
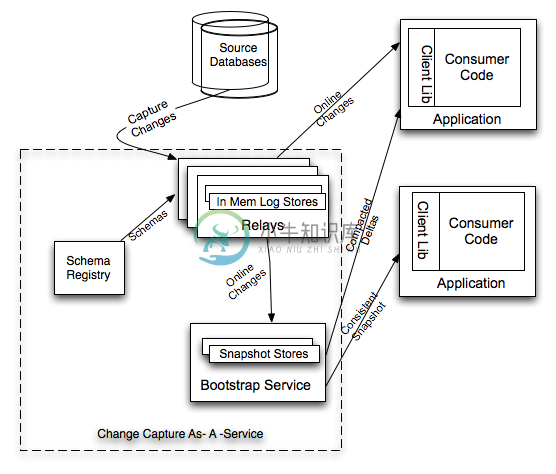
LinkedIn最近发布了一套源无关的分布式数据同步系统Databus。简单说,就是把交易数据同步到各个不同的应用中。一个大的特色是这系统采用pull模式从log中取得数据,以达到对生产系统最小影响。
-
[list][*][b]概述[/b][/list] 目前了解到基于Oracle的开源数据同步项目有yugong、databus、SymmetricDS,之前尝试了yugong,很容易上手。使用时需要注意两点:1、物化视图和回表查询对源库会产生比较大的影响;2、每一个表有一个单独的实例去处理整个流程,数据抽取、转换、入库不能分离;3、yugong设计的目的是为了去IOE,做切库使用,多次增量同步确认
-
databus 分为 relay bootstrap-producer(bst-producer) bootstrap-server(bst-server) client,他们之间的关系可以去网上找 这里主要介绍部署这四个工程的方法 1 relay 侦听端口为 11115 1.1 relay.properties databus.relay.container.httpPort=11115 dat
-
1. 下载源码 复制 ojdbc.jar 到相应的文件夹 git clone https://github.com/linkedin/databus/ sandbox-repo/com/oracle/ojdbc6/11.2.0.2.0/ojdbc6-11.2.0.2.0.jar 2. 在 subprojects.gradle 中 加上 options.addStringOption('encodi
-
package cn.com.wind.bdc.day5lx.util; /** * 向前端返回信息,支持链式调用 * Created by liangchen on 2020/10/28 13:58 */ public class DataBus { //信息详情 private String result_msg;// 查询成功 未查询到数据 报错 //成
-
Lock Redisson 分布式可重入锁,实现了 java.util.concurrent.locks.Lock 接口并支持 TTL。 RLock lock = redisson.getLock("anyLock"); // Most familiar locking method lock.lock(); // Lock time-to-live support // releases loc
-
分布式支持 数据访问层支持分布式数据库,包括读写分离,要启用分布式数据库,需要开启数据库配置文件中的deploy参数: return [ // 启用分布式数据库 'deploy' => 1, // 数据库类型 'type' => 'mysql', // 服务器地址 'hostname' => '192.168.1.1,19
-
接“设计模式综合实例分析之数据库同步系统(二)“。 6. 策略模式 由于表数据的同步方式有三种,分别是增量同步、先Delete后Insert方式、临时表方式,因此可以定义一个同步策略接口DataSynStrategy,并提供三个具体实现类:IncSynStrategy、DelAndInsSynStrategy和TempTableSynStrategy
-
接“设计模式综合实例分析之数据库同步系统(一)“。 3. 享元模式和单例模式 在数据库同步系统中,抽象类DBObjectSynchronizer表示需要同步的数据库对象,对于不同的数据库对象类型,提供了不同的子类实现,在数据库同步时可能有多个线程在同时进行同步工作,为了节省系统资源,可以使用享元模式来共享DBObjectSynchroizer对象,提
-
最近有很多朋友跟我聊到关于“在软件项目开发中如何合理使用设计模式”的问题,希望我能够给出一些相对比较完整的真实项目实例,为了满足大家的要求,在后续文章中,我将拿出几个较为复杂的实例与大家一起分享,有些项目是我参与开发的,有些项目是在我的指导下开发的,希望能给大家带来帮助!在此我也希望大家能够分享自己的一些设计模式使用心得和好的设计模式应用实例,可以整理一份给我(可发送到邮箱:wei
-
一个成功的技术,现实的优先级必须高于公关,你可以糊弄别人,但糊弄不了自然规律。 ——罗杰斯委员会报告(1986) 在本书的第一部分中,我们讨论了数据系统的各个方面,但仅限于数据存储在单台机器上的情况。现在我们到了第二部分,进入更高的层次,并提出一个问题:如果多台机器参与数据的存储和检索,会发生什么? 你可能会出于各种各样的原因,希望将数据库分布到多台机器上: 可扩展性 如果你的数据量、读取负载、写