
Zoie 是用 Java 编写的实时搜索/索引系统。
-
Zoie is a real-time search and indexing system built on Apache Lucene. In a real-time search/indexing system, a document is made available as soon as it is added to the index. This functionality is es
-
package proj.zoie.solr; import it.unimi.dsi.fastutil.longs.LongArrayList; import it.unimi.dsi.fastutil.longs.LongList; import java.io.IOException; import java.net.URL; import java.util.ArrayList; im
-
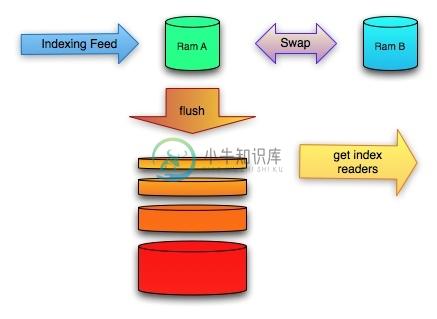
https://linkedin.jira.com/wiki/pages/viewpage.action?pageId=4456480 一、总体架构 Zoie是一个实时的搜索引擎系统,其需要逻辑上独立的索引和搜索子系统相对紧密的结合在一起,从而使得一篇文档一经索引,就能够立刻被搜索的到。 ZoieSystem是Zoie的重要组成部分,其一方面通过实现DataConsumer接口而完成了索引功能,一
-
表1.1 Lucene版本发布历史 版本 发布日期 里程碑 0.01 2000年3月30日 在SourceForge网站第一次开源发布 0.04 2000年4月19日 包含基于语法的语汇单元化StandardTokenizer等 1.0 2000年10月日 修复bug,性能优化 1.01b 2001年6月2日 在SourceForge网站最后一次发布,修复bug,支持前缀查询 1.2 rc1 20
-
这个类的关于consume() 和 flushBuffer()方法的等待调用比较绕逻辑 。 package proj.zoie.impl.indexing; import java.util.Collection; import java.util.LinkedList; import org.apache.log4j.Logger; import proj.zoie.api.D
-
[size=small]Zoie是LinkedIn开源的基于lucene的实时检索系统,对于它的介绍及初步使用可参考我的上一篇文章“使用Zoie构建实时检索系统”。在初步研究并理解了Zoie的源码实现后,本文分析一下Zoie的实现。 实时检索的核心原理 通常的检索系统中,建索引和查询是分开的,即建索引是离线的,新的索引会以一定频率(比如每隔5分钟)供查询端使用。对于一些站内检索来说,这种延迟性使得
-
1、zoie中需要自己继承StreamDataProvider<T>来实现自己系统中的一个数据提供的处理者 。 T为自己系统中需要处理的数据的泛型 。 2、StreamDataProvider自己并不会自动启动消费数据,继承类在实例化时候,需要给其注入消费者实例(一般为ZoieSystem),若不注入则无法消费数据 。 3、然后在系统的运行中需要线程定时 或者 其它方法去调用StreamDat
-
两个索引是不一样的,一个是基于硬盘上的index.dic来打开的索引(相当于lucene中基本的打开索引文件夹得到的索引),一个是直接在内存中的索引,搜索时为保证完整性,会在两个中都搜索。 但添加时只添加到内存索引中,因为效率的问题(在内存中操作事件极短),添加后会立刻重新读入索引,以便添加后可以立刻搜索到 。 当内存中索引添加到一定的量时,会将在内存中的这这一部
-
bugu-mongo 2.x版本集成了Lucene的功能。当往MongoDB中新增一个Document时,能自动为该Document建立Lucene索引。相应的,当MongoDB中的Document被修改、删除时,对应的Lucene索引也会修改、删除。 另外,bugu-mongo还提供了对Lucene搜索的支持。根据Lucene索引进行搜索的时候,搜索结果能自动转换成对应的Entity对象。 在L
-
我有大量相同类型的实体,每个实体都有大量属性,并且我只有以下两种选择来存储它们: 将每个项存储在索引中并执行多索引搜索 将所有enties存储在单个索引中,并且只搜索1个索引。 一般而言,我想要一个时间复杂度之间的比较搜索“N”实体与“M”特征在上述每一种情况!
-
我正在使用: neo4j 2.0。1 我有一个具有属性名称的节点人员,我想用Lucene语法搜索该属性。我在我的存储库中使用findByNamelike方法,它非常适合像value*或*value或*etc这样的查询。 但是我需要这样的查询{A*TO D*}。我发现了一个弃用的方法findAllByQuery(名称,查询),用这个方法我可以实现我的需求。 > 我还注意到,如果我从cypher创建节
-
我使用< code > Hibernate Search 4 . 5 . 1 编写了< code>Spring web-app。当我尝试搜索时,它返回一个条目列表。我认为索引中的问题。用于索引的目录已创建,但实体保存文件后,目录中的文件不变。 这是我的Spring配置文件 我的实体文件
-
我正在使用elasticsearch elasticsearch-rails的官方gems套件,我在试图索引父/子关系时非常困难,我不确定我的问题是在映射、索引或查询还是在所有这些方面!!所以我不会发布我的代码片段。 是否有以下完整的工作示例: 子索引和父索引的映射 子级和父级的索引/更新/删除 在两个索引上查询高级查询;这意味着我需要用'has_child'查询在父索引上搜索,也需要用'has_
-
搜索引擎分为两部分: 时间筛选 和 搜索引擎 (详情) 1.时间筛选 便捷按钮有今日、昨日、前日、上周 X、近七天,并且能自定义选择时间段来得出想要的结果报表 2.搜索引擎 (时间段详情) 选择日期,查看来自对应时间段内,各个搜索引擎的访问量比例
-
在测试此文本时,我在要在文本中搜索的列上创建了lucene(3.0.1)索引: 如果我按关键字搜索,它会给出结果,但按 我正在使用standardAnalyzer: 因为已设置,它应创建令牌,并且应存在$GLD。Analyzer将从文本中删除停止字,因为word也将在该过程中删除。
-
注意: 我只使用“luceneresults”.ascx和.cs。 ----问题更新了,因为我缩小了问题的范围---- 我试图创建一组特定项的索引,用于Lucene搜索。 在web.config中,我指定了一个索引,该索引包含: 完整索引: