
MyRocks
RocksDB是facebook基于LevelDB实现的,目前为facebook内部大量业务提供服务。经过facebook大量工作,将RocksDB为MySQL的一个存储引擎移植到MySQL,称之为MyRocks。
经过两年的发展,MyRocks已经比较成熟(RC阶段),现已进入了facebook MySQL的主分支了。MyRocks是开源的,参见git 。
下面对MyRocks做一个简单介绍。
RocksDB与innodb的比较
-
innodb空间浪费, B tree分裂导致page内有较多空闲,page利用率不高。innodb现有的压缩效率也不高,压缩以block为单位,也会造成浪费。
-
写入放大:innodb 更新以页为单位,最坏的情况更新N行会更新N个页。RocksDB append only方式
另外,innodb开启double write也会增加写入。 -
RocksDB对齐开销小:SST file (默认2MB)需要对齐,但远大于4k, RocksDB_block_size(默认4k) 不需要对齐,因此对齐浪费空间较少
-
RocksDB索引前缀相同值压缩存储
-
RocksDB占总数据量90%的最底层数据,行内不需要存储系统列seqid
(innodb聚簇索引列包含trxid,roll_ptr等信息
来看看facebook的测试数据
-
数据空间对比
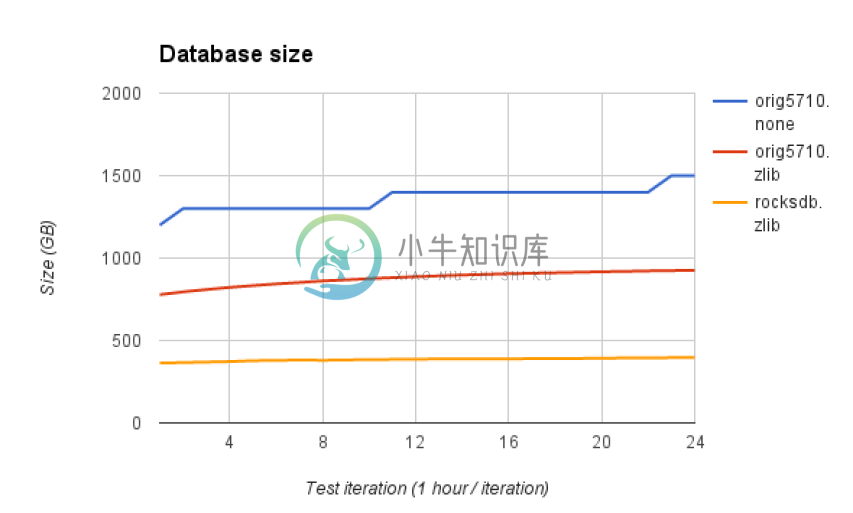
-
QPS
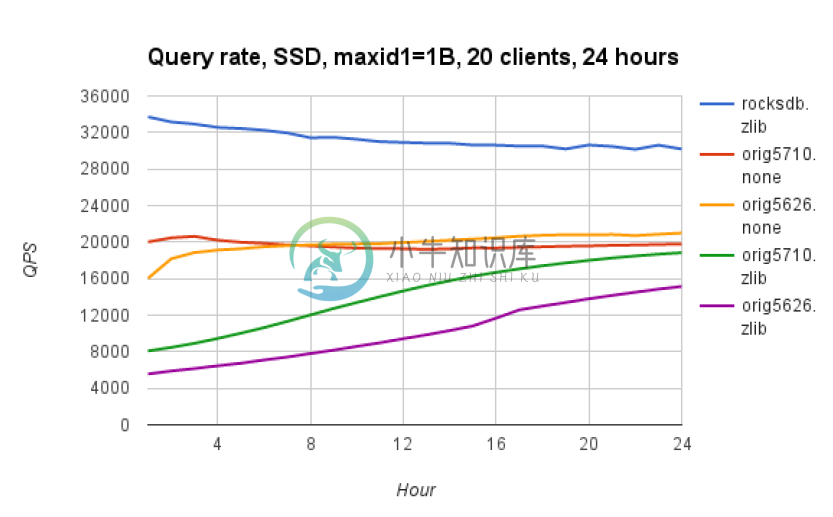
-
写入放大对比
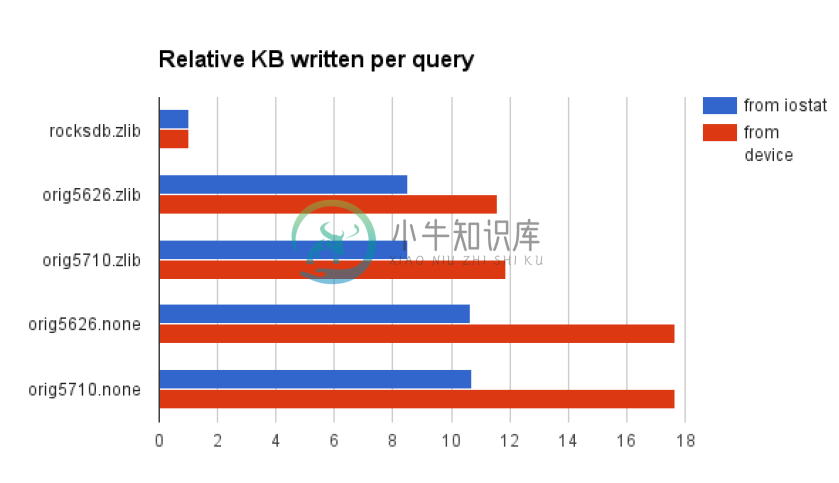
数据字典
数据字段信息保存在System Column Family (System CF) "__system__"中
数据字段信息包括:
-
表信息,表名和index id的映射
-
索引信息,索引元数据信息和column family id。column family和index的对应关系 1:N
-
column family,一些标记,比如reverse属性等
-
binlog信息
-
统计信息,每个SST file都自带统计信息(行数、实际大小等),在flush或compaction时更新统计信息,同时统计信息会汇总到数据字典统计信息表中。
以上信息可以通过information_schema查看,如RocksDB_ddl,RocksDB_index_file_map等
记录格式
RocksDB的行以key value的形式存储,和innodb类似,记录格式主键和二级索引也有区别

事务与锁
MyRocks也是基于行锁,锁信息都保存在内存中。
MyRocks也支持MVCC,MVCC通过快照的方式实现,类似于PostgreSQL。
MyRocks目前只支持两种隔离级别,RC和RR。
RR表现和innodb并不一样,RocksDB 的快照不是在事务开始的时候建立,而是延迟到第一次读的时候建立.
以下client1 MyRocks返回的是2,innodb返回1
<client 1> <client 2> CREATE TABLE t1(pk INT PRIMARY KEY); INSERT INTO t1 VALUES(1); SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ; SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ; BEGIN INSERT INTO t1 VALUES(2); SELECT COUNT(*) FROM t1; // MyRocks返回的是2,innodb返回1
复制
MyRocks也是通过binlog方式复制,由于binlog与RocksDB之间没有xa,异常crash可能丢数据,所以,MyRocks主备环境建议开启semi-sync.
由于gap lock支持不健全(仅primary key上支持), 使用statement方式复制会导致不一致,所有MyRocks建议使用行级复制。
备份恢复
支持MySQLdumup逻辑备份
#内部会执行以下语句 SET TRANSACTION ISOLATION LEVEL REPEATABLE READ; START TRANSACTION WITH CONSISTENT RocksDB SNAPSHOT;
同时有自动的物理备份工具MyRocks_hotbackup,但还不支持备份innodb; 也不支持增量备份。MyRocks_hotbackup支持流式备份
MyRocks_hotbackup--user=root --port=3306 --checkpoint_dir=/data/backup --stream=xbstream| ssh$dst‘xbstream–x /data/backup’ #内部建立硬链接方式备份数据SST files,checkpoint多次更新,只备份新的SST files, 因此WAL日志很少,恢复时apply log时间很短 SET GLOBAL RocksDB_create_checkpoint= /path/to/backup
一些优化
-
bloom filter
bloom filter一般适用于等值查询
bloom filter信息存储在SST files中,大概占用2~3%的空间
如果大量查询返回空集建议开启bloom filter,如果结果每次都在最底层找到,可以设置optimize_filters_for_hits=true关闭bloom filter以节省空间。 -
数据加载
数据加载时可以忽略唯一性约束检查,分段自动提交,停写wal等。
以下是推荐的数据加载时的参数配置
rocksdb_skip_unique_check=1
rocksdb_commit_in_the_middle=1
rocksdb_write_disable_wal=1
rocksdb_max_background_flushes=40
rocksdb_max_background_compactions=40
rocksdb_default_cf_options=(in addition
to existing parameters);
write_buffer_size=128m;level0_file_num_compaction_trigger=4;level0_slowdown_writes_trigger=256;level0_stop_writes_trigger=256;max_write_buffer_number=16;memtable=vector:1024
rocksdb_override_cf_options=(in addition to existing parameters);__system__={memtable=skip_list:16}
-
Reverse column families
MyRocks擅长正向扫描,为了提高逆向扫描(ORDER BY DESC)的性能,MyRocks支持了Reverse column families。 在建表可以指定column family的reverse属性。 -
singleDelete
如果key不会重复put, delete操作可以直接删除put,而不是标记删除。singleDelete可以提供查询效率。
一些限制
MyRocks目前有以下一些限制
-
不支持分区表,Online ddl,外键,全文索引,空间索引,表空间transport
-
gap lock支持不健全(仅primary key上支持), 使用statement方式复制会导致不一致
-
不支持select … in share mode
-
大小写敏感,不支持*_bin collation
-
binlog与RocksDB之间没有xa,异常crash可能丢数据。所以,MyRocks一般开启semi-sync.
-
不支持savepoint
-
order by 不比较慢
-
不支持MRR
-
暂不支持O_DIRECT
-
innodb和RocksDB混合使用还不稳定
-
Percona-MyRocks 简介 MyRocks是与Facebook开源项目RocksDB集成的MySQL存储引擎。通过提高读取,写入和存储数据的效率,它提供了改进的闪存存储性能。针对快速,低延迟的存储进行了优化,非常适合当今的大容量,写密集型应用,例如数据聚合,IoT,交易记录,系统监控,支付处理和计费系统。MyRocks需要更少的SSD存储空间,提供更多的存储耐用性,并确保更好的IO容量。
-
官方推荐的参数文件配置: [mysqld] rocksdb default-storage-engine=rocksdb skip-innodb default-tmp-storage-engine=MyISAM binlog_format=ROW collation-server=latin1_bin transaction-isolation=READ-COMMITTED rocksdb_m
-
Cluster index介绍 最近在RDS MyRocks中,我们引入了一个重要功能,二级聚集索引(secondary clustering index). 我们知道innodb和rocksdb引擎的主键就是clustered index。二级聚集索引和普通二级索引的区别是,普通二级索引只包括索引列和主键列数据,而二级聚集索引列包含表的所有列数据。可以说二级聚集索引是表数据的一个完整的copy.
-
最近一个日常实例在做DDL过程中,直接把数据库给干趴下了,问题还是比较严重的,于是赶紧排查问题,撸了下crash堆栈和alert日志,发现是在去除唯一约束的场景下,MyRocks存在一个严重的bug,于是紧急向官方提了一个bug。其实问题比较隐蔽,因为直接一条DDL语句,数据库是不会挂了,而是在特定情况下,并且对同一个索引操作多次才会发生,因此排查问题也费了一些时间,具体bug排查和复现
-
概述 MyRocks TTL(Time To Live) 特性允许用户指定表数据的自动过期时间,表数据根据指定的时间在compact过程中进行清理。 MyRocks TTL 简单用法如下, 在comment中通过ttl_duration指定过期时间,ttl_col指定过期时间列 CREATE TABLE t1 ( a bigint(20) NOT NULL, b int NOT NULL,
-
MyRocks简介: MyRocks是facebook开发的一款基于RocksDB的开源MySQL存储引擎,基于oracle MySQL5.6版本。 MyRocks库由Facebook 数据库工程团队维护。 RocksDB是一个可嵌入的、持久K-V存储。 RocksDB 是基于log-structured merge-tree(LSM-tree),针对快速存储进行了优化,并将出色的 存储空间和读写
-
概述 MyRocks中RocksDB作为基于快照的事务引擎,其在事务支持上有别于InnoDB,有其自身的特点。在早期的月报[myrocks之事务处理] 中,我们对锁的实现有过简单的分析,本文会以一些例子来介绍MyRocks是如果来加锁解锁的。 锁类型 MyRocks早期只支持排他锁,支持SELEC… IN SHARE MODE后,MyRocks才开始引入共享锁。 /* Type of locki
-
在Facebook官方的发布的比对中是采用的linkbench来比对InnoDB和MyRocks,其中提到在SSD硬盘存储磁盘空间降低至少2倍, 但是写入速度降低了10倍,对于需要大量存储数据的公司来说对存储的要求更持久一些。 Benchmark tests against 3 different instances – MyRocks (compressed), InnoDB (uncompre
-
运行环境:CentOS 7.5+MariaDB 10.3 +MyRocks 存储引擎 背景: 想搭建一个运行默认存储引擎是MyRocks的MySQL实例,来和InnoDB比对下。 1.规划: 由于我的电脑资源有限,在单主机上搭建多实例。前面运行了由3个默认存储引擎为InnoDB的实例。 端口:3304 数据目录:/data/mysql/node4 socket文件: PID文件: 2.参数文
-
之前通过TIDB了解到了LSM Tree,优化了数据库的写入的速度,在mariadb下,也有一个基于LSM的存储引擎Myrocks,他也支持事务,目前也是稳定版本,最近有时间学习了下。目前10.7windows版本里面是自带myrocks的,只是默认没有起来,配置my.ini后,show engines就可以看到了。 为了测试真实的效果,我建了一个带主键和二级唯一索引的myrocks用户表,主键采
-
https://mariadb.com/kb/en/getting-started-with-myrocks/ INSTALL SONAME 'ha_rocksdb'; CREATE TABLE sample ( id INT PRIMARY KEY AUTO_INCREMENT, uid INT, name VARCHAR(25), ts TIMESTAMP,
-
分支变换与组合变换恰好相反,它通常是由一个上游节点以特定的规则分离出不同的下游节点。下面是全部的分支变换形式。 switch-case-default switch-case-default 变换是通过给出的 block 将每个上游的值代入,求出唯一标识符,再分离这些标识符的一种操作。我们举例一个分离剧本的例子: EZRMutableNode<NSString *> *node = [EZRMut
-
开发项目的时候,有了新的想法,但你又不太确定想法是否可行,或者你打算为项目开发一项新功能。都可以去创建一个新的分支,在上面去实践你的想法,如果可行,或者在新分支上完成了你想要的功能,你可以再把在这个分支上对项目做的修改合并到主分支或开发分支上。完成以后,可以保留这些分支,也可以把它们删除掉。 列出分支 git branch 创建分支 git branch 新分支 删除分支 git branch
-
简介 上一章中,我讲解了如何定义函数。本章中,我会讲解如何通过条件编写过程。这个是编写使用程序很重要的一步。 if表达式 if表达式将过程分为两个部分。if的格式如下: (if predicate then_value else_value) 如果predicate部分为真,那么then_value部分被求值,否则else_value部分被求值,并且求得的值会返回给if语句的括号外。true是除
-
远程引用是对远程仓库的引用(指针),包括分支、标签等等。 你可以通过 git ls-remote (remote) 来显式地获得远程引用的完整列表,或者通过 git remote show (remote) 获得远程分支的更多信息。 然而,一个更常见的做法是利用远程跟踪分支。 远程跟踪分支是远程分支状态的引用。 它们是你不能移动的本地引用,当你做任何网络通信操作时,它们会自动移动。 远程跟踪分支像
-
现在已经创建、合并、删除了一些分支,让我们看看一些常用的分支管理工具。 git branch 命令不只是可以创建与删除分支。 如果不加任何参数运行它,会得到当前所有分支的一个列表: $ git branch iss53 * master testing 注意 master 分支前的 * 字符:它代表现在检出的那一个分支(也就是说,当前 HEAD 指针所指向的分支)。 这意味着如果在这时候提
-
几乎所有的版本控制系统都以某种形式支持分支。 使用分支意味着你可以把你的工作从开发主线上分离开来,以免影响开发主线。 在很多版本控制系统中,这是一个略微低效的过程——常常需要完全创建一个源代码目录的副本。对于大项目来说,这样的过程会耗费很多时间。 有人把 Git 的分支模型称为它的“必杀技特性”,也正因为这一特性,使得 Git 从众多版本控制系统中脱颖而出。 为何 Git 的分支模型如此出众呢?
-
我看到了这张非常漂亮的信息图,它大致估计了用于某些操作的CPU周期。在学习的时候,我注意到了一个条目“如果的右分支”,我假设如果满足条件,“如果”将要分支(编辑:正如评论中指出的,“右”实际上意味着“正确预测的分支”)。这让我怀疑if分支与else分支相比是否存在任何(甚至如此微小)速度差异。 例如,比较以下非常简洁的代码: 演示 它在x86 64bit中生成此程序集: 如您所见,右边的分支为“a
-
分支是任何编程语言中最重要的方面。 在编写程序时,您可能会遇到必须做出决定的情况,或者您必须从给定的多个选项中选择一个选项。 下图显示了一个简单的场景,其中程序需要根据给定条件采用两个路径之一。 Euphoria提供以下三种类型的决策(分支或条件)声明 - if 语句 switch 语句 ifdef statement 让我们详细看一下这些陈述 -