
Tendis 是腾讯互娱 CROS DBA 团队 & 腾讯云数据库团队自主设计和研发的分布式高性能 KV 存储数据库,兼容 Redis 核心数据结构与接口,可提供大容量、低成本、强持久化的数据库能力,适用于兼容 Redis 协议、需要大容量且较高访问性能的温冷数据存储场景。Tendis 目前已经被应用到腾讯内、外部大型项目中。
集群架构
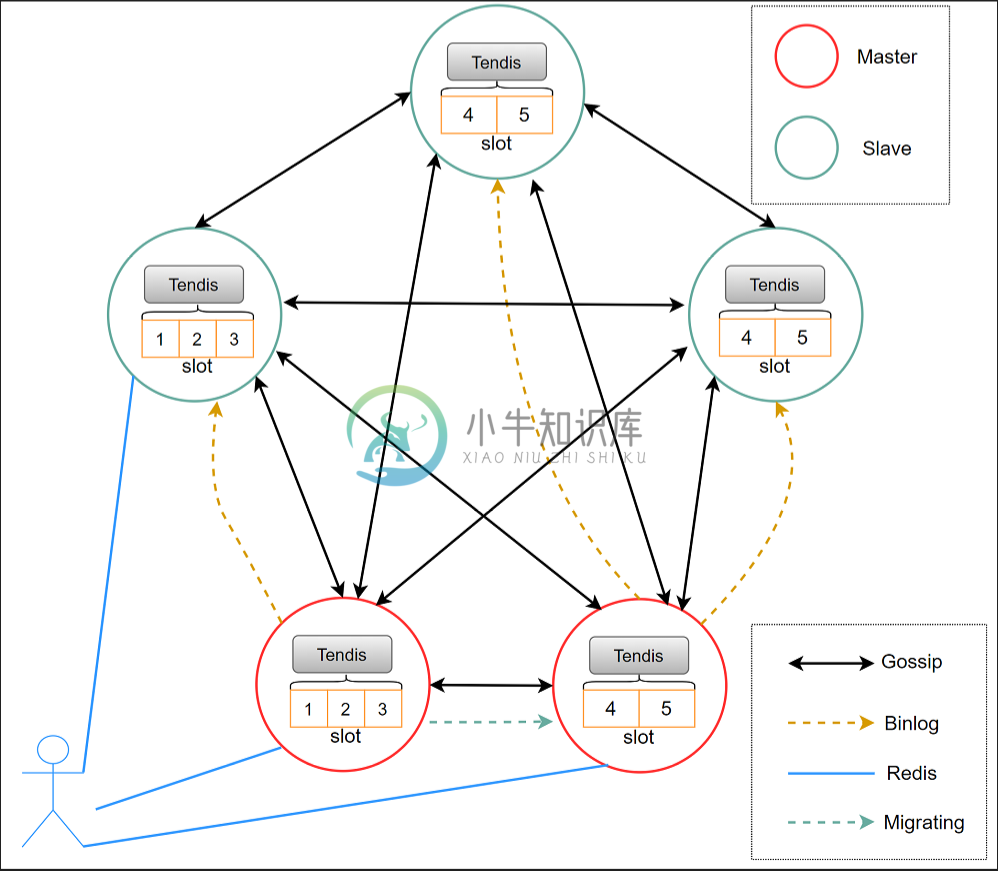
Tendis 使用去中心化集群架构,每个数据节点都拥有全部的路由信息,用户可以访问集群中的任意节点,并且通过 redis 的 move协议,最终路由到正确的节点。
每个 Tendis 节点维护各自的 slot 数据,任意两个 master 节点之间的 slot 不重复,master 节点之间支持基于 slot 的数据搬迁,主备节点之间通过 binlog 实现数据复制。
所有节点之间通过gossip协议进行通讯,类似于redis cluster的分布式实现,所有节点通过gossip协议通讯,可指定hashtag来控制数据分布和访问,使用和运维成本极低。
适用场景
-
兼容Redis协议,需要大容量且较高访问性能的温冷数据存储场景
-
适合成本为主要考虑因素,业务数据有高持久化要求的业务场景
-
解决原生Redis固有的fork问题而预留部分内存问题
主要特性
- 兼容Redis协议。完全兼容redis协议,支持redis主要数据结构和接口,兼容大部分原生Redis命令。
- 持久化存储。使用rocksdb作为存储引擎,所有数据以特定格式存储在rocksdb中,最大支持PB级存储。
- 去中心化架构。类似于redis cluster的分布式实现,所有节点通过gossip协议通讯,可指定hashtag来控制数据分布和访问,使用和运维成本极低。
- 水平扩展。集群支持增删节点,并且数据可以按照slot在任意两节点之间迁移,扩容和缩容过程中对应用运维人员透明,支持扩展至1000个节点。
- 故障自动切换。自动检测故障节点,当故障发生后,slave会自动提升为master继续对外提供服务。
- Tendis冷热混合存储关键组件。得益于Tendis存版的设计和内部优化,Redis和Tendis存储版可以一起工作成为Tendis冷热混合存储。混合存储区非常适用于KV存储场景,并平衡了性能和成本。对于redis占用大量存储空间的冷数据降冷后可以最多减少80%的成本,同时保证了热数据在redis的访问性能。
项目规划
-
持续完善对Redis的兼容性,包括支持LUA等命令
-
进一步提升Tendis的性能,减少rocksdb本身的性能抖动问题。
-
探索更多软硬结合方案,基于新硬件特性,发挥更大的数据库性能。
-
支持异构数据互通能力,降低异构数据库的迁移成本
-
运维管理能力全面提升,PASS能力持续增强
-
简介 基于国产化技术浪潮,关注到了腾讯开源的tendis 使用完全兼容redis协议,几乎不用修改源码 同样支持去中心化的集群架构 主要特性 兼容redis协议,支持大多数Redis命令 支持持久化,可用rocksdb作为存储引擎 去中心化,节点间通过gossip协议通信 支持水平扩展,扩缩容可对运维透明 支持高可用,slave可自动提升为master 支持冷热混合存储,可与Redis组合成冷热混
-
—- 分布式锁:(一般3种实现方式) 1.数据库乐观锁; 2.基于redis的分布式锁。 3.基于zookeeper的分布式锁。 分布式锁 区分于 进程锁, 线程锁。。 进程锁(系统中多个进程之间对资源使用到的管理) 线程锁(进程中多个线程对资源共享) 分布式锁:分布式系统中多个进程之间互相干扰。用分布式协调技术管理进程调度。(这个技术就是分布式锁) —- mysql的并发控制(用到了很多策略)
-
1、主机信息 hostname ip port node01 192.168.56.101 51001、51002、51003 node02 192.168.56.102 51001、51002、51003 node03 192.168.56.103 51001、51002、51003 注意:tendis和redis-cluster 一样,在服务启动之后会默认使用一个port + 10000 。例
-
分布式支持 数据访问层支持分布式数据库,包括读写分离,要启用分布式数据库,需要开启数据库配置文件中的deploy参数: return [ // 启用分布式数据库 'deploy' => 1, // 数据库类型 'type' => 'mysql', // 服务器地址 'hostname' => '192.168.1.1,19
-
一面 11.1 分布式存储 阿里天池比赛,问了一些模块的优化 问存储项目 问TinyKV 项目 操作系统:cpu cache,false sharing,gdb C++:移动语义,std::map,rbtree和b+tree区别。 perf 观察程序性能 算法题:二叉树的路径和 二面 11.2 leader 面 开局先选方向:DB,分布式,操作系统,体系结构,计算机网络。选了分布式,狂问raft
-
之前的秋招面经:深信服 Go 开发面经(已 offer) bg:专升本+ACM银牌+三个项目(一个毕设的KV分离LSM-Tree,一个6824的分布式KV,一个OJ) 某小厂,存储方向技术积累还不错,避免定位就不写具体名字了。自己也一直比较憧憬做 infra 吧,不想写 CRUD 业务,所以就投了。面试内容都是事后回忆,可能有遗漏或记错的 一面 50min 自我介绍 项目实现细节、设计考量、优化(
-
Kdb+ 是来自 Kx Systems Inc 的高性能列式数据库。 kdb+ 旨在捕获,分析,比较和存储数据 - 所有这些都是高速和大量数据。
-
主要内容:并行化集合,外部数据集RDD(弹性分布式数据集)是Spark的核心抽象。它是一组元素,在集群的节点之间进行分区,以便我们可以对其执行各种并行操作。 有两种方法可以用来创建RDD: 并行化驱动程序中的现有数据 引用外部存储系统中的数据集,例如:共享文件系统,HDFS,HBase或提供Hadoop InputFormat的数据源。 并行化集合 要创建并行化集合,请在驱动程序中的现有集合上调用的方法。复制集合的每个元素以形成
-
主要内容:1.Kafka存储难度,2.Kafka 的存储选型分析,3.Kafka 的存储设计Kafka使用的是Logging(日志文件)这种很原始的方式来存储消息 对于存储设计有一些知识点: Append Only、Linear Scans、磁盘顺序写、页缓存、零拷贝、稀疏索引、二分查找等等。 Append Only Data Structures 的一些存储系统比如HBase, Cassandra, RocksDB 1.Kafka存储难度 Kafka 通过简化消息模型,将自己退化成了一