
Marp是一个比现有Hadoop分布式文件系统还要快三倍的产品,并且也是开源的。Mapr配备了快照,并号称不会出现SPOF单节点故障,且被认为是与现有HDFS的API兼容。因此非常容易替换原有的系统。
MapR是MapR Technologies, Inc的一个产品,号称下一代Hadoop,使Hadoop变为一个速度更快、可靠性更高、更易于管理、使用更加方便的分布式计算服务和存储平台,同时性 能也不断提高。它将极大的扩大了Hadoop的使用范围和方式。它包含了开源社区的许多流行的工具和功能,例如Hbase、Hive。它还100%和 Apache Hadoop的API兼容。它能够为客户节约一半的硬件资源消耗,使更多的组织能够利用海量数据分析的力量提高竞争优势。目前有两个版本,M3和M5,其 中M3是免费的,M5为收费版,有试用期。具体功能差别见:http://www.mapr.com/products/mapr-editions.html。
MapR的整体结构:
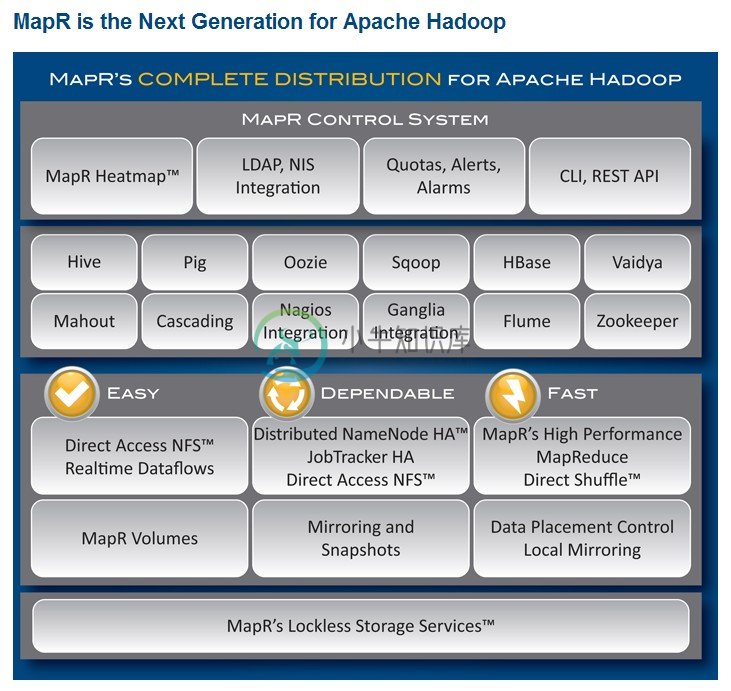
-
hadoopde mapr MapR Streams是一个新的分布式消息传递系统,用于大规模流式传输事件数据,并且已集成到MapR融合平台中。 MapR Streams使用Apache Kafka API,因此,如果您已经熟悉Kafka,就会发现开始使用MapR Streams特别容易。 尽管MapR Streams通常使用Apache Kafka编程模型 ,但仍存在一些关键差异。 例如,在Map
-
mapr-fs 架构 MapR Streams和MapR-DB都是MapR融合数据平台中非常激动人心的开发。 在这篇博客文章中,我将向您展示如何获取Ruby代码以与MapR-DB和MapR Streams进行本机交互。 我是Ruby开发人员,并且HBase和Kafka的现有Ruby客户端/库在MapR等效项下无法正常工作。 因此,我着手寻找一种方法来使Ruby代码与这两种MapR技术进行本地对话。
-
MapR Streams和MapR-DB都是MapR融合数据平台中非常激动人心的开发。 在此博客文章中,我将向您展示如何获取Ruby代码以与MapR-DB和MapR Streams进行本机交互。 我是Ruby开发人员,并且HBase和Kafka的现有Ruby客户端/库在MapR等效项下无法正常工作。 因此,我着手寻找一种方法来使Ruby代码与这两种MapR技术进行本地对话。 我决定尝试将Java示
-
MapR生态系统软件包2.0(MEP)随附了一些与MapR流有关的新功能: 用于MapR Streams的Kafka REST代理为MapR Streams和Kafka集群提供RESTful接口,从而易于使用和产生消息以及执行管理操作。 Kafka Connect for MapR Streams是一个实用程序,用于在MapR Streams与Apache Kafka和其他存储系统之间流式传输数据
-
一、MapReduce概述 Hadoop MapReduce 是一个分布式计算框架,用于编写批处理应用程序。编写好的程序可以提交到 Hadoop 集群上用于并行处理大规模的数据集。 MapReduce 作业通过将输入的数据集拆分为独立的块,这些块由 map 以并行的方式处理,框架对 map 的输出进行排序,然后输入到 reduce 中。MapReduce 框架专门用于 <key,value> 键值
-
Dubbo 是阿里巴巴公司开源的一个Java高性能优秀的服务框架,使得应用可通过高性能的 RPC 实现服务的输出和输入功能,可以和 Spring框架无缝集成。不过,略有遗憾的是,据说在淘宝内部,dubbo由于跟淘宝另一个类似的框架HSF(非开源)有竞争关系,导致dubbo团队已经解散(参见http://www.oschina.net/news/55059/druid-1-0-9 中的评论),反到是
-
类型 实现框架 应用场景 批处理 MapReduce 微批处理 Spark Streaming 实时流计算 Storm
-
其于职业介绍所、工头、工人、工作模型的分布式计算框架。 职业介绍所有两种,一种是本地职业介绍所,一种是远程职业介绍所。顾名思义,本地职业介绍所就是在当前计算机上的,远程职业介绍所用于连接到远程职业介绍所的。 工人、工头都可以加入到职业介绍所,所以加到本地或远程种业介绍所都是可以的。 在同一个职业介绍所中,具有同样类型的工人、工头和工作都存在的时候,工作就可以被安排下去执行。当然,有两种安排方式,一
-
主要内容:1.RPC流水线工程,2.RPC 技术选型,3.如何设计 RPC1.RPC流水线工程 ① Client以本地调用的方式调用服务 ② Client Stub接收到调用后,把服务调用相关信息组装成需要网络传输的消息体,并找到服务地址(host:port),对消息进行编码后交给Connector进行发送 ③ Connector通过网络通道发送消息给Acceptor ④ Acceptor接收到消息后交给Server Stub ⑤ Server Stub对消息进行解码,
-
在前面的章节里,我们已经学习了如何使用不同的打分公式,也了解了使用这些打分公式的好处。我们也学习了何如使用不同的倒排表结构来改变索引数据的方式。此外,我们也学习了自如应用近实时搜索和数据实时获取(real-time GET),了解了检索器(searcher)重启(reopen)背后的意义。我们也探讨了多语言数据的处理,也学习了配置事务日志来实现业务需求。最后,我们学习段合并(segments me