
1. 概述
1.1. 数据分布式切分方式
分布式架构中最难解决的是数据分布式问题,大部分数据库中间件都以分库分表作为切分方式,好处是通用,但也存在以下问题:
扩容过程需要以切片为单位在库间移动数据。扩容规模受到切片数量限制,如果业务发展增长规模大大超出初期预估会导致切片数量不够用,陷入数据硬迁移的困境。
同一业务对象的数据分散在不同库中,无法做聚合、连接等复杂处理。
跨库意味着分布式事务,虽然现在有两阶段提交等解决方案,但理论上并不总是那么可靠,尤其是在金融行业苛求数据强一致性时。
以核心业务对象切分方式则以产品线入口业务对象作为切分目标(比如互联网业务系统中的客户对象),开户交易途径数据库中间件,以手机号或其它入口字段作为核心字段做附带权重的客群切分,归属到数据库集群中的某个库中,并保存分配结果,以后该客户的所有交易都会被发往其归属库处理。当需要库存储扩容时,只需简单的增加MySQL归属库到数据库集群中,在数据库中间件系统中增加新归属库配置信息,并调大新库被分配权重,新客户分配归属到新库的概率变大,当新库存储增长到一定程度时调平分配权重,新客户分配归属到所有库的概率均等,直到下一次扩容。
以核心业务对象切分方式的好处是:
无需预估切片,其扩容过程无需移动任何数据。
由于同一业务对象的数据集中在其归属库中,所以可以进行任意聚合、连接等复杂处理。
每个库都是全业务库,同一业务对象的所有模块处理都在一个库中完成,不存在跨库分布式事务,数据强一致性丢还给数据库单库来保证。
但也存在以下硬伤:
产品线设计初期慎重挑选核心业务对象作为切分依据,后期很难变更。
有些业务系统存在多个核心业务对象,不适合使用这种切分方式,如银行线上线下整合核心。
以分库分表切分和以核心业务对象切分是两种主流的数据分布式设计范式,各有优缺点,应在不同场景挑选合适的方式。
1.2. mysqlda
mysqlda是一款基于核心业务对象切分的Proxy模式的分布式MySQL数据库中间件。
mysqlda优势:
以核心业务对象切分方式的所有好处。
支持以核心业务对象定位MySQL归属库(如开户用手机号或邮箱),也支持核心业务对象的关联对象(如开户后的用户ID、用户名、账号)定位MySQL归属库。
归属库分配权重自动调整,扩容后新库与老库的分配权重也自动调整,无需人工介入,使得所有归属库的数据量尽量自动均衡增长。
已包含数据库网关高可用功能,当一个归属库当前MySQL主服务器不可用时自动切换到备服务器,支持多个备服务器。
与MySQL服务器之间的连接池机制,实现了连接复用和闲置清理,提高连接和切换性能。
通过在线重载配置文件,扩容新增MySQL归属库、调整MySQL服务器优先列表等完全无感。
单体系统的数据分布式改造过程尽量无感。
2. 架构与原理
2.1. 体系架构
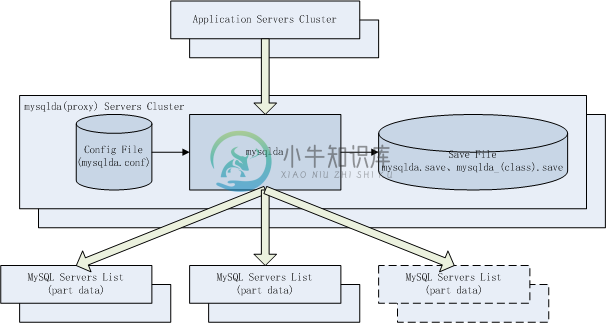
mysqlda数据库中间件完全遵循MySQL通讯协议桥接应用服务器集群和MySQL数据库集群。
mysqlda内部进程结构为"父-单子进程"。
2.2. 工作原理
全量数据以核心业务对象切分到多个归属库中,每个归属库包含全业务表。一个归属库由一个MySQL服务器列表(需部署为向下游同步数据)组成,当当前MySQL服务器不可用时自动切换到下一个。
MySQL数据库集群预创建相同的连接用户名、密码,相同的数据库名和应用表结构,mysqlda预创建相同的连接用户名、密码。
启动mysqlda,从配置文件(etc/mysqlda.conf)中装载连接用户名、密码,从保存文件(etc/mysqlda.save、etc/mysqlda.关联对象类.save)中装载已存在的核心业务对象、关联对象 与 MySQL数据库集群库 归属库关系信息。
应用服务器调用标准MySQL连接函数/方法连接mysqlda,mysqlda会遵循MySQL通讯协议处理MySQL用户登录和密码校验。
登录成功后,所有DSL、DML操作前,应用服务器发送mysqlda扩展SQL选择核心业务对象("select library (核心业务对象)")或关联对象类、关联对象("select library_by_correl_object (关联对象类) (关联对象)")以连接MySQL归属库,mysqlda会查询其已分配的MySQL库核心业务对象或关联对象类、关联对象(如果没有分配过则根据加权一致性哈希算法分配一个归属库并持久化到保存文件中),从该MySQL归属库对应数据库服务器有序列表中选择第一个有效MySQL服务器及其连接池中选取空闲连接(如没有缓存连接则新建一条连接),然后桥接对外和对内连接结对,开始处理后续所有DSL、DML操作。
后续操作中可以也发送mysqlda扩展SQL再选择核心业务对象或关联对象类、关联对象以调整MySQL归属库服务器连接。
MySQL归属库对应一个数据库服务器列表,如由MySQL数据库1A(MASTER)、1B(SLAVE)、1C(SLAVE)、1D(SLAVE)组成,1A同步复制数据给1B、1C和1D,如果1A出现故障不能被mysqlda连接,mysqlda会依次尝试连接1B、1C和1D,实现系统可用性。
应用服务器发送mysqlda扩展SQL绑定关联对象类和关联对象和核心业务对象("set correl_object 关联对象类 关联对象 核心业务对象"),mysqlda会保存该关系并持久化到保存文件中,供以后直接用关联对象类、关联对象定位MySQL归属库。
2.3. 简易案例
部署了三个MySQL归属库,每个库有主备两台MySQL服务器组成。
A用户用手机号(核心业务对象)开户,应用服务器发送手机号13812345678给mysqlda请求定位归属库("select library 13812341234"),mysqlda通过加权一致性哈希算法计算出该手机号(分配客户)归属库N并持久化到保存文件中,从归属库N连接池中取出一个连接,把该连接与应用服务器连接桥接,交换后面的所有SQL和处理结果。
开户业务逻辑中创建了账户331234567890,,应用服务器发送mysqlda扩展SQL给mysqla("set correl_object account_no 331234567890 13812345678"),mysqlda绑定两者关系并持久化到保存文件中。
A用户后续处理请求,可以送手机号("select library 13812341234")或账号("select library_by_correl_object account_no 331234567890")给mysqlda定位、连接用户归属库,该用户的所有业务数据和业务处理都在该归属库中完成。
2.4. 内部数据实体和关系
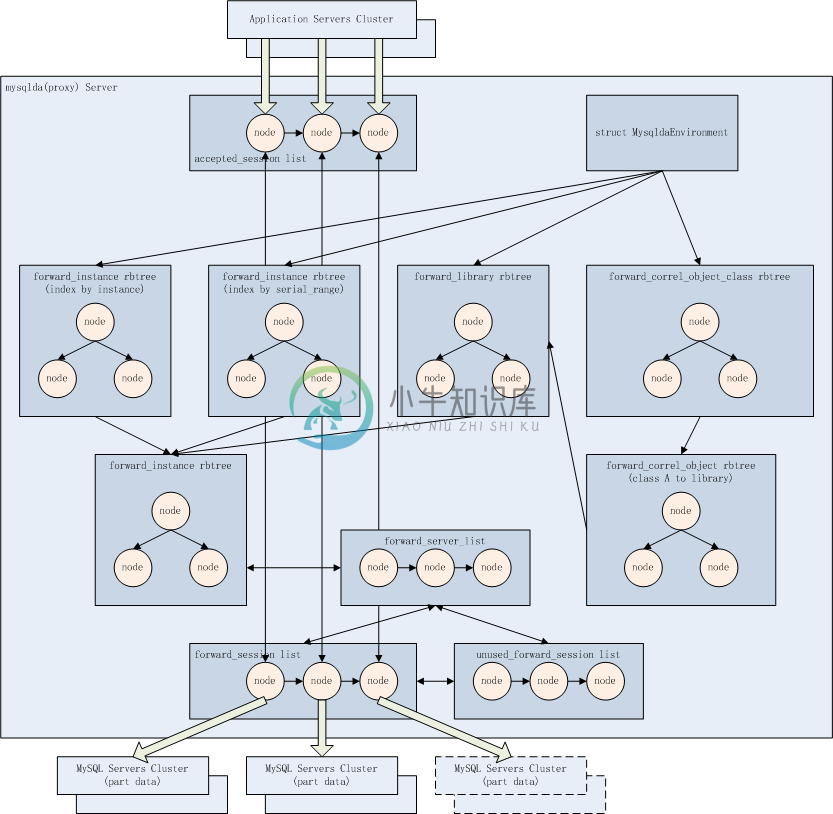
一个MySQL归属库(forward_instance)对应一个MySQL数据库服务器有序列表(forward_servers list)。
一个MySQL数据库服务器有序列表(forward_servers list)下辖一个空闲连接池(unused_forward_session list)和一个工作连接池(forward_session list)。
一个核心业务对象可以绑定一个或多个关联对象类(forward_correl_object_class)、关联对象(forward_correl_object)。
一个核心业务对象或一个关联对象类、关联对象 与 MySQL归属库 建立一个归属关系(forward_library)。
accepted_session是应用服务器与mysqlda之间的通讯会话,forward_session是mysqlda与MySQL数据库服务器之间的通讯会话,一旦一条连接上的MySQL归属库被选定或切换,这两个会话会被桥接起来。
-
分布式支持 数据访问层支持分布式数据库,包括读写分离,要启用分布式数据库,需要开启数据库配置文件中的deploy参数: return [ // 启用分布式数据库 'deploy' => 1, // 数据库类型 'type' => 'mysql', // 服务器地址 'hostname' => '192.168.1.1,19
-
这里我的疑问是,如果我使用多个分布式数据库,cam如何在配置(application.properties)中提到不同的DB源URL?目前我正在使用以下结构来使用一个数据库, 就像上面那样。 所以,如果我使用多个DB用于多个区域,我如何在这里给出有条件的配置?我是微服务世界和分布式数据库设计模式的新手。
-
请问 nodejs 中有 类似mycat 或 sharingjdbc的分布式数据库中间件么
-
每当我读到有关NoSQL分布式数据库的内容时,他们都会提到CAP定理,这意味着在分区系统中,您可以具有完全一致性,完全可用性或两者兼而有之,但不能完全两者兼而有之。 我不太清楚他们在谈论什么类型的一致性: 是数据新鲜度的一致性,其中一些客户端可能会获得比其他客户端更旧的数据吗? 或者是一致性,即事务可能仅部分完成,这可能会使数据处于不一致的状态? 第二种解释对我来说听起来很危险,不能真正接受。第一
-
本文向大家介绍NoSQL数据库的分布式算法详解,包括了NoSQL数据库的分布式算法详解的使用技巧和注意事项,需要的朋友参考一下 今天,我们将研究一些分布式策略,比如故障检测中的复制,这些策略用黑体字标出,被分为三段: 数据一致性。NoSQL需要在分布式系统的一致性,容错性和性能,低延迟及高可用之间作出权衡,一般来说,数据一致性是一个必选项,所以这一节主要是关于 数据复制 和 数据恢复 。 数据放置
-
一个成功的技术,现实的优先级必须高于公关,你可以糊弄别人,但糊弄不了自然规律。 ——罗杰斯委员会报告(1986) 在本书的第一部分中,我们讨论了数据系统的各个方面,但仅限于数据存储在单台机器上的情况。现在我们到了第二部分,进入更高的层次,并提出一个问题:如果多台机器参与数据的存储和检索,会发生什么? 你可能会出于各种各样的原因,希望将数据库分布到多台机器上: 可扩展性 如果你的数据量、读取负载、写