
Longhorn 提供了一种简单、轻量、极适用于容器和 Kubernetes 的持久化存储解决方案,同时极大地简化了用户部署、使用和管理的工作,从而帮助团队更好地管理Kubernetes中的有状态工作负载。
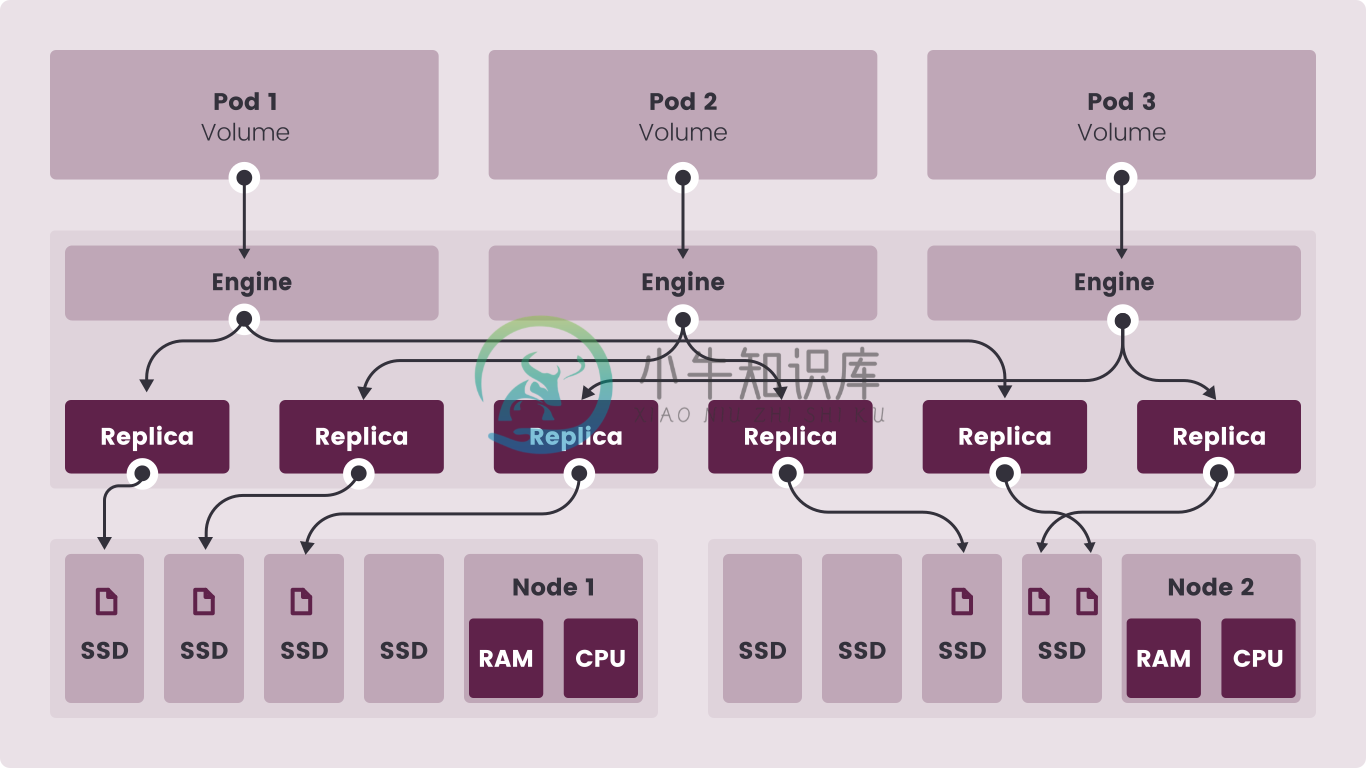
主要功能
Kubernetes的高可用持久化存储
过去,将复制的存储添加到Kubernetes集群中对于ITOps和DevOps而言是一件极其困难的事情。因此,许多非云托管的 Kubernetes 集群不支持持久化存储,另一方面,外部存储阵列通常是不可移植且费用高昂的。
Longhorn 提供了简单、易于部署和升级的100% 开源云原生持久化块存储解决方案,大大降低了采用open core或专有软件的成本。
简单的增量快照和备份
Longhorn内置的增量快照和备份功能确保了数据卷在集群内部及外部的安全性。
用户通过简洁直观的UI与Longhorn进行交互,极大地简化了Kubernetes集群中持久化存储卷的计划备份。
跨集群灾难恢复
外部复制解决方案将通过重新复制整个数据存储区从磁盘故障中恢复,一般需要几天的时间。在恢复期间,集群性能大大减弱,而且具有更高的发生故障的风险。
Longhorn可以帮助您最大程度地控制粒度,轻松在另一个Kubernetes集群中创建灾难恢复卷,并在发生紧急情况时进行故障转移。
如果主集群出现故障,则可以使用已定义的PRO和RTO在DR集群中快速启动应用程序。
-
Longhorn配置参数详解 longhorn配置参数都在longhorn-default-setting的configmap里,之前分布式块存储Longhorn简介写过,示例如下: apiVersion: v1 kind: ConfigMap metadata: name: longhorn-default-setting namespace: longhorn-system data:
-
快照 手动快照 snapshot 是 Kubernetes Volume 在任何给定时间点的状态。 要创建现有集群的快照, 在 Longhorn UI 的顶部导航栏中,单击 Volume。 单击要为其创建快照的卷的名称。这会导致卷详细信息页面。 在Snapshots and Backups板块中,单击 Take Snapshot 按钮即可创建快照。 创建快照后,您将在卷头(Volume Head)
-
前言 在之前,longhorn的部署是不涉及k8s.gcr.io的镜像的,但是在现在新版本当中,csi相关的镜像都是直接使用k8s.gcr.io中的镜像. 淡定 不要慌,这时候可以使用短域名镜像代理lank8s.cn来代替k8s.gcr.io.只需要将k8s.gcr.io修改为lank8s.cn就可以了,其他都不变. 部署 按照官网文档[1]一步一步做,走起. 1. helm repo add l
-
本文向大家介绍Java分布式session存储解决方案图解,包括了Java分布式session存储解决方案图解的使用技巧和注意事项,需要的朋友参考一下 前言 本文主要探讨集群后不同Web服务器获取Session数据的问题解决方案。 Session Stick Session Stick 方案即将客户端的每次请求都转发至同一台服务器,这就需要负载均衡器能够根据每次请求的会话标识(SessionId)
-
一面 11.1 分布式存储 阿里天池比赛,问了一些模块的优化 问存储项目 问TinyKV 项目 操作系统:cpu cache,false sharing,gdb C++:移动语义,std::map,rbtree和b+tree区别。 perf 观察程序性能 算法题:二叉树的路径和 二面 11.2 leader 面 开局先选方向:DB,分布式,操作系统,体系结构,计算机网络。选了分布式,狂问raft
-
问题内容: 我的任务是为可大规模扩展的分布式共享内存(DSM)应用程序构建原型。原型仅用作概念验证,但我想通过选择稍后在实际解决方案中使用的组件来最有效地利用我的时间。 该解决方案的目的是获取来自外部源的数据输入,将其搅动并使结果可用于许多前端。这些“前端”将仅从缓存中获取数据并提供服务,而无需额外的处理。该数据的前端命中量实际上可以是每秒数百万。 数据本身非常不稳定。它可以(并且确实)快速变化。
-
问题内容: 我们的生产Web服务器有一台运行Windows Server 2003的服务器。我们的网站具有不同的模块,每个模块都在其自己的应用程序池中运行。由于每个模块都有自己的缓存,而且经常有多个模块缓存相同的项目,因此这使缓存有点问题。问题是,当在一个模块中更改了缓存中的项目时,无法轻松地刷新缓存同一项目的另一个模块。 我们的网站是用ASP.NET 4.0编写的,我们使用标准的HttpRunt
-
全程一小时 1.关于项目询问…… 2.C++: 忘了有啥了,应该都是常见的 4.分布式: ACID是什么 CAP是什么 RAFT如是实现投票? 经典的超过半数投票…… Zookeeper如何避免脑裂? 答:采用2N+1个 replica。 反问:如果有一个宕机了就不能了吗? 答:不能,要么手动再宕机一个节点,要么加上一个replica。不然容易出问题 好像认可了我的答案…… 分布式系统中如果我向r
-
主要内容:1.2PC,2.三阶段提交(3PC),3.补偿事务(TCC),4.本地消息表,5.消息事务,6.最大努力通知,7.Sagas 事务模型1.2PC 两阶段提交 mysql是通过日志系统完成事务的。就是两阶段提交:undolog和binlog的两阶段提交。 两阶段协议可以用于单机集中式系统,由事务管理器协调多个资源管理器;也可以用于分布式系统,由一个全局的事务管理器协调各个子系统的局部事务管理器完成两阶段提交。 第一阶段:投票阶段 1.协调者写命令进写入日志 2.协调者发一个prepare
-
主要内容:1.UUID,2.数据库自增Id,3.基于数据库集群模式,4.基于数据库的号段模式,5.Redis,6.Snowflake,7.百度(uid-generator),8.Leaf,9.TinyId生成方式: 1.UUID 2.数据库自增ID 3.数据库多主模式 4.号段模式 5.Redis 6.雪花算法(SnowFlake) 7.滴滴出品(TinyID) 8.百度 (Uidgenerator) 9.美团(Leaf) 1.UUID UUID的生成简单到只有一行代码,输出结果 c2b8c2b
-
之前的秋招面经:深信服 Go 开发面经(已 offer) bg:专升本+ACM银牌+三个项目(一个毕设的KV分离LSM-Tree,一个6824的分布式KV,一个OJ) 某小厂,存储方向技术积累还不错,避免定位就不写具体名字了。自己也一直比较憧憬做 infra 吧,不想写 CRUD 业务,所以就投了。面试内容都是事后回忆,可能有遗漏或记错的 一面 50min 自我介绍 项目实现细节、设计考量、优化(