
HydraBase
下一代的 HBase 系统Facebook 在官方博客上宣布推出HBase数据库的升级版——HydraBase, Facebook是HBase的重度用户,Facebook的HBase数据库系统存储着Facebook的很多关键业务数据,包括内部监控系统、搜索索 引、流数据分析以及数据抓取等。HydraBase相比HBase稳定性和可用性更高,可以减少服务器宕机时间。
在HBase系统中,数据分片存储于很多区域,如果某个区域服务器宕机,其域内数据都需要迁移到另外一个域服务器。Facebook指出,虽然HBase能够自动恢复,但是恢复时间过长。
目前该项目已经捐赠给 Apache 基金会。
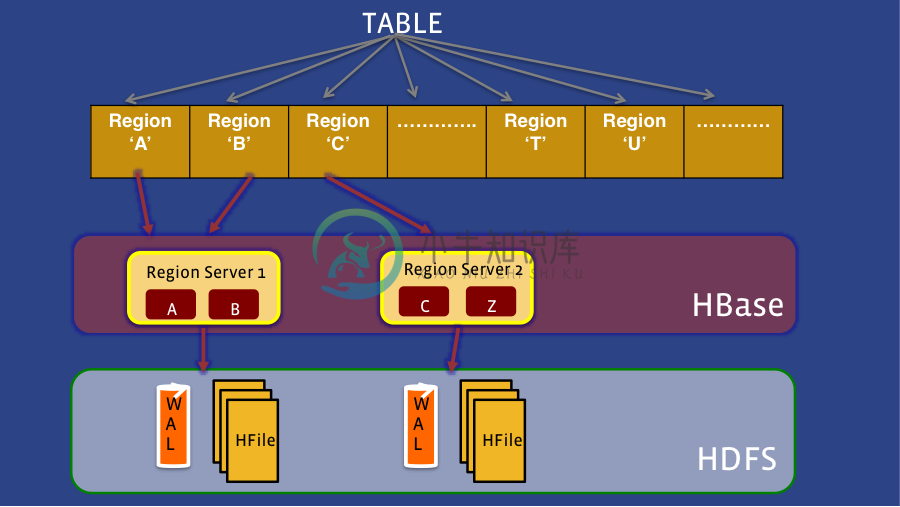
HydraBase的典型部署模型
HydraBase能够让一个数据域分布在多个域服务器中,域服务器之间能相互备份,因此能够大大减少数据恢复所用的时间。Facebook声称HydraBase能将Facebook全年的宕机时间缩减到不到5分钟。
Facebook目前正在测试HydraBase,并计划在生产集群中逐步开始部署。
发布示例: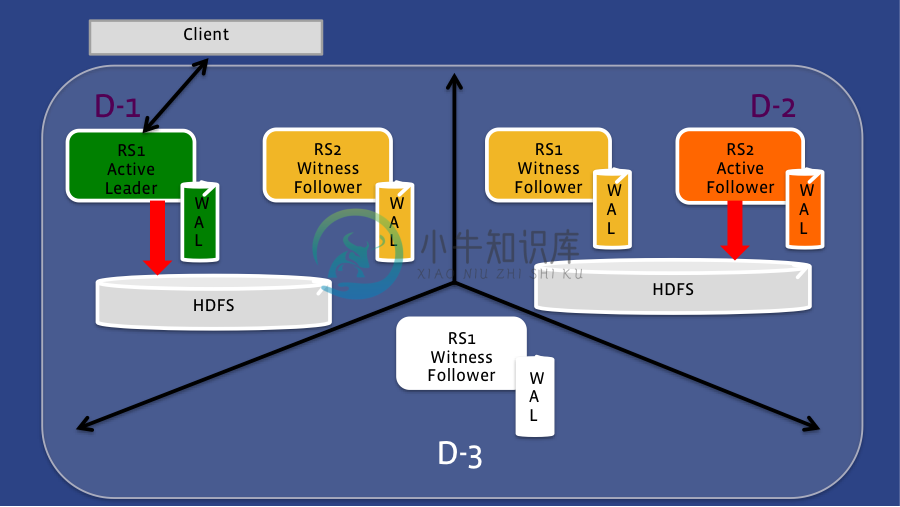
单节点故障: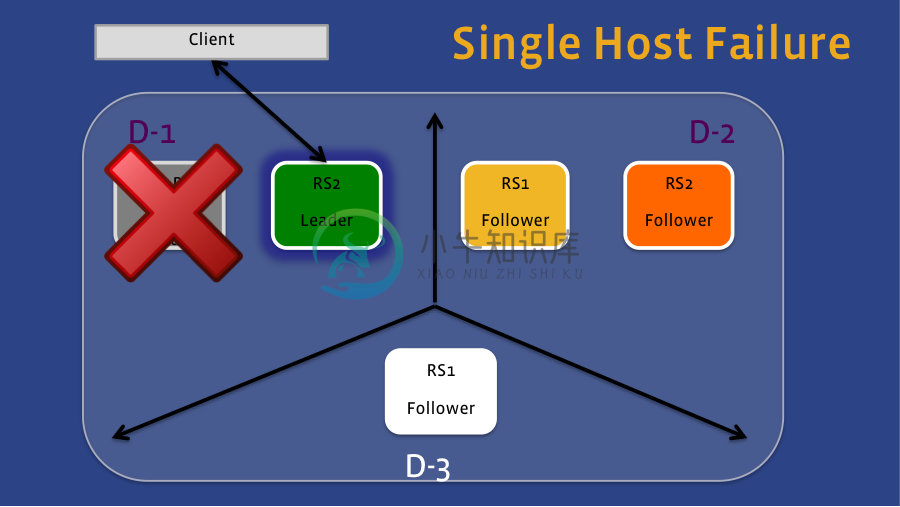
数据中心故障: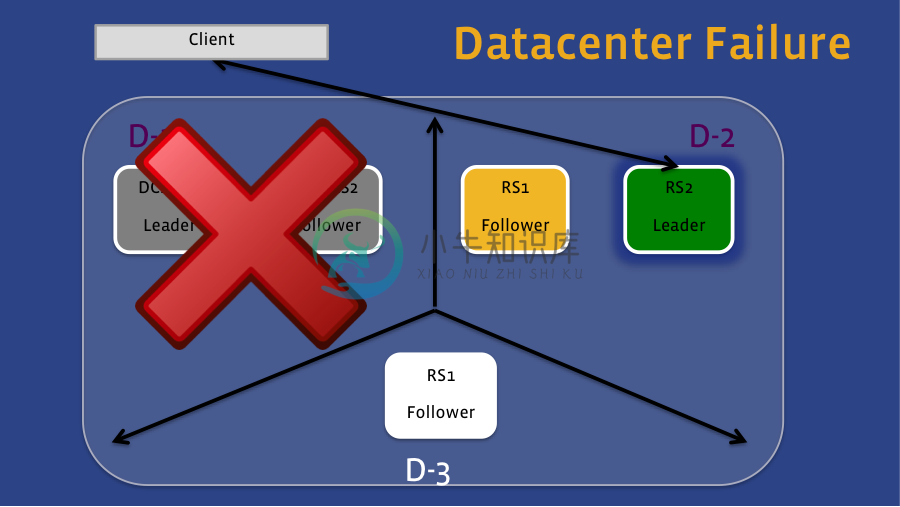
Facebook声称HydraBase能将Facebook全年的宕机时间缩减到不到5分钟。
介绍内容来自 ctocio
-
主要内容:1.二者区别,2.二者联系1.二者区别 hive: Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能。 Hive本身不存储和计算数据,它完全依赖于HDFS和MapReduce,Hive中的表纯逻辑。hive需要用到hdfs存储文件,需要用到MapReduce计算框架。 hive可以认为是map-reduce的一个包装。hive的意义就是把好写的hi
-
问题内容: 我正在尝试使用HBase作为Spark的数据源。因此,第一步证明是从HBase表创建RDD。由于Spark使用hadoop输入格式,因此我可以通过创建rdd http://www.vidyasource.com/blog/Programming/Scala/Java/Data/Hadoop/Analytics/2014/01/25找到使用所有行的方法/ lighting-a-spark
-
本文结构 首先,我们来分别部署一套hadoop、hbase、hive、spark,在讲解部署方法过程中会特殊说明一些重要配置,以及一些架构图以帮我们理解,目的是为后面讲解系统架构和关系打基础。 之后,我们会通过运行一些程序来分析一下这些系统的功能 最后,我们会总结这些系统之间的关系 分布式hadoop部署 首先,在http://hadoop.apache.org/releases.html找到最新
-
一、基本概念 一个典型的 Hbase Table 表如下: 1.1 Row Key (行键) Row Key 是用来检索记录的主键。想要访问 HBase Table 中的数据,只有以下三种方式: 通过指定的 Row Key 进行访问; 通过 Row Key 的 range 进行访问,即访问指定范围内的行; 进行全表扫描。 Row Key 可以是任意字符串,存储时数据按照 Row Key 的字典序进
-
本文向大家介绍详解spring封装hbase的代码实现,包括了详解spring封装hbase的代码实现的使用技巧和注意事项,需要的朋友参考一下 前面我们讲了spring封装MongoDB的代码实现,这里我们讲一下spring封装Hbase的代码实现。 hbase的简介: 此处大概说一下,不是我们要讨论的重点。 HBase是一个分布式的、面向列的开源数据库,HBase在Hadoop之上提供了类似于B
-
类 As of React JS 0.13 you will be able to define components as classes. 在 React JS 0.13 中,你可以把组件定义为类。 class MyComponent extends React.Component { constructor() { this.state = {message: 'Hello wo