
Data Pipeline 是一个Java的数据转换工具包,主要的功能包括:
* 读: CSV, fixed-width, Excel, database, weblogs, custom
* 写: CSV, fixed-width, Excel, database, PDF, Word, XML, custom
* 操作: validate, filter, sort, lookup, 去除重复数据, convert, throttle, calculate, custom, and more
* 运行时表达式过滤器、数据验证以及公式计算
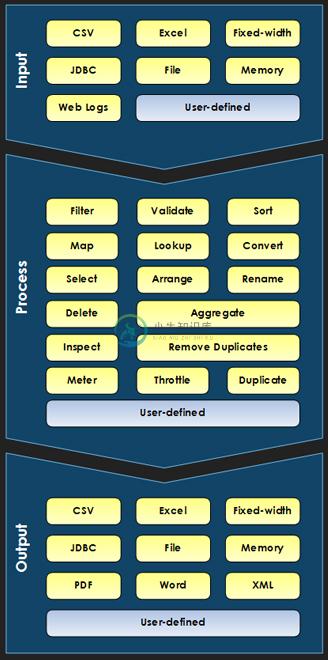
典型的应用场景包括:
1. 读取 CSV 文件
2. 删除重复的记录
3. 添加计算列
4. 删除无用的列
5. 数据保存到数据库
代码示例:
DataReader reader = new CSVReader(new File("credit-balance.csv"))
.setFieldNamesInFirstRow(true);
// Use only the "Rating" and "CreditLimit" fields in duplicate test
reader = new RemoveDuplicatesReader(reader, new FieldList("Rating", "CreditLimit"));
// Add AvailableCredit field, remove "CreditLimit", "Balance" fields
reader = new TransformingReader(reader)
.add(new SetCalculatedField("AvailableCredit", "parseDouble(CreditLimit) - parseDouble(Balance)"))
.add(new ExcludeFields("CreditLimit", "Balance"));
DataWriter writer = new JdbcWriter(getJdbcConnection(), "dp_credit_balance")
.setAutoCloseConnection(true);
JobTemplate.DEFAULT.transfer(reader, writer);-
用shell脚本生成data pipeline的日志 在数据处理的data pipeline通常主要的数据处理工作都是用shell脚本批量完成. 特别有必要生成各被试数据处理日志文件以便pipeline的调试, 优化, 数据处理的追踪. Python提供了一个日志记录工具包: loggings, 其实shell脚本也可以方便地生成日志. 用echo命令 用echo将需要记录的内容输出, 并通过管道
-
数据管道(data pipeline)和ETL管道(ETL pipeline)的概念和区别 ETL管道:将数据从系统中抽取出来加载到数据仓库或者数据库中,再对其进行转换,这个过程就是ETL管道。 数据管道是比ETL管道更通用的概念,只要是实现系统之间数据迁移的处理过程就可以称为数据管道。 数据管道并不一定以将数据加载到数据库或数据仓库为结束,举个例子,它也可以通过webhook的方式来触发其他业务
-
数据管道与ETL管道,这两个词的意义是相近的,差别比较微小,有时候很多人会混用。 ETL管道,描述的是一组进程,实现将数据从一个系统抽取出来,经过转换,最终再加载到其他数据库或数据仓库中。 数据管道,是一个比ETL管道更加通用的术语,只要是实现系统之间的数据迁移的处理过程,都可以使用这个词来代表。迁移过程中可能存在着数据转换。 ETL管道,一般描述的是在批处理中使用的管道,例如:某个管道运行频率是
-
我的经理在AWS中为我分配了一个IAM角色,我正在尝试建立一个Amazon数据管道。在尝试激活管道时,我反复遇到如下权限问题和授权问题。 警告:验证角色“DataPipelineDefaultRole”时出错。错误:状态代码:403,AWS服务:AmazonIdentityManagement,AWS请求ID:fbf1935a-bcf1-11e3-82d4-cd47aac2f228,AWS错误代码
-
我有一个DynamoDB表,存储1Gb的数据。RCU和WCU各为1000。我设置了一个数据管道,将这1GB的数据导出到s3。整个1GB的数据在分区中导出到s3。我的问题是什么决定了这些分区的数量和大小?
-
我是AWS DataPipeline的新手。我创建了一个成功的datapipeline来将所有内容从RDS拉到S3 bucket。一切都管用。我在S3 bucket中看到了我的。csv文件。但我在表中存储西班牙语名称,在csv中,我看到的是“García”而不是“García”
-
我已经创建了一个AWS Datapipeline来将数据从RDS MySQL数据库移到S3,但我出现了一个getting Lower错误。请帮忙 Amazonaws.datapipeline.connector.sqlinputConnector:查询字符串为:select*from db.emp 02 2020年5月12日12:23:52,091[ERROR](taskrunnerservice
-
我有很多DynamoDB表要在数据管道中设置备份。我能够通过aws命令行为1或2个表传递一个json文件,这意味着json文件正在工作。 但是,当我传递一个大型JSON(包含50-100个DynamoDB表)来设置DataPipeline时,我会遇到这样的错误: 调用PutPipelineDefinition操作时发生错误(InvalidRequestException):超过Web服务限制:超过