

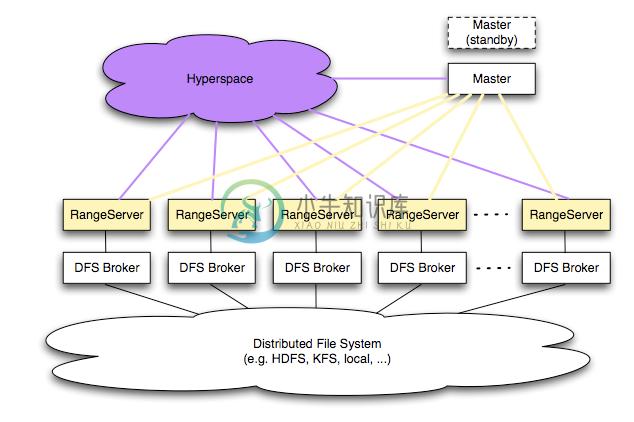
Hypertable 是一个开源、高性能、可伸缩的数据库,它采用与 Google 的 Bigtable 相似的模型。在过去数年中,Google 为在 PC 集群上运行的可伸缩计算基础设施设计建造了三个关键部分。第一个关键的基础设施是 Google File System(GFS),这是一个高可用的文件系统,提供了一个全局的命名空间。它通过跨机器(和跨机架)的文件数据复制来达到高可用性,并因此免受传统 文件存储系统无法避免的许多失败的影响,比如电源、内存和网络端口等失败。第二个基础设施是名为 Map-Reduce 的计算框架,它与 GFS 紧密协作,帮助处理收集到的海量数据。第三个基础设施是 Bigtable,它是传统数据库的替代。Bigtable 让你可以通过一些主键来组织海量数据,并实现高效的 查询。Hypertable 是 Bigtable 的一个开源实现,并且根据我们的想法进行了一些改进。
-
1.failed expectation: insert_result.second 版本:0.9.7.5之前 问题描述: 在自动failover进行的过程中,手动将之前出问题的机器带回集群,Master日志中出现了如下类似错误: (/root/src/hypertable/src/cc/Hypertable/Master/RangeServerConnectionManager.cc:50) C
-
hypertable是什么? hypertable是一个高性能,分布式,开源,面向列的数据库(如果完全支持SQL那将是多么变态地强大..)。它被设计为在廉价普通的计算机硬件上存储,处理大量数据的系统,hypertable是以google的bigtable为原型的。hypertable系统简介 hypertable的原始发行版包含c++ API和HQL(hypertable 查询语句,跟SQL很想)
-
http://hypertable.org/ 4.1. Hypertable 安装 Hypertable 的几种安装方式 单机:安装于单机,采用本地文件系统 Hadoop:分布式安装,使用Hadoop(HDFS)作为存储 MapR:分布式安装,在MapR之上 Ceph:分布式安装,在Ceph之上 4.1.1. Hypertable standalone 单机安装 过程 4.1. Hypertabl
-
os: ubuntu 16.04 db: postgresql 10.6 版本 # lsb_release -a No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 16.04.5 LTS Release: 16.04 Codename: xenial # # su - postgres $ psql -
-
row_predicate --> RowInterval //select x2 from tab_cdr_mini where row='ba10027296931352435797'; @Test public void test1() { Utils.print("test1"); IThriftClient client = ThriftClientPool.getInstance().
-
今天在玩儿时序数据库TimescaleDB时,发现创建hypertable会发生错误,具体如下所示: ERROR] function create_hypertable(unknown, unknown) does not exist LINE 1: SELECT create_hypertable('temp_table1', 'time') ^ HINT: No
-
分布式支持 数据访问层支持分布式数据库,包括读写分离,要启用分布式数据库,需要开启数据库配置文件中的deploy参数: return [ // 启用分布式数据库 'deploy' => 1, // 数据库类型 'type' => 'mysql', // 服务器地址 'hostname' => '192.168.1.1,19
-
一个成功的技术,现实的优先级必须高于公关,你可以糊弄别人,但糊弄不了自然规律。 ——罗杰斯委员会报告(1986) 在本书的第一部分中,我们讨论了数据系统的各个方面,但仅限于数据存储在单台机器上的情况。现在我们到了第二部分,进入更高的层次,并提出一个问题:如果多台机器参与数据的存储和检索,会发生什么? 你可能会出于各种各样的原因,希望将数据库分布到多台机器上: 可扩展性 如果你的数据量、读取负载、写
-
这里我的疑问是,如果我使用多个分布式数据库,cam如何在配置(application.properties)中提到不同的DB源URL?目前我正在使用以下结构来使用一个数据库, 就像上面那样。 所以,如果我使用多个DB用于多个区域,我如何在这里给出有条件的配置?我是微服务世界和分布式数据库设计模式的新手。
-
我将hazelcast服务器分布在多个节点上。我假设hazelcast将在集群中分发任何IMap数据,这样每个节点都将拥有属于映射的数据。这是建立集群后默认情况下应该发生的事情,还是需要在hazelcast.xml中设置代码或配置?
-
本文向大家介绍NoSQL数据库的分布式算法详解,包括了NoSQL数据库的分布式算法详解的使用技巧和注意事项,需要的朋友参考一下 今天,我们将研究一些分布式策略,比如故障检测中的复制,这些策略用黑体字标出,被分为三段: 数据一致性。NoSQL需要在分布式系统的一致性,容错性和性能,低延迟及高可用之间作出权衡,一般来说,数据一致性是一个必选项,所以这一节主要是关于 数据复制 和 数据恢复 。 数据放置
-
主要内容:并行化集合,外部数据集RDD(弹性分布式数据集)是Spark的核心抽象。它是一组元素,在集群的节点之间进行分区,以便我们可以对其执行各种并行操作。 有两种方法可以用来创建RDD: 并行化驱动程序中的现有数据 引用外部存储系统中的数据集,例如:共享文件系统,HDFS,HBase或提供Hadoop InputFormat的数据源。 并行化集合 要创建并行化集合,请在驱动程序中的现有集合上调用的方法。复制集合的每个元素以形成