
HStreamDB 是一款专为流式数据设计的, 针对大规模实时数据流的接入、存储、处理、分发等环节进行全生命周期管理的流数据库。
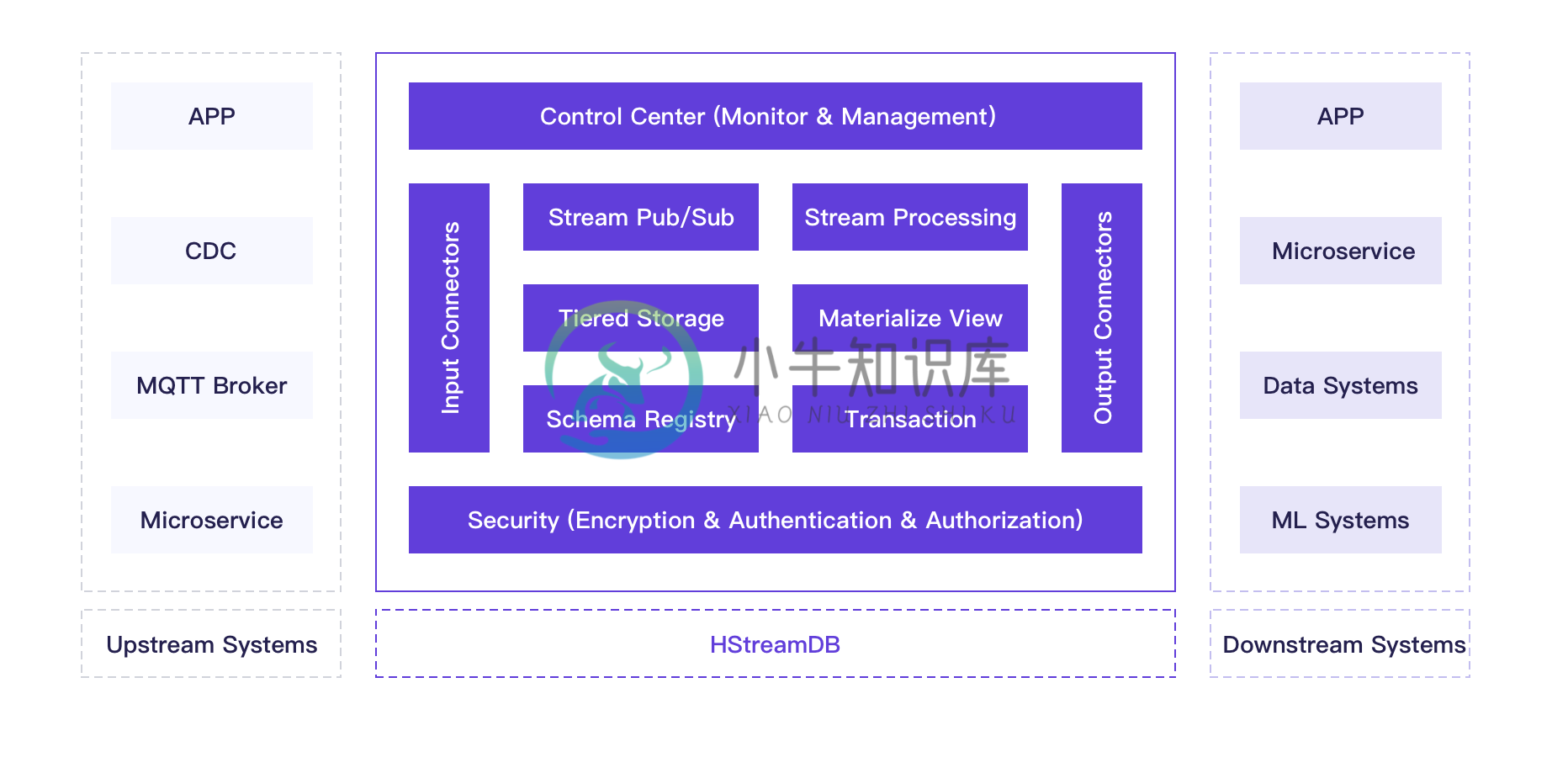
它使用标准 SQL (及其流式拓展)作为主要接口语言,以实时性作为主要特征,旨在简化数据流的运维管理以及实时应用的开发。
功能特性
- 基于 SQL 的数据流处理
- 数据流的物化查询
- 数据流管理
- 数据流的持久化存储
- 数据流的 Schema 管理
- 数据流的接入和分发
- 安全机制
- 监控和运维工具

-
本月,HStreamDB 团队正式发布了 v0.8,并启动了 v0.9 的开发工作,v0.9 将在集群、外部系统集成、分区等方面带来重大改进。本月我们主要完成了新的集群机制和数据集成框架 HStream IO 的设计和初步开发工作,并启动了新的 Python 客户端开发。同时正式发布了 Erlang 客户端的 0.1 版本,以及新增了 Helm 和阿里云的部署支持。 HServer 集群机制改进
-
HStreamDB 最新版本 v0.9 现已正式发布! v0.9 主要有以下亮点更新: stream 分区模型扩展,支持用户直接访问分区上指定位置的数据; 新增 HStreamDB 的内部数据集成框架 HStream IO; 集群转用基于 SWIM 的成员发现和故障检测机制; 全新的流处理引擎; 升级了 Java 和 Go 客户端,并新增了 Python 客户端。 Stream 分区模型扩展 v0
-
HStreamDB v0.8 现已正式发布! 在 0.8 版本中,我们优化了读写性能,提升了长时间运行的稳定性,新增了基于 mTLS 的安全性支持、多项监控指标、Admin Server、Benchmark Tools 和 Terraform 部署支持,并包含 stream 和 subscription 上的多项配置新增和功能改进,同时带来了多种语言(Java、Go、Erlang)的客户端更新。
-
继月初 HStreamDB 0.9 正式发布之后,HStreamDB 团队投入了新的 v0.10 的开发周期。本月主要新增了端到端压缩、CLI 支持 TLS 等功能,并修复了多项已知问题,同时新的 Haskell gRPC 框架以及云原生的全托管流数据库服务 HStream Cloud 也正在开发中。 支持端到端压缩 之前版本的 HStreamDB 支持 HServer 端的数据压缩,即数据在发送
-
在之前的 Newsletter 中,我们对 HStreamDB v0.7 正在开发或已经完成开发的一些新功能进行了简单介绍。HStreamDB v0.7 致力于改进 HServer 集群的稳定性与可用性以及引入新的透明分区功能,提高用户的使用体验。 本月我们完成了 HStreamDB v0.7 开发和发布的收尾工作,包括透明分区 Stage1 的实现、资源删除的逻辑改进、提供新的 Admin CL
-
本月,HStreamDB 团队主要在进行 v0.9 的最后开发和发布准备工作,对 v0.9 即将带来的 stream 分区模型改进、新集群机制、HStream IO 等新特性进行了进一步的完善和测试,同时也将主要的客户端升级到适配 v0.9。 Stream 分区模型改进 在之前版本中,HStreamDB 采用透明分区模型,每个 stream 内的分区数是根据写入负载的情况动态调整的,且 strea
-
严格的单向数据流是 Redux 架构的设计核心。 这意味着应用中所有的数据都遵循相同的生命周期,这样可以让应用变得更加可预测且容易理解。同时也鼓励做数据范式化,这样可以避免使用多个且独立的无法相互引用的重复数据。 如果这些理由还不足以令你信服,读一下 动机 和 Flux 案例,这里面有更加详细的单向数据流优势分析。虽然 Redux 不是严格意义上的 Flux,但它们有共同的设计思想。 Redux
-
有时,您希望发送非常巨量的数据到客户端,远远超过您可以保存在内存中的量。 在您实时地产生这些数据时,如何才能直接把他发送给客户端,而不需要在文件 系统中中转呢? 答案是生成器和 Direct Response。 基本使用 下面是一个简单的视图函数,这一视图函数实时生成大量的 CSV 数据, 这一技巧使用了一个内部函数,这一函数使用生成器来生成数据,并且 稍后激发这个生成器函数时,把返回值传递给一个
-
Streaming API用于通过令牌读取JSON令牌。 它读取和写入JSON内容作为离散事件。 和将数据读取/写入令牌,称为。 这是处理JSON的三种方法中最强大的方法。 它具有最低的开销,并且在读/写操作中速度非常快。 它类似于用于XML的Stax解析器。 在本章中,我们将展示使用GSON streaming API来读取JSON数据。 Streaming API与令牌的概念一起工作,Json
-
问题内容: 我是管道功能概念的新手。我有一些关于 从数据库的角度来看: 管道功能到底是什么? 使用管道功能的好处是什么? 使用管道功能解决了哪些挑战? 使用管道功能有什么优化优势? 谢谢。 问题答案: 引用“问汤姆·甲骨文”: 流水线函数只是“您可以假装为数据库表的代码” 流水线函数使您(让我惊讶) 在您认为可以使用它的任何时候-从函数而不是表中选择*可能是“有用的”。 就优点而言:使用Pipel
-
我正在开发一个物联网应用程序,需要从PubSub主题读取流数据。我想使用Google云数据流SDK读取这些数据。我正在使用Java 1.8 我正在使用谷歌云平台的试用版。当我使用PubSubIO时。Read方法读取流数据时,我在日志文件中发现错误,我的项目没有足够的CPU配额来运行应用程序。 所以我想使用谷歌云数据流SDK读取流数据。 请有人告诉我在哪里可以找到使用Google Cloud Dat
-
我在这个网站上用docker compose启动了Spring云数据流。 https://dataflow.spring.io/docs/installation/local/docker/ 我创建了3个应用程序,源,处理器 我跑了 当我运行docker compose-f时/docker编写。yml-f/docker创作普罗米修斯。yml,所有我的容器都按照docker compose中的指定启
-
数据流测试用于分析程序中的数据流。它是收集有关变量如何在程序中流动数据的过程。它试图获得过程中每个特定点的特定信息。 数据流测试是一组测试策略,用于检查程序的控制流程,以便根据事件的顺序探索变量的顺序。它主要关注分配给变量的值和通过集中在两个点上使用这些值的点的点,可以测试数据流。 数据流测试使用控制流图来检测可能中断数据流的不合逻辑的事物。由于以下原因,在值和变量之间的关联时检测到数据流中的异常
-
主要内容:1 什么是数据流API,2 使用JsonGenerator写入JSON,3 使用JsonParser读取JSON1 什么是数据流API 数据流API(即,Streaming API)读取和写入JSON内容作为离散事件。JsonParser类用于读取数据,而JsonGenerator类用于写入数据。这是这三种方法中功能最强大的一种,开销最低,读/写操作最快。它类似于XML的Stax解析器。 在本文中,将展示如何使用Jackson数据流API读取和写入JSON数据。Streaming AP