
Apache Iceberg 是一种新的表格格式,用于存储和分析大型的、移动缓慢的表格数据。它的工作方式类似于 SQL 表,它旨在改进内置在 Hive、Presto 和 Spark 中的事实上的标准表布局。
对于使用者来说:
- 模式演化(Schema evolution)支持添加、删除、更新或重命名,并且没有副作用
- 隐藏分区(Hidden partitioning)可以防止导致错误提示或非常慢查询的用户错误
- 分区布局演变(Partition layout evolution)可以随着数据量或查询模式的变化而更新表的布局
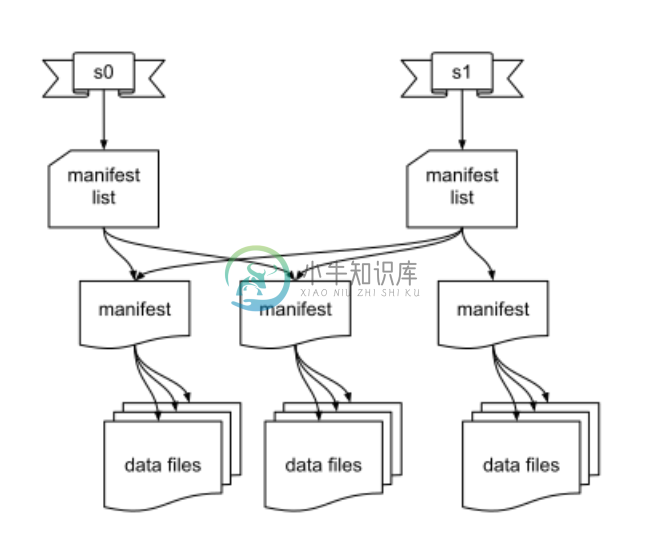
- 时光穿梭(Time travel)可使用完全相同的表快照实现重新查询,或者使用户轻松检查更改
- 版本回滚使用户可以通过将表重置为良好状态来快速纠正问题
可靠性与性能方面,Iceberg 可用于生产中,它的一个表可以包含数十 PB 的数据,即使没有分布式 SQL 引擎也可以读取这些巨大规模的表。
- 扫描速度很快,无需使用分布式 SQL 引擎即可读取表或查找文件
- 高级过滤,使用表元数据对数据文件以分区和列级统计信息进行修剪
Iceberg 旨在解决最终一致的云对象存储中的正确性问题:
- 可与任何云存储一起使用,并且通过避免列出(list)和重命名,可以在 HDFS 中减少 NN 拥塞
- 可序列化的隔离,表更改是原子性的,对外永远不会有部分更改或未提交的更改
- 多个并发写入器使用乐观并发,即使写入冲突,也将重试以确保兼容更新成功
-
导言 本文主要介绍如何快速的通过Spark访问Iceberg table。 Spark通过DataSource和DataFrame API访问Iceberg table,或者进行Catalog相关的操作。由于Spark Data Source V2 API还在持续的演进和修改中,所以Iceberg在不同的Spark版本中的使用方式有所不同。 版本对比 功能 Spark 2.4 Spark 3.0
-
导语 作为构建新一代数据湖的三个中间件Apache Iceberg, Apache Hudi, Delta Lake都支持Schema Evolution,但是三者的支持能力不尽相同,其中Iceberg宣称支持 Full Schema Evolution。本文将详细分析Iceberg 的Full Schema Evolution, 同时捎带对比下和Delta Lake以及Hudi的Schema E
-
引言 本次分享的出发点是为了理清楚 iceberg 是如何实现 MOR 的,思考这么几个问题: delta 增量数据文件的格式是否与 base 保持一致 delta 增量数据文件是否需要拆分为 insert 和 delete 两部分 delete 文件的格式规范如何设计,兼顾数据摄取的吞吐量和查询效率 实现 MOR 后,minor compaction 和 major compaction 是如何
-
问题内容: 我的同事在工作中提出了一个我无法回答的问题(由于缺乏经验),该问题与跟踪表中相关字段的变化有关。 想象一下,我们有3个表,每个表20个字段。在此示例中,我们考虑这些表中的每一个都有2个字段,一个名为LastUpdatedOn,另一个名为LastUpdatedBy。 如果我们只想跟踪这3个表中的更改,而只跟踪几个特定字段,而没有为每个表创建包含更新前最新版本的历史表,那么我们如何跟踪这些
-
跟踪行为控制着 Entity Framework Core 是否会在其变更跟踪器里维持实体实例的信息。如果实体是被跟踪的,任何检测到的该实体的变更都将在 SaveChanges() 时持久化到数据库中。Entity Framework Core 还会对已跟踪的、之前已加载到 DbContext 实例中的查询和实体进行相互的导航属性装配。 提示 你可以在 GitHub 上查阅当前文章涉及的代码样例。
-
问题内容: 我正在尝试使用“ track by”表达式来跟踪对象数组中按id进行的选择。但是,我似乎无法使它像我认为的那样起作用。 因此,根据文档,我虽然在加载时使用options指令会看到serverDTO的’track by’ID为1、2和3,并已对其进行了预先选择。用户修改选择后,我需要执行以下操作将数组返回到服务器- 我是否应该解决这个问题? 问题答案: 据我所知,它只是在内部帮助Angu
-
我对Java非常陌生,所以如果我做了一些非常错误的事情,请原谅我。 我在一个项目中工作,我需要快速扫描大量的数据(CSV有5000万行或更多,每行5个条目)重复。我使用了,因为它的方法速度很快。
-
本章介绍如何使用Zipkin或Jaeger收集启用了Istio的应用程序的调用链信息。 完成本章后,你可以理解有关应用程序的所有假设以及如何使其参与跟踪,无论您使用何种语言/框架/平台构建应用程序。 BookInfo示例用来作为此任务的示例应用程序。 环境准备 参照安装指南的说明安装Istio。 如果您在安装过程中未启动Zipkin或Jaeger插件,则可以运行以下命令启动: 启动Zipkin:
-
我们正在考虑利用spring cloud sleuth进行分布式跟踪,并且我们已经开发了一个PoC。这似乎是一个很好的解决方案,开箱即用。 但我有一个后续问题: 我们使用随机UUID和64位ID作为跟踪ID。我们知道自定义头(例如,一个新的跟踪Id)可以与sleuth头一起添加,但是否可以覆盖slueth的默认跟踪Id格式?我们已经查看了文档,也许传播是我们要走的路。有谁做了这一点,可以指出我们在
-
Trace 事件提供了一种机制,可以集中由 V8,Node 核心, 以及用户代码生成的跟踪信息。 启动 Node.js 应用时添加 --trace-events-enabled 标记,可以启用 Tracing. 可以通过在 --trace-event-categories 标记后跟一个用逗号分隔的类别名称列表, 来指定特定的跟踪记录集合。 node 和 v8 默认启用。 node --trace-
-
跟踪配置指定了Envoy使用的HTTP跟踪器的全局设置。在服务的顶层配置上定义。未来,Envoy可能会支持其他跟踪器,但现在HTTP跟踪器是唯一支持的跟踪器。 { "http": { "driver": "{...}" } } http (optional, object) 提供HTTP跟踪器的配置。 driver (optional, object) 提供处理跟踪和创建span