
Apache HTrace是Cloudera开源出来的一个分布式系统跟踪框架,支持HDFS和HBase等系统。该项目目前还在孵化阶段。
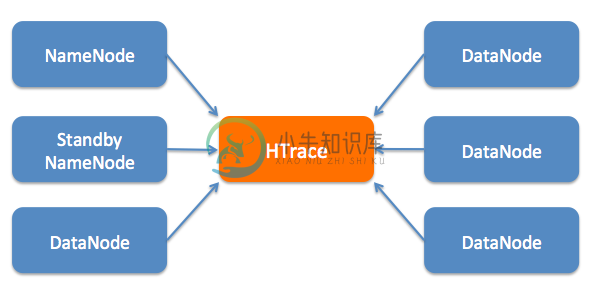
Apache HTrace是一个 Apache Incubator 项目, 可以与独立的应用程序和库使用。HTrace是专为大的分布式系统使用的,如Apache Hadoop分布式文件系统和Apache HBase存储引擎。
通过添加HTrace 支持到你的项目上,你将允许终端用户跟踪他们的请求。此外,任何其他项目使用HTrace都可以使它按照你的项目的请求。 这就是为什么我们说HTrace是“终端到终端”的原因。
HTrace核心库
为了使用HTrace,应用程序必须链接到适当的核心库。HTrace的核心库都经过精心设计,以尽量减少依赖关系的数量。HTrace目前拥有Java,C和C ++的支持。
HTrace保证核心库的API不会以不兼容的方式在次要版本中改变。所以,如果您的应用程序使用HTrace4.1,它应该继续使用HTrace4.2工作,并没有更改代码。 (但是HTrace5将会改变一些东西,因为它是一个主要版本。)
Java
HTrace的Java库被命名为htrace-core4.jar,这个jar只在CLASSPATH出现,如果您正在使用Maven,添加以下到您的dependencyManagement部分:
<dependencyManagement> <dependencies> <dependency> <groupId>org.apache.htrace</groupId> <artifactId>htrace-core4</artifactId> <version>4.1.0-incubating</version> </dependency> ... </dependencies> ...</dependencyManagement>
C
HTrace的C库被命名为libhtrace.so。libhtrace.so接口的描述在htrace.h
C ++
该接口在htrace.hpp一样使用C API描述,除了你使用htrace.hpp代替htrace.h的。
-
问题背景 Apache Spark2 整合 Hbase2 的时候报错 . 问题内容 出现两次错误 第一个: Exception in thread “main” java.lang.NoClassDefFoundError: org/apache/hadoop/hbase/mapreduce/TableInputFormatBase --------------------------------
-
在CDH中,开发的spark连接Hbase的时候,往往会出现找不到org.apache.htrace包。 具体错误如下: ? ? ? ERROR TableInputFormat: java.io.IOException:? ? ? ? java.lang.reflect.InvocationTargetException ? ? ?Caused by: java.lang.NoClassDefF
-
启动看日志报错 java.lang.NoClassDefFoundError: org/apache/htrace/SamplerBuilder at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:644) at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.jav
-
转载请注明出处:http://blog.csdn.net/dongdong9223/article/details/86508330 本文出自【我是干勾鱼的博客】 Ingredients: Language Java:Java SE Development Kit 8u162(Oracle Java Archive),Linux下安装JDK修改环境变量 Hadoop:hadoop-2.9.1.ta
-
环境是这样的 Hadoop-2.8.5 Hbase-2.2.4 之前查了官网,这两个版本是目前可以互相匹配的最高的版本,but启动hbase报下面这个错误 具体日志在log/下hbase-root-master-server1.log中查看 2020-05-23 13:54:19,652 ERROR [main] regionserver.HRegionServer: Failed constru
-
需求背景:使用,但是启动的时候报错 Caused by: java.lang.NoClassDefFoundError: org/apache/htrace/Trace 问题分析:client解析连接的是3.0.4版本的htrace,而真正需要的是3.1.0-incubating这个版本的导致找不到,我们所需要做的就是把低版本的excule掉,单独再引入一次htrace,配置如下,放在pom配置的
-
經過網上苦尋,最終翻查了在\hadoop-2.7.2\share\hadoop\common\lib (我用的版本是2.7.2) 找到了htrace-core-3.1.0-incubating. 這個sampleBuilder 只在3.1.0裏面有,在現在最新的版本4.1.0已經消失了。所以只需要mvn install 這個jar 就好了。
-
有段时间没有用Hbase,今天就尝试安装了下Hbase;环境是这样的 Hadoop-2.8.3 Hbase-2.1.0 之前查了官网,这两个版本是目前可以互相匹配的最高的版本,but启动hbase报下面这个错误 java.lang.NoClassDefFoundError: org/apache/htrace/SamplerBuilder at org.apache.hadoop.hdfs
-
版本:Flink1.11.1 版本:Flink1.11.1 CDH:6.3.2 已知该Hbase对应的Htrace版本: htrace-core-3.2.0-incubating.jar htrace-core4-4.1.0-incubating.jar htrace-core4-4.2.0-incubating.jar 解决方法: 1.拷贝JAR 所有节点执行: cp /opt/cloud
-
HBase报错问题 HBase运行好好的,突然之间重启之后再也起不来了,一直报错。 Caused by: java.lang.ClassNotFoundException: org.apache.htrace.SamplerBuilder 类似的就是这个htrace包里面的内容。 去安装的lib里面查发现真的没有和它有关jar包,再看lib里面的目录client-facing-thirdpar
-
遇到类似java.lang.NoClassDefFoundError: org/apache/htrace/SamplerBuilder解决方案 参考文章: (1)遇到类似java.lang.NoClassDefFoundError: org/apache/htrace/SamplerBuilder解决方案 (2)https://www.cnblogs.com/gambler/p/9034402.
-
项目场景: [NOT FOUND ] org.apache.htrace#htrace-core4;4.1.0-incubating!htrace-core4.jar 问题描述: 配置spark时,报这个错: [NOT FOUND ] org.apache.htrace#htrace-core4;4.1.0-incubating!htrace-core4.jar。 原因分析: 缺少jar包。 解决
-
原因是htrace包找不到 应该将/opt/module/hbase-2.1.9/lib/client-facing-thirdparty目录下的htrace-core-3.1.0-incubating.jar拷贝到/opt/module/hbase-2.1.9/lib/ cp /opt/module/hbase-2.1.9/lib/client-facing-thirdparty/htrace-
-
问题1:java.lang.NoClassDefFoundError: org/apache/htrace/SamplerBuilder 找到这个jar htrace-core-3.1.0-incubating.jar 放到hbase 的lib目录下 错误2:java.lang.NoClassDefFoundError: Could not initialize class org.apache.
-
当我将单体应用拆成多个微服务之后,如何监控服务之间的依赖关系和调用链,以判断应用在哪个服务环节出了问题,哪些地方可以优化?这就需要用到分布式追踪(Distributed Tracing)。 CNCF 提出了分布式追踪的标准 OpenTracing,它提供用厂商中立的 API,并提供 Go、Java、JavaScript、Python、Ruby、PHP、Objective-C、C++ 和 C# 这九
-
本章介绍如何使用Zipkin或Jaeger收集启用了Istio的应用程序的调用链信息。 完成本章后,你可以理解有关应用程序的所有假设以及如何使其参与跟踪,无论您使用何种语言/框架/平台构建应用程序。 BookInfo示例用来作为此任务的示例应用程序。 环境准备 参照安装指南的说明安装Istio。 如果您在安装过程中未启动Zipkin或Jaeger插件,则可以运行以下命令启动: 启动Zipkin:
-
随着服务的数量和复杂性的增加,跨数据中心的统一的可观察性变得越来越重要。Linkerd 的跟踪和度量工具旨在汇总,为所有服务的健康提供广泛而细致的洞察。Linkerd 作为服务网格的角色使其成为可观察性信息的理想数据源,特别是在多语言环境中。 当请求通过多个服务时,使用传统的调试技术来识别性能瓶颈变得越来越困难。分布式跟踪提供通过多个服务的请求的整体视图,允许立即识别延迟问题。 使用 linker
-
在 CakePHP 的开发过程中,以问题跟踪系统的形式从社区获得反馈和帮助是极为重要的一部 分。所有 CakePHP 的问题跟踪都托管在 GitHub 上。 报告臭虫 写得好的问题报告都非常有用。下面的步骤可以帮助创建尽可能好的问题报告: 请 搜索 类似的已有问题,并保证别人没有报告你的问题,或者在源代码仓库中还没有得到修复。 请 包括 如何重现问题 的详细说明。这可以是测试用例或代码片段,来展示
-
当想知道一个进程在做什么事情的时候,可以通过strace命令跟踪一个进程的所有系统调用。 1、运行 php start.php status 能看到workerman相关进程的信息 如下: Hello admin ---------------------------------------GLOBAL STATUS-----------------------------------------
-
无论项目使用哪个bug跟踪系统,某些开发者总会有些抱怨。在这一点上bug跟踪系统比其他标准开发工具更具代表性。我想这是因为bug跟踪系统是这样可视化和可交互,可以轻松的想象出一个人可以做的改进(如果某人有时间),并说出这些改进的描述。把这些不可避免的抱怨当作可信也可疑的吧—下面说的跟踪系统都已经足够好了。 在这个列表中,”问题(issue)“用于代表跟踪系统跟踪的条目。但是请牢记每个系统都会有自己
-
对于积极使用bug跟踪系统的项目,要小心它变成讨论论坛,虽然邮件列表可能更好。通常情况下,它总是很无辜的开始的:某人评论了某个问题,例如提出了一个解决方案或部分补丁。另一个人注意到这个,认为这个方案有些问题,所以附加了另一个评论指出这个问题。第一个人再次回应,对问题作出补充,就这样一直继续下去。 这样做的问题是,首先,bug跟踪系统用于讨论时非常的笨拙,其次,其他人可能不会投入关注—毕竟,他们希望
-
主要内容:一、从一个新闻门户网站案例引入,二、推算一下你需要分析多少条数据?,三、黄金搭档:分布式存储+分布式计算这篇文章聊一个话题:什么是分布式计算系统? 一、从一个新闻门户网站案例引入 现在很多同学经常会看到一些名词,比如分布式服务框架,分布式系统,分布式存储系统,分布式消息系统。 但是有些经验尚浅的同学,可能都很容易被这些名词给搞晕。所以这篇文章就对“分布式计算系统”这个概念做一个科普类的分析。 如果你要理解啥是分布式计算,就必须先得理解啥是分布式存储,现在我们从一个小例子来引入。 比如说