
KSQL
用于 Apache Kafka 的流数据 SQL 引擎
注意:项目还处于开发者预览版,请暂时勿用于生产集群中。
KSQL 是 Apache Kafka 的开源流 SQL 引擎。 它为 Kafka 的流处理提供了一个简单而完整的 SQL 界面; 不需要再用编程语言(如 Java 或 Python )编写代码。 KSQL 是分布式、可扩展、可靠的和实时的,支持多种流式操作,包括聚合(aggregate)、连接(join)、时间窗口(window)、会话(session)等等。基于 Apache 2.0 协议开源。

KSQL 的两个核心概念是流(Stream)和表(Table),它将流和表集成在一起,允许将代表当前状态的表与代表当前发生事件的流连接在一起。
项目架构:
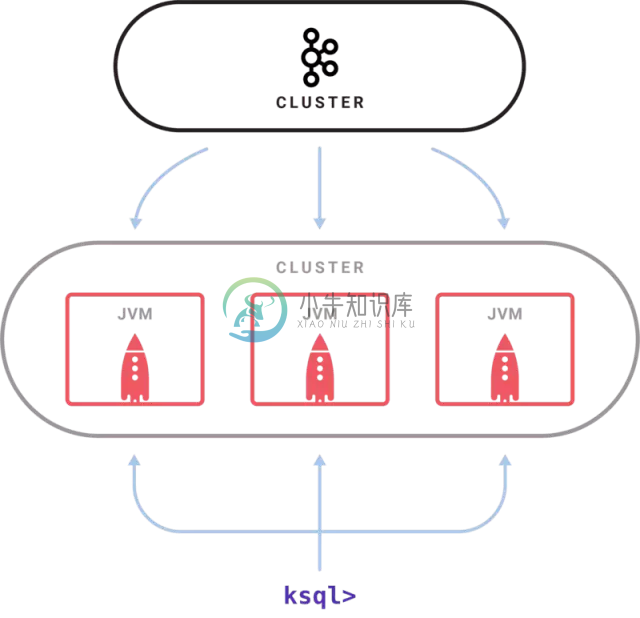
-
目录 4.1. Ksql基础 4.1.1. 输入和执行命令 4.1.2. 列出表的定义 4.1.3. 列出 PL/SQL 定义 4.1.4. 列出模式 4.1.5. 运行 SQL 命令 4.1.6. 运行 PL/SQL 4.1.7. 运行 Ksql 命令 4.1.8. 变量 4.1.9. 停止正在运行的任务 4.1.10. 运行操作系统命令 4.1.11. 自动保存对数据库的更改 4.1.12.
-
目录 2.1. Ksql概述 2.1.1. Ksql命令行架构 2.2. Ksql先决条件 2.3. 启动Ksql命令行 2.4. 连接目标数据库 2.5. 执行一个查询 2.6. 退出Ksql 2.1. Ksql概述 Ksql是KingbaseES基于终端的前端。提供交互式查询,通过文件输入或者命令行输入,得到查询结果。此外,Ksql还提供一些元命令和多种类似shell 的特性来为编写脚本和自动
-
主要内容: 1.背景 kafka早期作为一个日志消息系统,很受运维欢迎的,配合ELK玩起来很happy,在kafka慢慢的转向流式平台的过程中,开发也慢慢介入了,一些业务系统也开始和kafka对接起来了,也还是很受大家欢迎的,由于业务需要,一部分小白也就免不了接触kafka了,这些小白总是会安奈不住好奇心,要精确的查看kafka中的某一条数据,作为服务提供方,我也很方啊,该怎么怼?业务方不敢得罪啊
-
我正在导入一个DB,其中包含一些表示多对多和一对多关系的链接表。 1-到目前为止,根据我对Kafka流的理解,我似乎需要为每个链接表提供一个流,以便执行聚合。KTable将不可用,因为记录是按键更新的。但是,聚合的结果可能是Ktable中的一个。 2-然后是外键上的连接问题。似乎唯一的方法是通过GlobalKtable。link-table-topic->link-table-stream->li
-
我有一个,它是由一个kafka主题创建的,并且指定了属性。 当我试图创建一个时,会话窗口化了一个查询,如下所示: 我总是得到错误: KSQL不支持对窗口表的持久查询 如何在KSQL中创建开始会话窗口的事件的?
-
长话短说:java.io包中有多少种基于数据流的流?它们是字节流和字符流还是二进制流和字符流? 完整问题: https://youtu.be/v1_ATyL4CNQ?t=20m5s昨天看了本教程后跳到20:05,我的印象是基于数据流有两种类型的流:BinaryStreams和CharacterStreams。今天,在了解了更多关于这个主题的知识之后,我的新发现似乎与旧发现相矛盾。 互联网上的大多数
-
我已经通过。但是,我注意到Reshuffle()没有出现在发行版中。这是否意味着我将不能在任何数据流管道中使用?有什么办法可以绕过这个吗?或者pip包可能只是不是最新的,如果Reshuffle()在github的master中,那么它将在Dataflow上可用? 根据对这个问题的回答,我试图从BigQuery中读取数据,然后在将数据写入GCP存储桶中的CSV中之前对数据进行随机化。我注意到,我用来
-
假设我有两个Kafka流(Kafka流scala库,版本2.2.0): 以及他们的加入: KSQL中WHERE子句的等价物是什么?(参见最新订单流)了解流API?使用stream3是个好主意。滤器这种方法的效率是否与KSQL创建的流相同?
-
我已经在kafka上工作了相当长的六个月,我对用户延迟和存储到主题分区中的数据有一些疑问。 问题1:最初,当我开始阅读Kafka并了解如何使用Kafka的功能时,我被教导说,一个只有一部分和一个复制因子的主题会创造奇迹。经过相当长的六个月的工作,将我的项目迁移到live之后,使用我的主题消息的消费者开始给我一个延迟。我阅读了许多关于消费者延迟的堆栈溢出答案,得出结论,如果我增加某个主题的分区和复制