限于“title”字段。例如,_source文档有标题、正文、标签等,我只想搜索标题。ElasticSearch“匹配”似乎很适合我... 虽然这只成功地搜索了标题,但它仍然返回标题中带有Q10的结果,这与上面的搜索不同。 我正在看比赛文档,但似乎不
-
问题 在文本 text 中查找字符串 str 的位置(比如文本编辑器 VIM 中查找某个字符串的场景,设 text 长度为n, str 长度为 m ,该场景满足 n gt m )。 解法 假设字符数组下标从 1 开始。简单匹配的方法是对于 text[1 cdots n] ,从第 1 个字符开始,依次比较 text[i+1 cdots i+m] 是否与 str[1 cdots m] 相等。若相等则