

Apache Traffic Control 是一个分布式、可扩展的冗余解决方案,可用于构建、监视和配置大型内容交付网络(CDN)。项目起源于 Traffic Server ,实现了现代 CDN 的所有核心功能。
借助 Traffic Control,运营商可以设置一个内容分发网络,为用户快速高效地提供高质量的 Live 和 VOD 流媒体视频。
功能特性:
-
降低延迟:找到更靠近用户的缓存和内容可减少传送内容所需的往返时间。
-
降低带宽成本:在内存和磁盘上缓存内容可减少原始服务器和瓶颈链接上的负载。
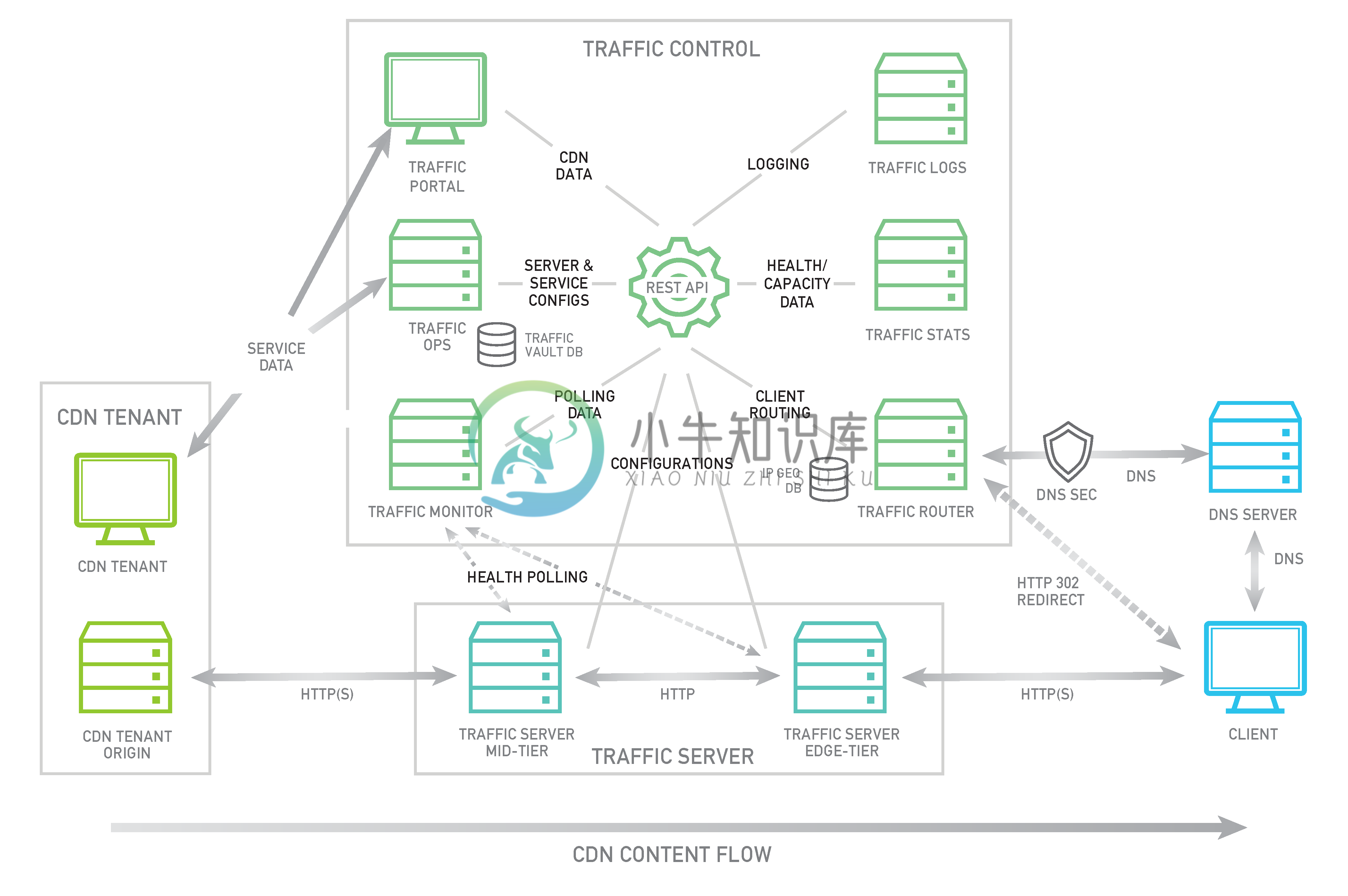
-
http://people.apache.org/~zym/trafficserver/FAQ.html 第一次用TS? 如何单机节点搭建reverse proxy模式的服务? 修改records.config文件 CONFIG proxy.config.cluster.ethernet_interface STRING eth0, 根据机器的配置将eth0修改为实际的网络接口(后续版本或RPM包
-
4.0.x新特性 在storage.config中标注磁盘 此功能的目的是允许将内容分配给特定磁盘。比如,使用storage.config标注,在hosting.config和volumes.config规则里,你可以强制使 某些URL去响应的SSD硬盘。 HTTP事务缓冲控制 为了避免潜在的内存消耗问题,当buffer的使用超过束缚则事物可被设成扼杀节流。这也可以用作每个事务的粗略带宽节流,因为
-
1. DIRECTORY STRUCTURE traffic/ ............... top src dir |-- ci/ ................ quality assurance and other CI tools and configs |-- cmd/ ............... various command applications
-
需求:通过User Agent判断手机用户,重定向到手机页面。 首先看github上面的例子,或者直接看官网。 其实很简单,直接来吧 #判断是否有手机ua关键字的,举了些例子。 function isMobile(userAgent) ua_array = {'android','iphone','ipad','mqqbrowser','windows phone','huawei
-
关于TrafficServer Cluster原理可以查阅http://blog.chinaunix.net/uid-10249062-id-3243299.html,这篇博文已经描述的非常清晰 1、修改records.config配置 配置cluster模式 LOCAL proxy.local.cluster.type INT 1 默认是3 配置cluster 监听端口,默认为8086 C
-
编译运行环境:CentOS 7.1.1503 1.安装依赖包 yum install tcl-devel libxml2-devel openssl-devel pcre-devel gcc-c++ 2.下载解压压缩包,编译 wget http://mirror.bit.edu.cn/apache/trafficserver/trafficserver-6.0.0.tar.bz2 tar -jxv
-
需要的工具: centos 7.x以上的镜像文件 本地VMware 15.5以上 Navicat Premium 使用XSHELL 7和XFTP 其他软件都可 Wechat_devtool (微信开发者工具) ego微商客户端源码 相关软件和源码: hi,这是我用百度网盘分享的内容~复制这段内容打开「百度网盘」APP即可获取 链接:https://pan.baidu.com/s/1U8VrsKr-
-
参考官方FAQ进行设置: https://cwiki.apache.org/confluence/display/TS/FAQ#FAQ-http_ui 这里也有一篇: https://blog.zymlinux.net/index.php/archives/756 关键,关键,关键 在浏览器访问的时候输入 http://localhost:8080/cache/ 一定不要忘了最后那个斜杠 "/
-
robotframework封装关键字用于控制ats ats的控制主要包括: 1、更新配置文件、重新加载配置文件 2、启动、停止、重启 3、清除ats缓存 前情回顾:控制ats之前、首先需要一个建立一个ssh链接 http://blog.csdn.net/zpeng421x/article/details/73330816 具体封装: -------------------------------
-
本文向大家介绍Java分布式session存储解决方案图解,包括了Java分布式session存储解决方案图解的使用技巧和注意事项,需要的朋友参考一下 前言 本文主要探讨集群后不同Web服务器获取Session数据的问题解决方案。 Session Stick Session Stick 方案即将客户端的每次请求都转发至同一台服务器,这就需要负载均衡器能够根据每次请求的会话标识(SessionId)
-
主要内容:1.2PC,2.三阶段提交(3PC),3.补偿事务(TCC),4.本地消息表,5.消息事务,6.最大努力通知,7.Sagas 事务模型1.2PC 两阶段提交 mysql是通过日志系统完成事务的。就是两阶段提交:undolog和binlog的两阶段提交。 两阶段协议可以用于单机集中式系统,由事务管理器协调多个资源管理器;也可以用于分布式系统,由一个全局的事务管理器协调各个子系统的局部事务管理器完成两阶段提交。 第一阶段:投票阶段 1.协调者写命令进写入日志 2.协调者发一个prepare
-
问题内容: 我的任务是为可大规模扩展的分布式共享内存(DSM)应用程序构建原型。原型仅用作概念验证,但我想通过选择稍后在实际解决方案中使用的组件来最有效地利用我的时间。 该解决方案的目的是获取来自外部源的数据输入,将其搅动并使结果可用于许多前端。这些“前端”将仅从缓存中获取数据并提供服务,而无需额外的处理。该数据的前端命中量实际上可以是每秒数百万。 数据本身非常不稳定。它可以(并且确实)快速变化。
-
主要内容:1.难题与方案,2.具体措施,3.九种技术架构1.难题与方案 1、亿级流量电商网站的商品详情页系统架构 面临难题:对于每天上亿流量,拥有上亿页面的大型电商网站来说,能够支撑高并发访问,同时能够秒级让最新模板生效的商品详情页系统的架构是如何设计的? 解决方案:异步多级缓存架构+nginx本地化缓存+动态模板渲染的架构 2、redis企业级集群架构 面临难题:如何让redis集群支撑几十万QPS高并发+99.99%高可用+TB级海量数据+企业级数
-
问题内容: 我们的生产Web服务器有一台运行Windows Server 2003的服务器。我们的网站具有不同的模块,每个模块都在其自己的应用程序池中运行。由于每个模块都有自己的缓存,而且经常有多个模块缓存相同的项目,因此这使缓存有点问题。问题是,当在一个模块中更改了缓存中的项目时,无法轻松地刷新缓存同一项目的另一个模块。 我们的网站是用ASP.NET 4.0编写的,我们使用标准的HttpRunt
-
了解 CSS 中属性的值及其特性, 透彻分析问题和需求才可以选择和设计最适合的布局解决方案。 居中布局 水平居中 子元素于父元素水平居中且其(子元素与父元素)宽度均可变。 inline-block + text-align <div class="parent"> <div class="child">Demo</div> </div> <style> .child { disp
-
本文向大家介绍详解SpringBoot基于Dubbo和Seata的分布式事务解决方案,包括了详解SpringBoot基于Dubbo和Seata的分布式事务解决方案的使用技巧和注意事项,需要的朋友参考一下 1. 分布式事务初探 一般来说,目前市面上的数据库都支持本地事务,也就是在你的应用程序中,在一个数据库连接下的操作,可以很容易的实现事务的操作。 但是目前,基于SOA的思想,大部分项目都采用微服务
-
问题内容: 因此,我刚刚阅读了有关redlock的文章。据我了解,它需要3台独立的机器才能工作。独立表示它们是指所有计算机都是主计算机,并且它们之间没有复制,这意味着它们正在提供不同类型的数据。那么,为什么我需要锁定在充当主服务器的三个独立Redis实例中存在的密钥?我需要使用redlock的用例是什么? 问题答案: 那么,为什么我需要锁定在三个独立的Redis实例中充当主键的密钥? 这并不是说您