
.NET平台下,一个高效的从Html中提取正文的工具。
正文提取采用了基于文本密度的提取算法,支持从压缩的Html文档中提取正文,每个页面平均提取时间为30ms,正确率到95%以上。
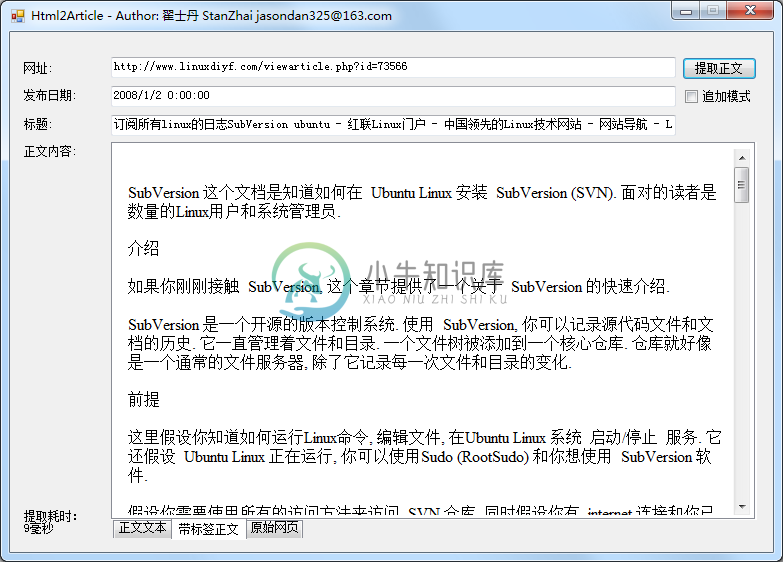
Html2Article有如下特点:
- 标签无关,提取正文不依赖标签。
- 支持从压缩的html文档中提取正文内容。
- 支持带标签输出原始正文。
- 核心算法简洁高效,平均提取时间在30ms左右。
使用示例:
/// <summary>
/// 文章正文数据模型
/// </summary>
public class Article
{
public string Title { get; set; }
/// <summary>
/// 正文文本
/// </summary>
public string Content { get; set; }
/// <summary>
/// 带标签正文
/// </summary>
public string ContentWithTags { get; set; }
public DateTime PublishDate { get; set; }
}
// html为你要提取的html文本 string html = "<html>....<html>"; Article article = Html2Article.GetArticle(html);
-
article元素 article元素代表文档、页面、应用程序、或网站中一个独立的、完整的、可以独自被外部引用的内容,它可以是一篇论坛帖子、一篇文章、一篇新闻报道、一篇博客文章等任何独立的内容块,它通常有自己的标题、页脚等。因此,article元素里面可包含独立的 header、footer 等结构化元素。如: <article> <header> <h1>The Very First Rule
-
html5中的div和section,article,aside的用法 最近在学习html5,关于section和div还有article的理解非常模糊,于是查了些资料终于对section和div还有article的区别有了些自己的理解。怕以后忘记,记录下来。 第一点:section 的含义是区,块。里面必须包含一个标题,如果一个网页分区比较明确可以使用section 举例,一张报纸,里面有国内新
-
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>article元素的使用方法</title> </head> <body> <article> <header> <h1>我是article</h1>
-
要获得实际证据,请使用默认的Mozilla Firefox样式查看html.css(171 - 237): h1 { font-size: 2em; } h2 { font-size: 1.5em; } h3 { font-size: 1.17em; } h4 { font-size: 1.00em; } h5 { font-size: 0.83em; } h6 { font-size: 0.67
-
在Html5中,加入了很多用于“布局”的标签,他们有<header>、<nav>、<section>、<article>、<aside>、<footer>、<hgroup>等等。 其中<section>和<article>最为相似,而且和div标签貌似也有很大相似之处。 但看似相似,并不是真的相似,这些标签是为了布局而生的,自然有它们更精确的语义定位,或者说他们更将强调Html的语义。 1.art
-
HTML5 添加了诸如main、header、footer、nav、article、section等大量新标签,这些新标签为开发人员提供更多的选择和辅助特性。 默认情况下,浏览器呈现这些新标签的方式与div相似。然而,合理地使用它们,可以使你的标签更加的语义化。辅助技术(如:屏幕阅读器)可以通过这些标签为用户提供更加准确的、易于理解的页面信息。 标签main main标签用于呈现网页的主体内容,且
-
.paths(PathSelectors.any()) 这个会导致404 不知道为什么 .paths(PathSelectors.regex("/.*")) 接口前缀 @Configuration @EnableSwagger2 public class SwaggerConfiguration { @Bean public Docket createRestApi()
-
近来,发现自己编码有个问题,对article,div,section有些乱用,索性就好好了解下他们的区别,写个文章,好好的科普一下…… div: hello,大家好。我叫div,对应英文单词中的division,我是块级元素,就是在我里面的内容会自动开始新行,可以定义文档中的分区或节,把文档分割成独立,不同的部分,我参加的国际会议是这么介绍我的,“The div element has no s
-
本文讲解 HTML 语义化相关内容, 语义化这一块作为前端开发者几乎是必须要了解的一块内容; 主要分享的内容有: 1. 什么是 HTML 语义化; 2. HTML 语义化网页的好处; 3. 如何进行 HTML 语义化; 4. 语义化标签有哪些 。 废话不多说, 直接上代码以及图例 (为了让大家方便阅读, 都有自己验证过程的一些图片作为分享) 。 一. 什么是 HTML 语义化 1. “语义化”:
-
http://jingyan.baidu.com/article/db55b609aac41e4ba30a2f86.html
-
前面写过Echarts图表生成PDF文件http://blog.csdn.net/zt_fucker/article/details/71601362 只是一个简单的demo示例,包含图片和文字,然后最近需求则是大范围的文字和ajax动态获取的嵌套数据。 版本:html2canvas 0.4.1. 原页面代码非常复杂,无法完全还原代码。页面代码中涉及到了iframe、easyUI,tab标签 原因
-
有的时候我们想在vue中直接显示一个html的网页,如果用富文本方式,那么内容就会太多, 我们希望只需填入url链接 那么怎么处理呢? 直接上代码 步骤一: 新建一个vue文件,命名为"HtmlPanel.vue",内容如下,直接ctrl+cv即可! (为简洁,代码经过缩进,在使用时格式化以下即可,不影响使用) <template> <div> <p v-html="html"></p></d
-
https://jingyan.baidu.com/article/0a52e3f4f3bcb7bf62ed72dc.html
-
我有一个Excel工作表,其中一栏填充了专利号。我需要提取每个相应专利的标题,并将其放在专利号旁边的单元格中。因此,代码应执行以下操作: 访问espacenet.com并打开需要名称的专利号。 获取标题。 将其放在所需单元格的Excel工作表中。 这是一个完美适用于第一个专利号的代码,但在这之后会立即出现错误。错误显示:“运行时错误'-2147417848(80010108)': 自动化错误调用的
-
问题内容: 我正在用Java开发一个应用程序,该应用程序可以从不同的网页获取文本信息并将其汇总为一页。例如,假设我在不同的网页(例如印度教,印度时报,政治家等)上都有新闻。该应用程序应该从这些页面的每个页面中提取要点,并将它们整合为一条新闻。该应用程序基于Web内容挖掘的概念。作为该领域的初学者,我不知道从哪里开始我浏览了一些研究论文,这些论文将消除噪声作为构建此应用程序的第一步。 因此,如果给我
-
问题内容: 我正在寻找一种使用jdk或其他库从网页(最初为html)提取文本的方法。请帮忙 谢谢 问题答案: 尽可能使用HTML解析器;Java有很多可用的。 或者您可以像许多人一样使用正则表达式。但是,通常不建议这样做,除非您进行的处理非常简单。 相关问题 Java HTML解析 哪种HTML解析器最好? 任何好的Java HTML解析器? 文字提取: 从HTML Java提取文本 标签剥离:
-
问题内容: 使用Java,如何从给定的网页中提取所有链接? 问题答案: 将Java文件下载为纯文本/ html格式,并通过Jsoup或 html clean传递,两者相似,甚至可以用于解析格式错误的html 4.0语法,然后可以使用流行的HTML DOM解析方法,例如getElementsByName(“ a”)或在jsoup中它甚至很酷,您只需使用 并找到所有链接,然后使用 取自http://j
-
我对前端相当陌生,我一直在努力学习webpack。我遇到了一些问题,当使用提取文本Webpack插件,我似乎无法解决。我将感谢任何关于这个话题的帮助。此外,欢迎任何建议/提示! 警告/~/chokidar/lib/fsevents处理程序。未找到js模块:错误:无法解析C:\Git\JNJ中的模块“fsevents”。Web\src\JNJ。网状物UI\client\node\u modules\
-
在我的硕士论文中,我正在探索通过web自动化从网站中提取数据的可能性。步骤如下: 登录网站(https://www.metal.com/Copper/201102250376) 输入用户名和密码 单击登录 将日期更改为2020年1月1日 刮取生成的表格数据,然后将其保存到csv文件中 用我电脑上的特定名称保存到特定文件夹 运行相同的序列,在同一浏览器窗口的新选项卡中下载其他材料的其他历史价格数据
-
我试图从web页面中提取所有输入字段及其标题和元素详细信息,并将它们放在HashMap中,以便稍后在JUnit测试中使用,如 这就是提取类:
-
了解如何将 PSD 作品快速转换为基于 HTML 的、适用于移动设备和桌面的 Web 设计。将 CSS、图像、度量值、字体、颜色、渐变等内容从 Photoshop 直接提取到 Dreamweaver 中。 注意: Typekit 现已更名为 Adobe Fonts,包含在 Creative Cloud 和其他订阅中。了解详情。 Extract 与 Dreamweaver 集成,让 Web 设计人