
Pivotal GemFire 是内存中的分布式数据库,提供:
性能扩展
通过全局的分布式应用进行一致的数据库操作
高可用性和高伸缩性,全局规模
强大的开发者特性
简单的分布式节点管理
作为世界规模最大的实时交易系统之一12306就是使用的#GemFire#
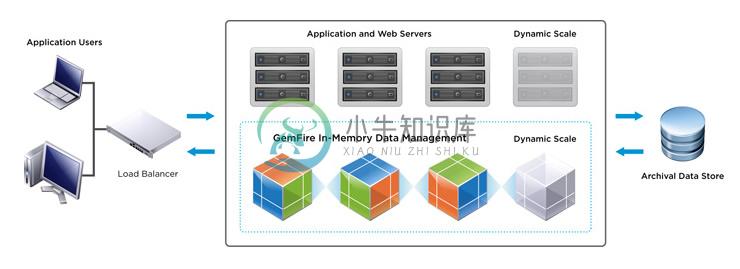
-
分布式缓存领域,大家可能较为熟悉Redis,当红一哥,还有经典老将Memcached, 以及新秀Apache Ignite, 当然还有Oracle的Coherence内存数据网格,今天我们主要关注投行金融领域的分布式缓存一哥Gemfire。我们大名鼎鼎的12306购票网站就是使用GemFire,它解决了内存数据库所有问题,把理论上一切都可在内存中运行变为现实。 1. 前世今生 Gemfire的第一
-
GemFire官网: http://pivotal.io/big-data/pivotal-gemfire GemFire与Redis一样,是Pivotal公司产品,Pivotal由EMC与Vmware组建 GemFire的典型案例:12306网站(2012年,第一阶段)余票查询系统升级 和 (2013年,第二阶段)订票系统升级 “First, Pivotal GemFire offered pr
-
原文地址:https://blog.csdn.net/xiaojin21cen/article/details/79072939 分布式缓存领域,大家可能较为熟悉Redis,当红一哥,还有经典老将Memcached, 以及新秀Apache Ignite, 当然还有Oracle的Coherence内存数据网格,今天我们主要关注投行金融领域的分布式缓存一哥Gemfire。我们大名鼎鼎的12306购
-
一、GemFire是什么? 如果你了解Redis或memCached,那么恭喜,你很快就能理解GemFire是什么,没错,你可以把它理解为一个增强版的Redis,具体在哪些方面增强,我们日后慢慢聊。如果你不了解Redis,也没有关系,先看官方网站上的说法:Pivotal GemFire is the distributed, in-memory database for developers
-
1.安装程序的使用 locator 启动locator gfsh>start locator --name=locator1 指定端口启动 gfsh>start locator --name=locator1 --port=12105 指定端口和绑定ip启动 gfsh>start locator --name=locator1 --port=12105 --bind-address=10.10.1
-
1.Ignite简介 Apache Ignite 内存数据组织框架是一个高性能、集成化和分布式的内存计算和事务平台,用于大规模的数据集处理,比传统的基于磁盘或闪存的技术具有更高的性能,同时他还为应用和不同的数据源之间提供高性能、分布式内存中数据组织管理的功能。 2.Ignite历史 Ignite来源于尼基塔·伊万诺夫于2007年创建的GridGain系统公司开发的GridGain软件,尼基塔领
-
开篇词 该指南将逐步介绍使用 Pivotal GemFire 的数据结构来缓存代码中的某些调用。 有关 Pivotal GemFire 概念和从 Pivotal GemFire 访问数据的更多常规知识,请通读使用 Pivotal GemFire 访问数据的指南。 你将创建的应用 我们将构建一个服务,该服务从 CloudFoundry 托管的引句服务请求引句,并将其缓存在 Pivotal Gem
-
1. Spring Data Pivotal Gemfire –简介 在这篇文章中,我们将介绍有关Spring Data Pivotal Gemfire的全面教程。 Pivotal Gemfire是由Apache Geode支持的内存中数据网格解决方案。 使用Pivotal Gemfire构建的应用程序使您可以在分布式服务器节点之间轻松扩展系统。 无论分布结构如何,Pivotal Gemfire均
-
开篇词 该指南将引导你创建通过基于超媒体的 RESTful 前端访问 Pivotal GemFire 的数据。 你将创建的应用 我们将构建一个 Spring 应用,该应用允许我们使用 Spring Data REST 创建和检索存储在 Pivotal GemFire 内存数据网格中的 Person 对象。Spring Data REST 具有 Spring HATEOAS 和 Spring D
-
开篇词 该指南将引导你使用 Pivotal GemFire 的数据服务集来构建应用。 你将创建的应用 我们将使用功能强大的 Spring Data for Pivotal GemFire 库来存储和检索 POJO。 你将需要的工具 大概 15 分钟左右; 你最喜欢的文本编辑器或集成开发环境(IDE) JDK 1.8 或更高版本; Gradle 4+ 或 Maven 3.2+ 你还可以将代码
-
pivotal 1. Spring Data Pivotal Gemfire –简介 在这篇文章中,我们将介绍有关Spring Data Pivotal Gemfire的全面教程。 Pivotal Gemfire是由Apache Geode支持的内存中数据网格解决方案。 使用Pivotal Gemfire构建的应用程序使您可以在分布式服务器节点之间轻松扩展系统。 无论分布结构如何,Pivotal
-
1.分布式数据存储 • 稳定而高性能的的基于内存的数据数据存储 • 灵活的Cache部署策略:点对点(peer to peer);客户端/服务端(client server);多集群(multiple clusters)的本地或远程数据同步,支持数据高性能灾备和双活 • 灵活的Region(数据对象集或者可理解为表)分布式处理:同一集合数据(可理解为一个表的数据)可以整集多
-
This guide walks you through the process of creating an application that accesses Pivotal GemFire data through a hypermedia-based REST-ful frontend. What you’ll build You’ll build a Spring Web applica
-
http://www.tuicool.com/articles/6NNjYf blog.csdn.net/caolaosanahnu/article/details/7939120 http://community.gemstone.com/display/gemfire/GemFire+Tutorial http://blog.csdn.net/caolaosanahnu/article/det
-
gemfire的资料真是少,花了1天时间搞了个demo,技术:spring mvc+spring security+jquery easy ui+spring data gemfire+redis gemfire配置文件: <?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/sche
-
测试用例 使用消息大小约200+bytes,每5个消息一个batch写入。分别尝试用1到15个线程来写入,每个线程顺序提交10万次。分别测试了三种数据库拓扑结构: 单节点, 落硬盘。 两个节点(互备)分布在同一台物理机,不写硬盘。 两个节点(互备)分布在不同物理机,不写硬盘。 物理机配置 Ubuntu 12.04 64bit CPU: 伪32核, Intel(R) Xeon(R) CPU E5-2
-
com.gemstone.gemfire.modules.hibernate.GemFireRegionFactory 打开查询缓存 true 为查询缓存设置Cache Factory com.gemstone.gemfire.modules.hibernate.GemFireQueryCacheFactory 共享缓存模式 ENABLE_SELECTIVE|DISABLE_SELECTIVE|A
-
GemFire目前已经开源,开源项目的主页: http://geode.incubator.apache.org/,商业版本的主页: https://pivotal.io/big-data/pivotal-gemfire,关于开源版本如何编译,以及与商业版本的区别(功能上有区别),我们以后再花时间来介绍。 我们先使用商业版本作为学习的入口,在初始学习阶段,迅速了解一个产品的最好方法就是亲手安装它。
-
分布式支持 数据访问层支持分布式数据库,包括读写分离,要启用分布式数据库,需要开启数据库配置文件中的deploy参数: return [ // 启用分布式数据库 'deploy' => 1, // 数据库类型 'type' => 'mysql', // 服务器地址 'hostname' => '192.168.1.1,19
-
差不多70MIN 面试官人很帅,而且上来就介绍面试流程,整个面试下来感觉很舒服,写算法题的时候也在和面试官沟通确定一些特殊情况 1.自我介绍 2.集中管理平台是什么#面经# 3.发布是怎样实现的 4.Exporter是怎么采集到数据的 (没答好 确实没了解过) 5.交付相关 6.Prometheus规则是怎样的 具体存储在哪里 7.仪表盘数据是哪里来的 Prometheus支持多少台机器 8.怎么
-
在分布式系统中,常困扰我们的还有上线问题。虽然目前有一些优雅重启方案,但实际应用中可能受限于我们系统内部的运行情况而没有办法做到真正的“优雅”。比如我们为了对去下游的流量进行限制,在内存中堆积一些数据,并对堆积设定时间或总量的阈值。在任意阈值达到之后将数据统一发送给下游,以避免频繁的请求超出下游的承载能力而将下游打垮。这种情况下重启要做到优雅就比较难了。 所以我们的目标还是尽量避免采用或者绕过上线
-
我是wordpress的新手,在管理数据库方面有困难。我已经安装了“管理员”插件来管理数据库。我已经创建了一个名为“usersupp_admin”的新表。现在我还创建了一个自定义模板,该模板将使用PDO语句连接到此数据库,现在的问题是在哪里可以获取主机、数据库名、用户和密码?以下是代码: 任何帮助都将不胜感激。
-
这里我的疑问是,如果我使用多个分布式数据库,cam如何在配置(application.properties)中提到不同的DB源URL?目前我正在使用以下结构来使用一个数据库, 就像上面那样。 所以,如果我使用多个DB用于多个区域,我如何在这里给出有条件的配置?我是微服务世界和分布式数据库设计模式的新手。
-
将现有存储库数据库迁移到其他数据库可能包括迁移到同一服务器中的其他数据库,或迁移到不同操作系统上的数据库(例如,从 Windows 到 macOS)。 如果你想迁移你的存储库数据库,请按照下列步骤操作: 通过运行命令,或使用通知区域或菜单栏中的图标来停止 Navicat Monitor 服务。 在你的数据库管理工具中,将当前的存储库数据库(所有表的结构和数据)复制到新的存储库数据库。 启动 Nav
-
本文向大家介绍NoSQL数据库的分布式算法详解,包括了NoSQL数据库的分布式算法详解的使用技巧和注意事项,需要的朋友参考一下 今天,我们将研究一些分布式策略,比如故障检测中的复制,这些策略用黑体字标出,被分为三段: 数据一致性。NoSQL需要在分布式系统的一致性,容错性和性能,低延迟及高可用之间作出权衡,一般来说,数据一致性是一个必选项,所以这一节主要是关于 数据复制 和 数据恢复 。 数据放置
-
下面是我的配置: