
falcon-log-agent 简介
falcon-log-agent 是一个开源版的日志采集工具,旨在从流式的日志中抓取、统计日志中的特征信息。
获取的特征信息,与开源版 Open-Falcon 监控系统打通。可用于业务指标的衡量、也可用于稳定性的建设。
特性
准确可依赖:历经滴滴线上业务近一年考验,统计准确性高。
性能高、资源消耗可控:性能优化程度高,单核单策略可支撑日志分析:20W条/秒
接入成本低:外挂式采集,只需要标准化日志即可;输出数据直接对接 open-falcon。
附:滴滴公司 agent 升级前后资源占用对比图 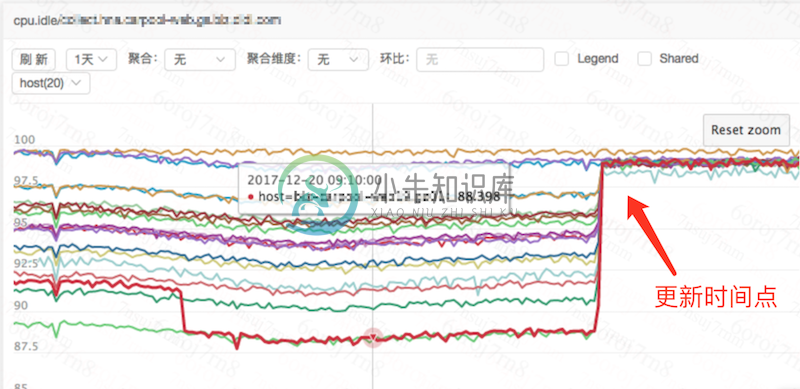
什么是日志采集
日志采集,是一种外挂式的采集。通过读取进程打印的日志,来进行监控数据的采集与汇聚计算。
falcon-log-agent如何工作
本 agent 即日志采集场景下的实时计算。实时读取文件内容,实时计算,将计算结果直接推送至falcon。
限定条件
要求日志必须包含时间:不包含时间的日志,只能根据当前时间统计日志条数,结果非常不准确。
不支持文件软链
日志时间必须有序:为了应对日志延迟落盘等,agent会根据日志的时间来判断某一周期的数据是否采集完成,如果日志时间顺序错乱,可能导致采集不准。
-
背景介绍 公司在open-falcon项目的agent模块提供了一个方法,方法里的主要逻辑是通过内置的sys.CmdOutBytes函数,调用linux的sh -c命令。 http.HandleFunc("/run", func(w http.ResponseWriter, r *http.Request) { if r.ContentLength == 0 { http.Error(w
-
目的 部署 falcon-api api 提供一系列接口 提供了用户,模板,组件, agent 间的交互 版本修改 modules/api/config/g.go const ( VERSION = "20200818" ) 编译 # make api go build -o bin/api/falcon-api ./modules/api 创建目录 mkdir /apps/s
-
项目地址 代码地址 https://github.com/ning1875/falcon-plus/tree/master/modules/agent 前言 在我们日常运维/运维开发工作中各种系统主要分为两大流派 本文主要讨论下有agent侧一些注意事项 客户端服务端的C/S架构 优点 c/s架构相比于基于ssh的并发和吞吐量要高的多 利用agent可做的事情很多以及更精准的控制 缺点 功能更新需
-
总结:aggregator聚合器就是从falcon_portal.cluster表中取出用户在页面上配置的表达式,然后解析后,通过api拿到对应机器组的所有机器,通过api查询graph数据算出一个值重新打回transfer作为一个新的点。 定时从db中拿出所有的聚合器配置放到一个map中 第一次启动时遍历聚合器map生成workers map 这两个map的key都是id+updatetime
-
OpenFalcon-SuitAgent 项目地址:github 版本说明 本系统版本划分如下 alpha:内部测试版(不建议使用于生产环境) beta:公开测试版(不建议使用于生产环境) final:最终正式版(可用于生产环境) 当前版本请查看pom.xml信息。 使用之前 此系统是和OpenFalcon监控系统一起使用,是为了更方便的进行运维监控。若不了解,可以先点击链接去OpenFalcon
-
生产环境部署完falcon的前后端服务,后面就要部署一个agent来收集监控数据 部署过程 一、修改agent配置文件 1.“hostname”: 此处endpoint名称,默认为空,会自动识别为hostname 2.“heartbeat"段中"addr”: server端的falcon-hbs服务地址,如果没修改过就是6030,现在agent和server在同一台机器所以用127.0.0.1 3
-
日志采集配置 在应用详情页中间有一个叫作“日志采集”的模块 点击右边的“添加”按钮,在弹出的对话框中选择日志的路径及正则规则 文件路径:你日志文件的位置 日志规则:如果没有特殊需求的话默认就好 提交后服务会自动重启动。 日志采集 如果配置了上面采集器,那么它会向服务所在的Pod注入一个Filebeat采集器对应用服务的业务日志进行采集。把采集到的日志入到kafka集群,然后logstash进行消息
-
DoitPHP所提供的Log类主要用于日志处理。当主配置文件中开启日记记录功能时(日记功能开启,Debug调试功能关闭),若程序运行异常时会在logs目录内生成log日志文件,这样便于监控程序运行。Log类只提供两个类方法write()和show()。 类方法使用说明: 1、write($message, $level = 'Error', $logFileName = null) 日志写入操作
-
NSLog方法 为了打印日志,我们使用Objective-C编程语言中的NSLog方法,我们在Hello World示例中使用了该方法。 让我们看一下打印“Hello World”字样的简单代码 - #import <Foundation/Foundation.h> int main() { NSLog(@"Hello, World! \n"); return 0; } 现在,当我们
-
log4j API提供org.apache.log4j.jdbc.JDBCAppender对象,该对象可以将日志记录信息放在指定的数据库中。 JDBCAppender配置 属性 描述 bufferSize 设置缓冲区大小。 默认大小为1。 driver 将驱动程序类设置为指定的字符串。 如果未指定驱动程序类,则默认为sun.jdbc.odbc.JdbcOdbcDriver 。 layout 设置要
-
Apache log4j提供了各种Layout对象,每个对象都可以根据各种布局格式化日志记录数据。 还可以创建一个Layout对象,以特定于应用程序的方式格式化日志记录数据。 所有Layout对象都从Appender对象接收LoggingEvent对象。 然后,Layout对象从LoggingEvent中检索消息参数,并应用适当的ObjectRenderer来获取消息的String表示形式。 布局
-
由来 准确的说,Hutool-log只是一个日志的通用门面,功能类似于Slf4j。既然像Slf4j这种门面框架已经非常完善,为何还要自己做一个门面呢?下面我列举实践中遇到的一些问题: 已有门面存在问题 log对象创建比较复杂 很多时候我们为了在类中加日志不得不写一行,而且还要去手动改XXX这个类名 private static final Logger log = LoggerFactory.ge