
Google 人工智能研究部门在语音识别方面取得了新的进展,能从嘈杂的环境中分辨声音。这套强大的 AI 系统涉及到 Speaker diarization 任务,需要标注出“谁”从“什么时候”到“什么时候”在说话,将语音样本分割成独特的、同构片段的过程。还能将新的演讲者发音与它以前从未遇到过的语音片段关联起来。
其核心算法已经开源可用。它实现了一个在线二值化错误率(DER),在 NIST SRE 2000 CALLHOME 基准上是 7.6%,这对于实时应用来说已经足够低了,而谷歌之前使用的方法 DER 为 8.8%。
UIS-RNN 是无界交错状态递归神经网络(Unbounded Interleaved-State Recurrent Neural Network)算法的库。 UIS-RNN 通过学习示例解决了分段和聚类顺序数据的问题。
由于对某些内部库的依赖性,这个开源实现与在论文中用于生成结果的内部实现略有不同。
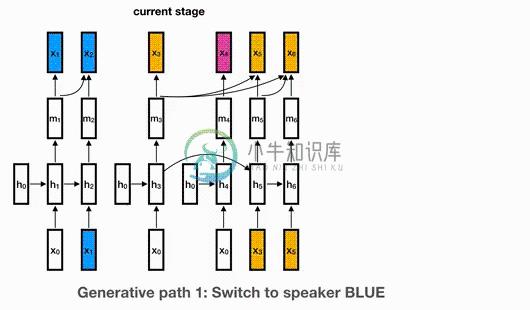
谷歌研究人员的新方法是通过递归神经网络(RNN)模拟演讲者的嵌入(如词汇和短语的数学表示,递归神经网络是一种机器学习模型,它可以利用内部状态来处理输入序列。每个演讲者都从自己的 RNN 实例开始,该实例不断更新给定新嵌入的 RNN 状态,使系统能够学习发言者共享的高级知识。
-
简介 该论文的作者声称核心算法实现了对于实时应用程序而言足够低的在线分类错误率(DER) – 在NIST SRE 2000 CALLHOME基准测试中为7.6%,而谷歌之前的方法为8.8%DER 的代码开源啦 谷歌研究人员的新方法通过递归神经网络(RNN)模拟发言者的嵌入(即,单词和短语的数学表示),RNN是一种机器学习模型,可以使用其内部状态来处理输入序列。每个发言者都以自己的RNN实例开始,该
-
我用Google API对自然对话的语音识别取得了很好的效果,但是对于Youtube视频或电影中的声音,识别效果很差或根本不存在。 在iPhone 4上录制西班牙语到英语的声音是可以识别的,但在电影中使用同一部手机几乎是不可能的,即使是一个角色在几乎没有背景噪音的情况下说话的场景。只有一次成功。 我试图清理声音与SoX(声音交换)使用噪声和comand efects,没有任何成功。 有什么想法吗?
-
我正在开发一个android应用程序,它将监听语音命令并相应地触发动作。 以下是一些疑问: > 谷歌语音识别离线库是否可用于android应用程序 我们能创建自己的词汇词典吗 应用程序应在脱机模式下工作(无Internet)。
-
我正在玩Google Cloud Speech API。我想知道我是否使用python语音识别库并调用google cloud语音API,这仍然是使用API的有效方式吗?我只想转录文本。 我对它们之间的区别感到困惑,如果我只想转录音频,是否有任何建议的方法。 使用Python语音识别: 不使用Python SpeechRecognition:
-
如果可能的话,我需要一些意见或建议。我有一个使用语音识别api和媒体记录器的应用程序。该应用程序的要点是当用户说“注意”时,它会记录语音消息,直到用户说“完成”。之后,应用程序将语音消息保存到手机中。 我目前有一个带有按钮(记录、保存、停止、完成)的弹出框,用户可以手动按下按钮来记录他们的语音信息。我正在考虑完全改造用户拥有完全语音控制的应用程序。所以基本上,它越免提越好。 我从这里开始研究连续语
-
我正在尝试从shell命令使用Google的语音识别API,但我遇到了问题。 我的Shell文件包含以下代码: 记录-D plughw: 1,0-q-f cd-t wav-R 16000|flac-f--Best--samplughw=16000-s-otest.flac wget-q-U“Mozilla/5.0”--文件后测试。flac--标题“内容类型:音频/x-flac;速率=16000”-
-
我正在尝试制作一款可以通过语音识别停止的闹钟Android应用程序。为此,我正在使用Google语音识别API(这段代码可以连续进行语音识别)。 它工作得很好,直到我同时演奏音乐。在这种情况下,语音识别的效率会大大降低。 这个问题是合乎逻辑的,因为音乐会增加一些噪音,使识别变得更加困难。但是由于播放的音乐是已知的,我想知道是否有可能告诉谷歌尝试忽略这些额外的噪音。我知道信号处理中存在一些滤波器来做