
Tokyo Tyrant 是 Tokyo Cabinet 数据库网络接口。它拥有Memcached兼容协议,也可以通过HTTP协议进行数据交换。
Tokyo Tyrant 加上 Tokyo Cabinet,构成了一款支持高并发的分布式持久存储系统,对任何原有Memcached客户端来讲,可以将Tokyo Tyrant看成是一个Memcached,但是,它的数据是可以持久存储的。这一点,跟新浪的Memcachedb性质一样。
相比Memcachedb而言,Tokyo Tyrant具有以下优势:
1、故障转移:Tokyo Tyrant支持双机互为主辅模式,主辅库均可读写,而Memcachedb目前支持类似MySQL主辅库同步的方式实现读写分离,支持“主服务器可读写、辅助服务器只读”模式。
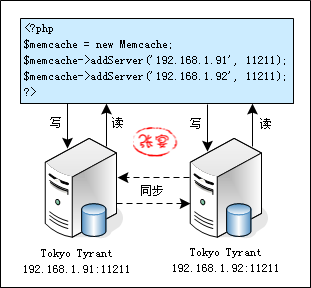
这里使用 $memcache->addServer 而不是 $memcache->connect 去连接 Tokyo Tyrant 服务器,是因为当 Memcache 客户端使用 addServer 服务器池时,是根据“crc32(key) % current_server_num”哈希算法将 key 哈希到不同的服务器的,PHP、C 和 python 的客户端都是如此的算法。Memcache 客户端的 addserver 具有故障转移机制,当 addserver 了2台 Memcached 服务器,而其中1台宕机了,那么 current_server_num 会由原先的2变成1。
2、日志文件体积小:Tokyo Tyrant用于主辅同步的日志文件比较小,大约是数据库文件的1.3倍,而Memcachedb的同步日志文件非常大,如果不定期清理,很容易将磁盘写满。
3、超大数据量下表现出色
但是,Tokyo Tyrant 也有缺点:在32位操作系统下,作为 Tokyo Tyrant 后端存储的 Tokyo Cabinet 数据库单个文件不能超过2G,而64位操作系统则不受这一限制。所以,如果使用 Tokyo Tyrant,推荐在64位CPU、操作系统上安装运行。
介绍内容来自张宴博客: http://blog.s135.com/post/362/
-
Tokyo Tyrant是名为Tokyo Cabinet的DBM的网络接口的套装。既然这个DBM拥有高性能,你可能烦恼于多个程序共享同一个数据库,或者远程程序访问数据库。因此,Tokyo Tyrant提供并发和远程连接到Tokyo Cabinet。它由管理数据库的服务器程序和用于客户端程序的访问类库组成。 因为线程池模型实现和现代Linux/*BSD核心的epoll/kqueue机制,该服务器提供
-
备份 1. 全量热备份 备份命令为: 1 tcrmgr copy -port 1978 localhost dpath.tch.xxxxx (其中xxxxx为备份时间) 根据业务需求及数据库运行状态决定备份的频度,全量热备时数据库库会写锁定,读不受影响。全量备份需记录备份时间点以提供replication恢复时所用,时间记录点精确的微秒,可记录到备份文件名中,如backup.tch.12594
-
本节介绍Tokyo Tyrant的远程数据库API,Lua扩展和协议。部分细节内容没有翻译。 五. 远程数据库API 远程数据库是一组用于使用Tokyo Cabinet抽象数据库的接口,由Tokyo Tyrant服务器作为中介。查看'tcrdb.h'获取全部说明。 注:该API是以.h文件提供,适用于C语言。对java开发似乎意义不大,因此考虑跳过此章节。 六.
-
之前简单的看了一下 Tokyo Tyrant(包括 Tokyo Cabint) 在 hash 存储上的一些实现,最近 Redis 又比较火热,因此,自己也尝试性的去了解了一下 Redis,并且结合 Tokyo Tyrant(以下简称 tt server),说说自己对这两种产品的看法。 目录 服务端处理模型 数据存储方式、持久化比较 复制方式比较 性能方面比较 总结 服务
-
* MongoDB vs Redis vs Tokyo Tyrant 准备对MongoDB, Redis以及Tokyo Tyrant的读写做一个简单的测试,为了进行相对公平的测试,需要了解他们背后的实现机制,下面是一些比较: 存储实现的比较: * 内存文件映像(Memory-File Mapping) Redis, MongoDB * 文件 + Cache Tokyo Tyrant
-
之前简单的看了一下 Tokyo Tyrant(包括 Tokyo Cabint) 在 hash 存储上的一些实现,最近 Redis 又比较火热,因此,自己也尝试性的去了解了一下 Redis,并且结合 Tokyo Tyrant(以下简称 tt server),说说自己对这两种产品的看法。 目录 服务端处理模型 数据存储方式、持久化比较 复制方式比较 性能方面比较 总结 服务
-
http://www.zavakid.com/2011/11/17/tokyo-tyrant-vs-redis/ 之前简单的看了一下 Tokyo Tyrant(包括 Tokyo Cabint) 在 hash 存储上的一些实现,最近 Redis 又比较火热,因此,自己也尝试性的去了解了一下 Redis,并且结合 Tokyo Tyrant(以下简称 tt server),说说自己对这两种产品的看法。
-
* MongoDB vs Redis vs Tokyo Tyrant 准备对MongoDB, Redis以及Tokyo Tyrant的读写做一个简单的测试,为了进行相对公平的测试,需要了解他们背后的实现机制,下面是一些比较: 存储实现的比较: * 内存文件映像(Memory-File Mapping) Redis, MongoDB * 文件 +
-
在 Cocos Creator 中,我们支持 Web 平台上最广泛使用的标准网络接口: XMLHttpRequest:用于短连接 WebSocket:用于长连接 当然,在 Web 平台,浏览器原生就支持这两个接口,之所以说 Cocos Creator 支持,是因为在发布原生版本时,用户使用这两个网络接口的代码也是可以运行的。也就是遵循 Cocos 一直秉承的 “一套代码,多平台运行” 原则。 注意
-
网络浏览接口 可阅览因特网(互联网)上的Web网页。 如何卷动 显示选单 输入地址(URL) 使用分页 显示Flash®内容 上传档案 关闭网络浏览接口 利用网络过滤服务 "网络浏览接口"用户使用承诺条款
-
如何找到对等节点(Peers) Geth不断尝试连接到网络上的其他节点,直到它找到peers。如果您在路由器上启用了UPnP,或者在面向Internet的服务器上运行其他方式,则它也将接受其他节点的连接。 Geth通过称为发现协议的东西找到peers。在发现协议中,节点相互通信以了解网络上的其他节点。为了一开始就可以执行,geth使用一组引导节点,其被记录在源代码中。 想要在启动时更改bootno
-
Selenium [移动 JSON 协议规范](https://github.com/SeleniumHQ/mobile-spec/blob/master/spec-draft.md) 支持一个获取和设置网络连接的[API](https://github.com/SeleniumHQ/mobile-spec/blob/master/spec-draft.md#104)。这个 API 会设置一个掩码
-
关闭网络浏览接口 启动网络浏览接口时按下按钮。会自动切断与网络的联机。 提示 亦可从选单列中选择[档案] > [关闭网页]。
-
(编辑)我想将GKE吊舱连接到Atlas。 我有一个Atlas db,带有一个连接到GCP专有网络的专有网络对等连接。我正在尝试运用我在这些图坦卡门中学到的东西: 配置VPC网络对等互连 控制对专有网络的访问 当我查看VPC网络对等互连时 但是,可以预见的是,结果是一样的。 从gcloud shell我做: 并获得: 在GKE中,我创建了一个具有计算网络管理员角色的服务帐户,但不确定如何将其链接到
-
问题内容: 我一直在尝试让一个简单的网络测试程序无法运行。 服务器: 客户: 当我使用127.0.0.1或我的内部IP作为主机名时,该程序运行良好。但是,每当我切换到外部IP地址时,都会引发错误。 我特意选择了一个不常见的端口,以查看是否是问题所在,但没有运气。使用telnet可以毫无问题地进行连接,但是当我尝试使用canyouseeme.org访问端口时,它表明连接超时。我什至尝试禁用所有防火墙
-
辅助阅读:TensorFlow中文社区教程 - 英文官方教程 代码见:full_connect.py Linear Model 加载lesson 1中的数据集 将Data降维成一维,将label映射为one-hot encoding def reformat(dataset, labels): dataset = dataset.reshape((-1, image_size * imag