
Rainbird 是 Twitter开发的一款分布式实时统计系统。
用处
Rainbird可以用于实时数据的统计:
1 统计网站中每一个页面,域名的点击次数
2 内部系统的运行监控(统计被监控服务器的运行状态)
3 记录最大值和最小值
性能要求
作为大型网站的分布式应用,需要具备以下性能:
1 极高的写入性能,可以达到100,000的WPS
2 非常高的读取性能,可以达到10,000s的RPS
3 高度的可扩展性,包括读取和存储等等,能够扩展到100+ TB的量级
4 读取速度响应间隔短,绝大多数的读取速度应该不超过100ms
系统组件
Rainbird一款基于Zookeeper, Cassandra, Scribe, Thrift的分布式实时统计系统,这些基础组件的基本功能如下:
1 Zookeeper,Hadoop子项目中的一款分布式协调系统,用于控制分布式系统中各个组件中的一致性。
2 Cassandra,NoSQL中一款非常出色的产品,集合了Dynamo和Bigtable特性的分布式存储系统,用于存储需要进行统计的数据,统计数据,并且提供客户端进行统计数据的查询。(需要使用分布式Counter补丁CASSANDRA-1072)
3 Scribe,Facebook开源的一款分布式日志收集系统,用于在系统中将各个需要统计的数据源收集到Cassandra中。
4 Thrift,Facebook开源的一款跨语言C/S网络通信框架,开发人员基于这个框架可以轻易地开发C/S应用。
整体设计
Rainbird的设计架构图如下:
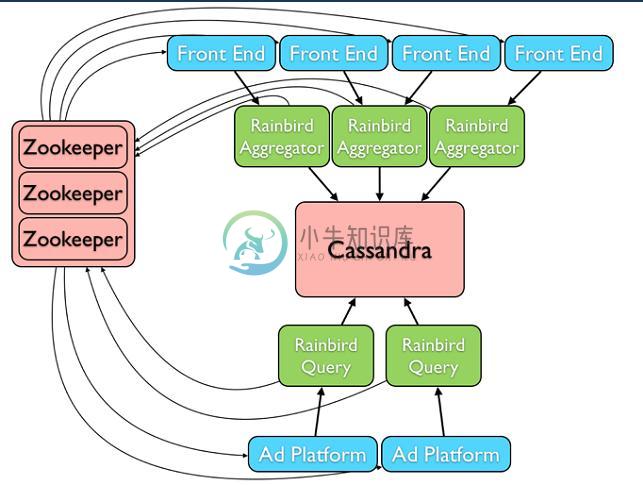
整个Rainbird系统中各个组件之间的协调和容灾处理由ZooKeeper负责,Cassandra负责整个数据的存储和统计。
Front End中部署了Scribe,收集需要统计的数据,然后将收集到数据实时地发生到Rainbird Aggregator中。
Rainbird Aggregator将缓存收集的数据(1M),并将缓存的数据进行一次预处理,然后再将数据一次性批量写入到Cassandra中。这里预处理的作用类似于MapReduce框架中的combiner的作用,在Maper端做Reduce。
Rainbird Query接受用户的查询请求,直接到Cassandra中查询已经统计好的数据返回给客户端。
-
ESP-LX模块控制器安装程序设置和操作指引-RainBird ESP-LX 模块控制器 安装、程序设置 和操作指南 PN 636611-010 安全信息 警告:必须在固定配线中安装断路器或断路开关以隔离控制 WARNING : A CIRCUIT BREAKER OR CUTOFF SWITCH IS TO 器。 BE PROVIDED IN THE FIXED WIRING TO ISOLAT
-
离开上一家公司两个月了,近日拿到以前的同事光屹写的文章,还是写的我,很感动也很感激,不敢独享,放在博客里,警醒自己。 ++++++++++++++++++++++++++++++++++++++++++++++++++++++++ Rainbird点滴 好工作意味着好收入。在解决了吃饭、房租、还贷、家用、储蓄这些问题之外,一份好工作更意味着好前程。但是工作为谁呢?是为别人还是为自己
-
主要内容:一、从一个新闻门户网站案例引入,二、推算一下你需要分析多少条数据?,三、黄金搭档:分布式存储+分布式计算这篇文章聊一个话题:什么是分布式计算系统? 一、从一个新闻门户网站案例引入 现在很多同学经常会看到一些名词,比如分布式服务框架,分布式系统,分布式存储系统,分布式消息系统。 但是有些经验尚浅的同学,可能都很容易被这些名词给搞晕。所以这篇文章就对“分布式计算系统”这个概念做一个科普类的分析。 如果你要理解啥是分布式计算,就必须先得理解啥是分布式存储,现在我们从一个小例子来引入。 比如说
-
我想创建一个基于AKKA的分布式电子邮件邮箱系统。当我的应用程序启动时,我想创建所有收件箱参与者,并在他们上启动调度器,以接收邮件的时间间隔为10秒。但是有一个问题是如何创建这些收件箱角色?是否可以在集群上创建actor或获得对它的引用(如果它存在的话)?Actor名称可以是数据库中的邮箱UUID,群集中只能存在一个具有特定UUID的Actor。 最重要的问题是如何在集群中创建以uuid为名称的a
-
被别人指出问题时,别管别人能不能做到,看别人说的对不对,然后完善自己。别人能不能做到是别人的事情,自己能不能做到关系到自己能否发展的更好。——hustlihaifeng Go语言号称是互联网时代的C语言。现在的互联网系统已经不是以前的一个主机搞定一切的时代,互联网时代的后台服务由大量的分布式系统构成,任何单一后台服务器节点的故障并不会导致整个系统的停机。同时以阿里云、腾讯云为代表的云厂商崛起标志着
-
数据存储容量的问题。 数据读写速度的问题。 数据可靠性的问题。 几种常见 RAID 的对比|名称|优点|缺点| |------|------|------| |RAID 0|使用 N 块磁盘的 RAID 0,将数据从内存写入磁盘时,将数据分成 N 块,并发写入,读取同理。所以,读写速度是单盘的 N 倍。|任何一块盘损坏,数据完整性破坏,数据不可用。| |RAID 1|数据写入磁盘时,将一份数据同时
-
万法皆空,因果不空。 随着摩尔定律碰到瓶颈,越来越多的系统要依靠分布式集群架构来实现海量数据处理和可扩展计算能力。 区块链首先是一个分布式系统。 中央式结构改成分布式系统,碰到的第一个问题就是一致性的保障。 很显然,如果一个分布式集群无法保证处理结果一致的话,那任何建立于其上的业务系统都无法正常工作。 本章将介绍分布式系统中一些核心问题的来源以及相关的工作。
-
一、介绍 HDFS (Hadoop Distributed File System)是 Hadoop 下的分布式文件系统,具有高容错、高吞吐量等特性,可以部署在低成本的硬件上。 二、HDFS 设计原理 2.1 HDFS 架构 HDFS 遵循主/从架构,由单个 NameNode(NN) 和多个 DataNode(DN) 组成: NameNode : 负责执行有关 文件系统命名空间 的操作,例如打开,
-
本文向大家介绍Hadoop 分布式存储系统 HDFS的实例详解,包括了Hadoop 分布式存储系统 HDFS的实例详解的使用技巧和注意事项,需要的朋友参考一下 HDFS是Hadoop Distribute File System 的简称,也就是Hadoop的一个分布式文件系统。 一、HDFS的优缺点 1.HDFS优点: a.高容错性 .数据保存多个副本 .数据丢的失后自动恢复
-
邂逅相遇 网络延迟 存之为吾 无食我数 —— Kyle Kingsbury, Carly Rae Jepsen 《网络分区的危害》(2013年) [TOC] 最近几章中反复出现的主题是,系统如何处理错误的事情。例如,我们讨论了副本故障切换(“处理节点中断”),复制延迟(“复制延迟问题”)和事务控制(“弱隔离级别”)。当我们了解可能在实际系统中出现的各种边缘情况时,我们会更好地处理它们。