
Iveely Search Engine 是一款纯C#实现的搜索引擎。Iveely的中文翻译:爱为您。英文全称:I void everything , enjoy loving you! 希望更多的搜索引擎爱好者加入进来,感受分享的快乐。我期望的Iveely目标是,不是给用户一堆结果让用户去发现最适合自己的,我希望是返回的就是用户 最想要的,用户完全无需筛选,所以Iveely Search Engine 永远没有分页,更希望它能嵌入机器人思维中,成为人类的良师益友。当然现在依然处于文本搜索阶段。
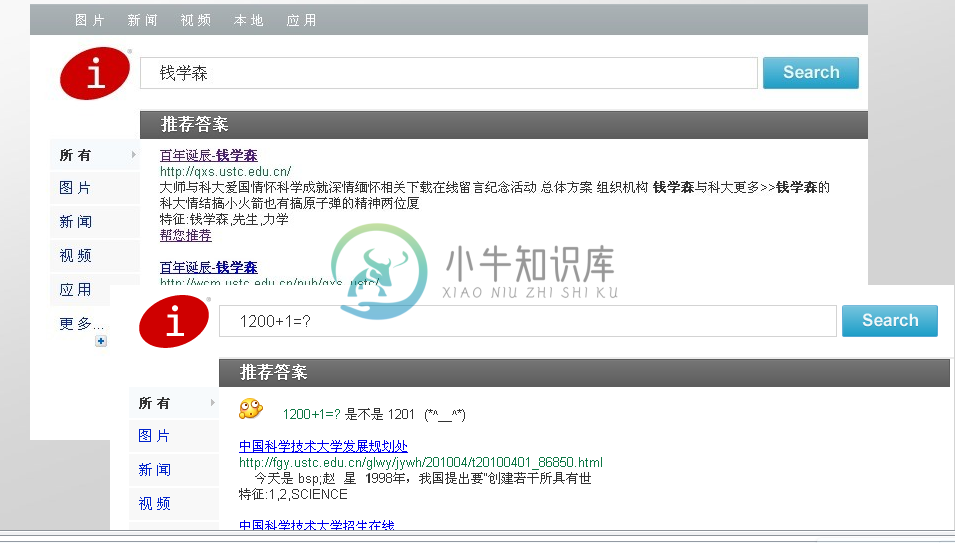
上图是Iveely Search Engine 0.1.0版本的截图,目前只有文本搜索部分,其余的新闻、视频等还没有完全做好,主要是统一的存储模型没有找到。下面大致说一个项目的基础结构:

上面主要分为三大块,刚好对应着Iveely搜索引擎中的三个运行步骤(当您下载程序后的运行方式就是按照上面上个步骤来的)。
下面介绍一下整个解决方案中,各个项目的含义。
"IveelySE", "IveelySE\IveelySE.csproj", 是搜索服务建立部分,搜索的入口是从这里开始的。
"IveelySE.AI", "IveelySE.AI\IveelySE.AI.csproj", 搜索的人工智能部分,类似于专家系统。例如输入101+90=?就是通过这个项目计算出来的。
"IveelySE.Classify", "IveelySE.Classify\IveelySE.Classify.csproj",是搜索引擎中文本分类(聚类)的实现部分。
"IveelySE.Common", "IveelySE.Common\IveelySE.Common.csproj",是搜索引擎中共用部分的提取。
"IveelySE.Config", "IveelySE.Config\IveelySE.Config.csproj", 是搜索引擎中的配置部分,尽可能的配置在这个项目中实现。
"IveelySE.Grammar", "IveelySE.Grammar\IveelySE.Grammar.csproj", 是搜索引擎中的语法分析部分,例如:site、filetype等等。
"IveelySE.Index", "IveelySE.Index\IveelySE.Index.csproj", 是搜索引擎中的索引部分,原数据的整理主要在这里实现,倒排序等也是。
"IveelySE.Liquidate", "IveelySE.Liquidate\IveelySE.Liquidate.csproj",是语言处理部分,例如停用词过滤、敏感词等等的处理。
"IveelySE.Segment", "IveelySE.Segment\IveelySE.Segment.csproj", ISE中的分词部分,包含词库分词和隐马尔可夫分词。
"IveelySE.Server", "IveelySE.Server\IveelySE.Server.csproj", ISE中关于网络通信传输部分。
"IveelySE.Spider", "IveelySE.Spider\IveelySE.Spider.csproj", 这是网络爬虫,即数据搜集部分。
"IveelySE.IDFS", "IveelySE.IDFS\IveelySE.IDFS.csproj", 这是分布式文件系统部分,包括MapReduce的实现都将在此(此版本无效)。
"IveelySE.BigData", "IveelySE.BigData\IveelySE.BigData.csproj", 这是大数据处理部分(此版本无效)。
"IveelySE.BigData.Common", "IveelySE.BigData.Common\IveelySE.BigData.Common.csproj", 大数据处理的共同引用部分(此版本无效)。
"IveelySE.BigData.FileSystem", "IveelySE.BigData.FileSystem\IveelySE.BigData.FileSystem.csproj",大数据处理的虚拟文件系统(此版本无效)。
"IveelySE.BigData.MasterNode", "IveelySE.BigData.MasterNode\IveelySE.BigData.MasterNode.csproj", 大数据存储的主节点部分(此版本无效)。
"IveelySE.BigData.StoreNode", "IveelySE.BigData.StoreNode\IveelySE.BigData.StoreNode.csproj", 大数据存储的子节点部分(此版本无效)。
"IveelySE.Search", "IveelySE.Search\IveelySE.Search.csproj", 搜索的本地实现部分,无需Web,只要用于内部调试。
"IveelySE.Web", "IveelySE.Web\IveelySE.Web.csproj",搜索的Web端实现,界面采用ask的界面(在0.2.0版本中已经移除)。
目前已经发布了0.2.0版本, Iveely Search Engine 的0.2.0版本最大的特点就是“任务驱动式一键式运行”,简单的说就是,在无人监督的情况下,设定好您的参数,一个本地化的完整搜索引擎就可以利用起来,包含数据、索引更新等等都自动化完成。相对于0.1.0它在以下方面有一定的提升:
1. 添加“帮您推荐” 功能。在搜索结果显示的时候,当命中最佳的网页时,该网页将会为您推荐它觉得其它最好的网页。例如:您到一家餐馆吃饭,这家餐馆非常适合您的口味,那么它将推荐它觉得最好的其它餐品给您。就是这个道理。
2. 添加“缓存处理”功能。在0.1.0的搜索过程中,所有的每次请求,都将从索引中选出合适的网页编号,然后根据网页编号提取出数据,这实际是不合算的,在0.2.0种,添加了缓存策略,在最近搜索过的关键字中直接提取上次的结果缓存,无需从头至尾到数据中提取。主要采用数据结构:哈希双链表。
3. 添加项目IveelySE.Run.Task,主要是讲所有的执行任务以任务机器的方式,选择间隔时间执行以及定期更新数据。例如:爬虫任务,可设定每次完成任务之后,6小时候再重新爬行一次。还有索引系统,定期更新系统,定期更新缓存等等,都即将依赖于IveelySE.Run.Task运行。
4. IveelySE.Web,新建了IveelySE.InternetService,IveelySE.Web是我们搜索的展示,但是我们将其移出,采用网络服务的方式,你需要查看搜索结果,将不再依赖于网页,只需要浏览器中输入http://127.0.0.1:8088/query=您的关键字,即可。
以上是ISE 0.2.0 相对于0.1.0版本的不同之处。
无数的错误或者Bugs一定会让大家崩溃,但是请您放心,我们(更多的热爱开源事业的人士)会积极的修改其中的Bug,当然项目中也参杂了其它开源项目的东西,例如:Html分析采用的是HtmlAgilityPack。希望和更多地朋友一起分享我们的快乐。谢谢大家!项目地址:http://iveelyse.codeplex.com/
-
原文链接:http://www.cnblogs.com/liufanping/archive/2012/08/12/2635353.html 在上周发布的Iveely Search Engine 0.1.0版本中,未包含IveelySE的搜索缓存策略,如果没有此缓存,那么每次搜索都将是从数据系统中分析读取结构,将是件很麻烦的事情。今天花了2个小时,写了下缓存策略的Codes。搜索缓存的主要工作是将
-
搜索引擎分为两部分: 时间筛选 和 搜索引擎 (详情) 1.时间筛选 便捷按钮有今日、昨日、前日、上周 X、近七天,并且能自定义选择时间段来得出想要的结果报表 2.搜索引擎 (时间段详情) 选择日期,查看来自对应时间段内,各个搜索引擎的访问量比例
-
我有大量相同类型的实体,每个实体都有大量属性,并且我只有以下两种选择来存储它们: 将每个项存储在索引中并执行多索引搜索 将所有enties存储在单个索引中,并且只搜索1个索引。 一般而言,我想要一个时间复杂度之间的比较搜索“N”实体与“M”特征在上述每一种情况!
-
lucene 和 es 的前世今生 lucene 是最先进、功能最强大的搜索库。如果直接基于 lucene 开发,非常复杂,即便写一些简单的功能,也要写大量的 Java 代码,需要深入理解原理。 elasticsearch 基于 lucene,隐藏了 lucene 的复杂性,提供了简单易用的 restful api / Java api 接口(另外还有其他语言的 api 接口)。 分布式的文档存储
-
搜索引擎 关键参数 报告 method metrics(指标, 数据单位) 其他参数 搜索引擎 source/engine/a pv_count (浏览量(PV)) pv_ratio (浏览量占比,%) visit_count (访问次数) visitor_count (访客数(UV)) new_visitor_count (新访客数) new_visitor_ratio (新访客比率,%) ip
-
更改历史 * 2018-05-07 胡小根 初始化文档 1 历史、现状和发展 1.1 历史 1.2 现状 1.3 发展 难点:预测发展方向。 2 安装和使用 2.1 安装 2.2 使用 创建index和type 上传单条数据 批量上传数据 查询 2.3 示例 2.4 最佳实践 难点:最佳实践,超出于示例,应该归纳总结出积累的技巧。 3 同类技术对比 难点:归纳比对项 参考资料 El
-
元搜索引擎 原搜索引擎是通过一个统一的用户界面帮助用户在多个搜索引擎中选择和利用合适的搜索引擎来实现检索操作,是对分布于网络的多种检索工具的全局控制机制。 自己没搜索引擎,又想要大规模的数据源,怎么办?可以对百度搜索和谷歌搜索善加利用,以小搏大,站在巨人的肩膀上。有很多的应用场景可以很巧妙地借助百度搜索和谷歌搜索来实现,比如网站的新闻采集,比如技术、品牌的新闻跟踪,比如知识库的收集,比如人机问答系