
������ 比 MyBatis 开发效率高 100 倍的条件检索引擎,天生支持联表,使一行代码实现复杂列表检索成为可能!
- 文档:https://searcher.ejlchina.com/
- 掘金手把手入门:https://juejin.cn/post/7027733039299952676
- 更新日志:CHANGELOG
- 框架目的:只一行代码实现:
- 多表联查
- 分页搜索
- 任意字段组合过滤
- 任意字段排序
- 多字段统计
- 架构图:
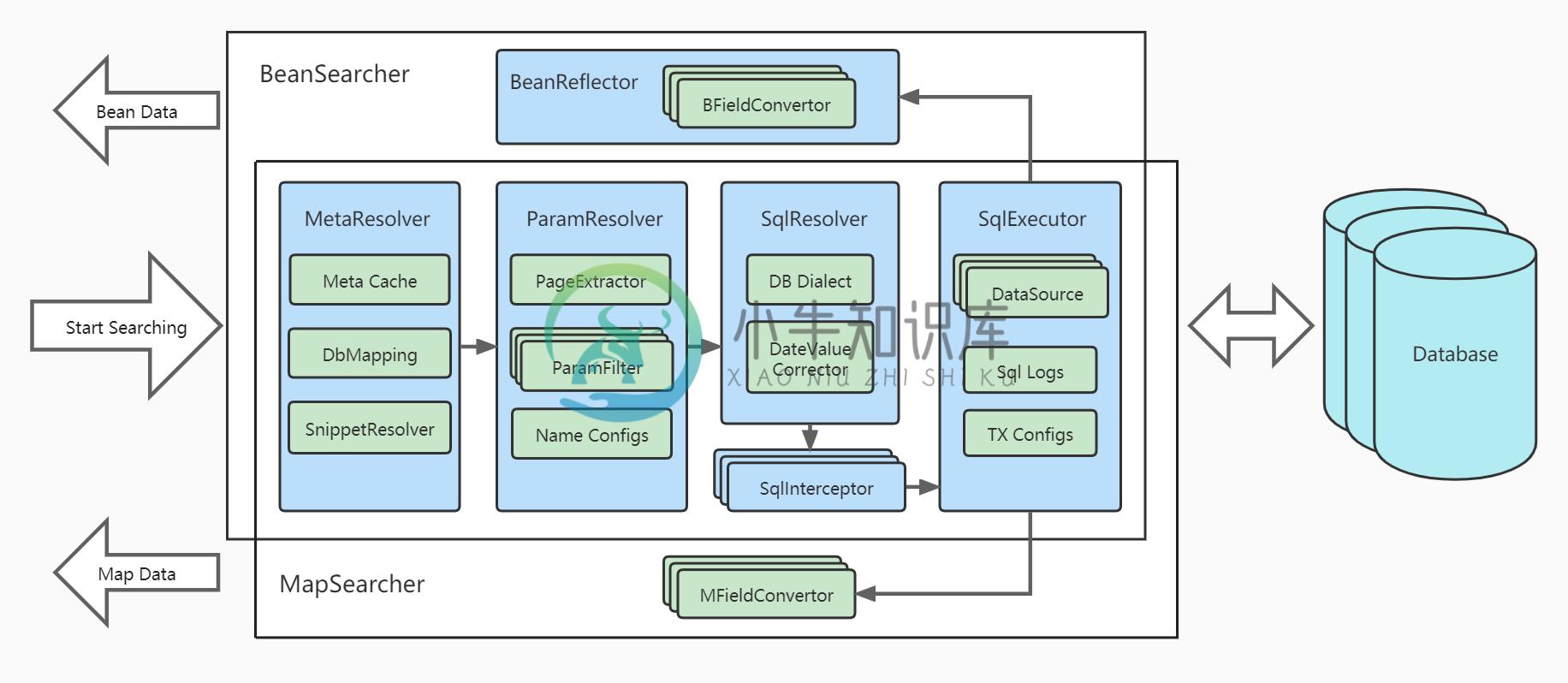
✨ 特性
- 支持 实体多表映射
- 支持 动态字段运算符
- 支持 分组聚合 查询
- 支持 Select | Where | From 子查询
- 支持 实体类嵌入参数
- 支持 字段转换器
- 支持 Sql 拦截器
- 支持 数据库 Dialect 扩展
- 支持 多数据源 与 动态数据源
- 支持 注解缺省 与 自定义
- 等等
⁉️为什么用
这绝不是一个重复的轮子
虽然 增删改 是 hibernate 和 mybatis、data-jdbc 等等 ORM 的强项,但查询,特别是有 多条件、联表、分页、排序 的复杂的列表查询,却一直是它们的弱项。
传统的 ORM 很难用较少的代码实现一个复杂的列表检索,但 Bean Searcher 却在这方面下足了功夫,这些复杂的查询,几乎只用一行代码便可以解决。
- 例如,这样的一个典型的需求:
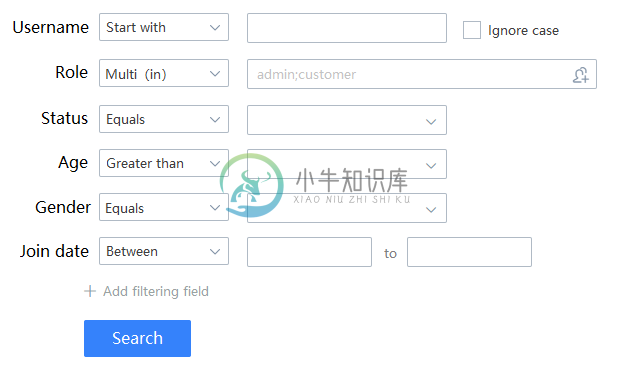
后端需要写一个检索接口,而如果用传统的 ORM 来写,代码之复杂是可以想象的。
而 Bean Searcher 却可以:
�� 只一行代码实现以上功能
首先,你有一个实体类:
@SearchBean(tables="user u, role r", joinCond="u.role_id = r.id", autoMapTo="u") public class User { private long id; private String username; private int status; private int age; private String gender; private Date joinDate; private int roleId; @DbField("r.name") private String roleName; // Getters and setters... }
然后你就可以用一行代码实现这个用户检索接口:
@RestController @RequestMapping("/user") public class UserController { @Autowired private BeanSearcher beanSearcher; // 注入 BeanSearcher 的检索器 @GetMapping("/index") public SearchResult<User> index(HttpServletRequest request) { // 这里只写一行代码 return beanSearcher.search(User.class, MapUtils.flat(request.getParameterMap())); } }
这一行代码实现了以下功能:
- 多表联查
- 分页搜索
- 组合过滤
- 任意字段排序
- 字段统计
例如,该接口支持如下请求:
-
GET: /user/index无参请求(默认分页):
{ "dataList": [ { "id": 1, "username": "Jack", "status": 1, "level": 1, "age": 25, "gender": "Male", "joinDate": "2021-10-01" }, ... // 默认返回 15 条数据 ], "totalCount": 100, "summaries": [ 2500 // age 字段统计 ] }
-
GET: /user/index? page=1 & size=10指定分页参数
-
GET: /user/index? status=1返回
status = 1的用户 -
GET: /user/index? name=Jac & name-op=sw返回
name已Jac开头的用户 -
GET: /user/index? name=Jack & name-ic=true返回
name = Jack(忽略大小写)的用户 -
GET: /user/index? sort=age & order=desc按字段
age降序查询 -
GET: /user/index? onlySelect=username,age只检索
username与age两个字段:{ "dataList": [ { "username": "Jack", "age": 25 }, ... ], "totalCount": 100, "summaries": [ 2500 ] }
-
GET: /user/index? selectExclude=joinDate检索时排除
joinDate字段
✨ 参数构建器
Map<String, Object> params = MapUtils.builder() .selectExclude(User::getJoinDate) // 排除 joinDate 字段 .field(User::getStatus, 1) // 过滤:status = 1 .field(User::getName, "Jack").ic() // 过滤:name = 'Jack' (case ignored) .field(User::getAge, 20, 30).op(Opetator.Between) // 过滤:age between 20 and 30 .orderBy(User::getAge, "asc") // 排序:年龄,从小到大 .page(0, 15) // 分页:第 0 页, 每页 15 条 .build(); List<User> users = beanSearcher.searchList(User.class, params);
�� 快速开发
使用 Bean Searcher 可以极大地节省后端的复杂列表检索接口的开发时间!
- 普通的复杂列表查询只需一行代码
- 单表检索可复用原有
Domain,无需定义SearchBean
�� 集成简单
可以和任意 Java Web 框架集成,如:SpringBoot、Spring MVC、Grails、Jfinal 等等。
Spring Boot 项目,添加依赖即集成完毕:
implementation 'com.ejlchina:bean-searcher-boot-stater:3.1.2'
接着便可在 Controller 或 Service 里注入检索器:
/** * 注入 Map 检索器,它检索出来的数据以 Map 对象呈现 */ @Autowired private MapSearcher mapSearcher; /** * 注入 Bean 检索器,它检索出来的数据以 泛型 对象呈现 */ @Autowired private BeanSearcher beanSearcher;
其它框架,使用如下依赖:
implementation 'com.ejlchina:bean-searcher:3.1.2'
然后可以使用 SearcherBuilder 构建一个检索器:
DataSource dataSource = ... // 拿到应用的数据源 // DefaultSqlExecutor 也支持多数据源 SqlExecutor sqlExecutor = new DefaultSqlExecutor(dataSource); // 构建 Map 检索器 MapSearcher mapSearcher = SearcherBuilder.mapSearcher() .sqlExecutor(sqlExecutor) .build(); // 构建 Bean 检索器 BeanSearcher beanSearcher = SearcherBuilder.beanSearcher() .sqlExecutor(sqlExecutor) .build();
�� 扩展性强
面向接口设计,用户可自定义扩展 Bean Searcher 中的任何组件!
比如你可以:
- 自定义
DbMapping来实现自定义注解,或让 Bean Searcher 识别其它 ORM 的注解 - 自定义
ParamResolver来支持 JSON 形式的检索参数 - 自定义
FieldConvertor来支持任意的 字段类型 - 自定义
Dialect来支持更多的数据库 - 等等..
-
超好用的数据库检索工具介绍——Bean Searcher 一、介绍 Bean Searcher与我们常用的mybatis、tk等有类似之处,但也有区别,具体如下: 相同点: * 都是orm框架 * 都用于查询数据 不同点: * Bean Searcher只用于查询 * 且简洁高效 * 能轻松完成众多复杂查询 具体查看官网就行:Bean Searcher官网 举
-
导入依赖 <dependency> <groupId>com.ejlchina</groupId> <artifactId>bean-searcher-boot-starter</artifactId> <version>3.8.2</version> </dependency> <dependenc
-
<dependency> <groupId>com.ejlchina</groupId> <artifactId>bean-searcher</artifactId> <version>2.0.1</version> </dependency> 版本问题,降成低版本就可以 <dependency> <groupId>com.ejlchina</groupId>
-
你好,我正在练习使用C++中的二维数组,我的问题是,例如,如果我想检查4是否有0或11在北,东,南,西作为邻居,它应该返回false。这是我的if 现在我的问题是,由于4的西面和4的北面都超出了界限,它将永远不会返回false。如何优化if条件使其返回false?这是我的二维阵列
-
我试图实现一对一聊天使用firebase实时数据库,我插入消息与senderid,Recieverid,消息,日期,sendername,Recievername,在我的情况下,不同的用户是不同的聊天室,我需要展示这个聊天室一对一聊天室我如何实现在我的android应用程序 下面是我检索数据的代码 但这段代码从聊天室获取所有数据,但我需要排除发送者名和接收者名相等的消息,sendername是从应
-
如何根据对象数组的条件获取所有索引?我已经尝试了下面的代码,但是它只返回第一次出现的代码。
-
代码示例在Go中,但这不是一个特定于Go的问题 我正在尝试防止对重复的本地二级索引的现有分区键进行重复写入。我有一个带有以下属性的Dynamo表(简化): 用户名字段是一个LocalSecondaryIndex,其名称是username\u index,它使用相同的分区键,排序键是它自己。 我试图阻止将项目请求放入我的表中,其中用户名已经存在于公司ID中。我尝试在写入之前使用以下条件检查 但是,如
-
我试图比较两个数据帧的差异,使用一个公共键/索引值,该值由帧中的3列组成。 e、 g.假设两列中的列都是:“COL1”、“COL2”、“COL3”、“COL4” 数据帧是df1 然后,我使用了set_index方法: 然后我想遍历df1数据帧,并检查df2数据帧是否有匹配的索引。我尝试过使用以下方法: 但是它返回false(尽管我可以通过打印看到两者的索引都存在)。 我做错了什么? 另外,如何使用
-
我目前正在重构一个用Symfony 3编写的应用程序,并且严重依赖ORM,我一直在尝试获取一个包含所选列索引的对象/数组。 现在我对PHP PDO相当熟悉,我记得查询结果的基本获取如下所示 (根据我的查询)它会给我一个类似于下面的数组 在理论方面,我尝试使用几个具有水合参数的内置函数 运气不好,我最后得到了这样的东西 有人能帮我或者给我指出正确的方向吗?如何正确地解决这个问题? ----更新了问题
-
问题内容: 我在SQS中有多个消息。即使有数十个可见代码(不在运行中),以下代码也 始终 仅返回一个。 我认为setMaxNumberOfMessages允许一次使用多个..我误解了吗? 我也尝试使用withMaxNumberOfMessages,但没有任何运气: 我怎么知道队列中有消息?大于1? 上面的代码总是在运行之前给我> 1 感谢您的输入 问题答案: AWS API参考指南:Query /
-
问题内容: 使用JDBC时,我经常遇到类似 我问自己(也包括代码作者)为什么不使用标签来检索列值: 我听到的最好的解释是关于性能的。但是实际上,这使处理速度非常快吗?我不相信,尽管我从未进行过测量。我认为,即使按标签检索会稍慢一些,但它仍具有更好的可读性和灵活性。 因此,有人可以给我很好的解释,避免使用列索引而不是列标签来检索列值吗?两种方法的优缺点(也许涉及某些DBMS)是什么? 问题答案: 默