
YugaByte DB 是一个高性能、云原生的分布式 SQL 数据库。
值得关注的特性包括:
- 可插入式的查询层,支持两个分布式 SQL APIs:
- YugaByte SQL (YSQL) - PostgreSQL 兼容的关系型 API
- YugaByte Cloud QL (YCQL) - 半关系型的类 SQL API ,支持文档/索引和 Apache Cassandra QL roots
- 基于Google Spanner设计的自动分片,共识复制和分布式事务架构
- 提供水平伸缩能力、强一致性以及高可用性
- 极具弹性 - 可自动容忍磁盘,节点,区域和区域故障
- 支持地理分布式部署(多区域,多区域,多云)
- 可以部署在公共云,也可以部署在 Kubernetes 内部
- 开源许可证 Apache 2.0 license
YugaByte DB 整体架构:
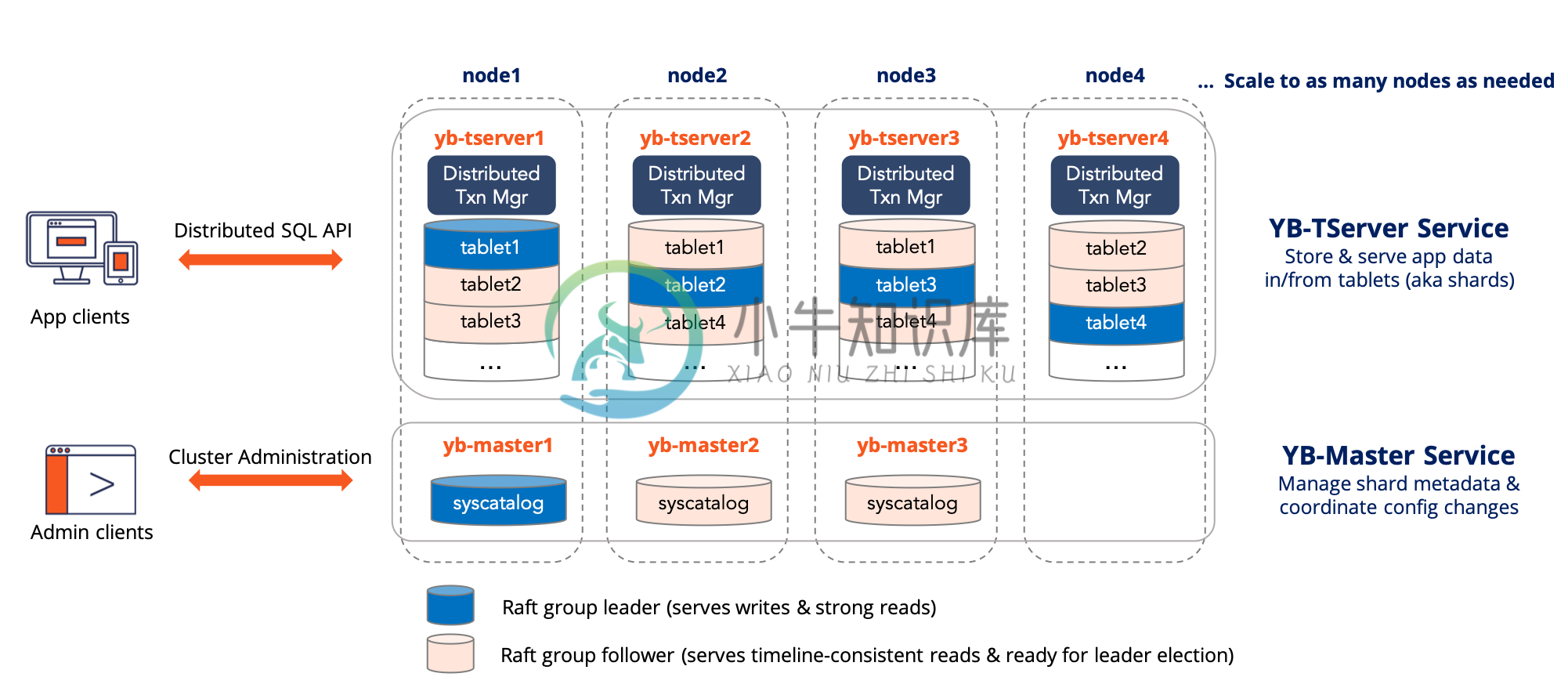
YugaByte DB 的查询层结构:

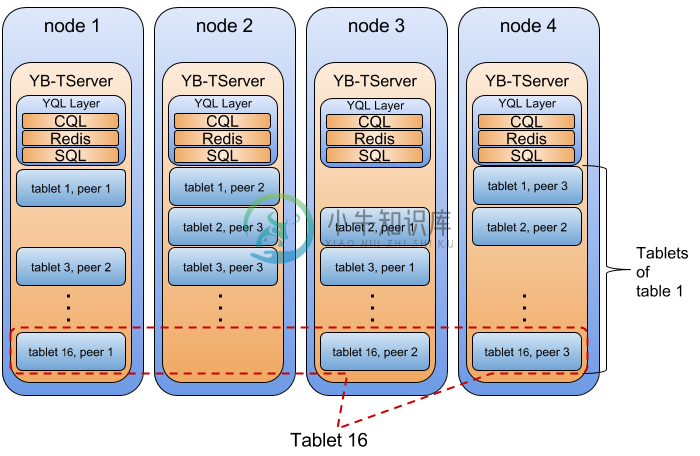
四个节点的 YugaByte DB 的结构:
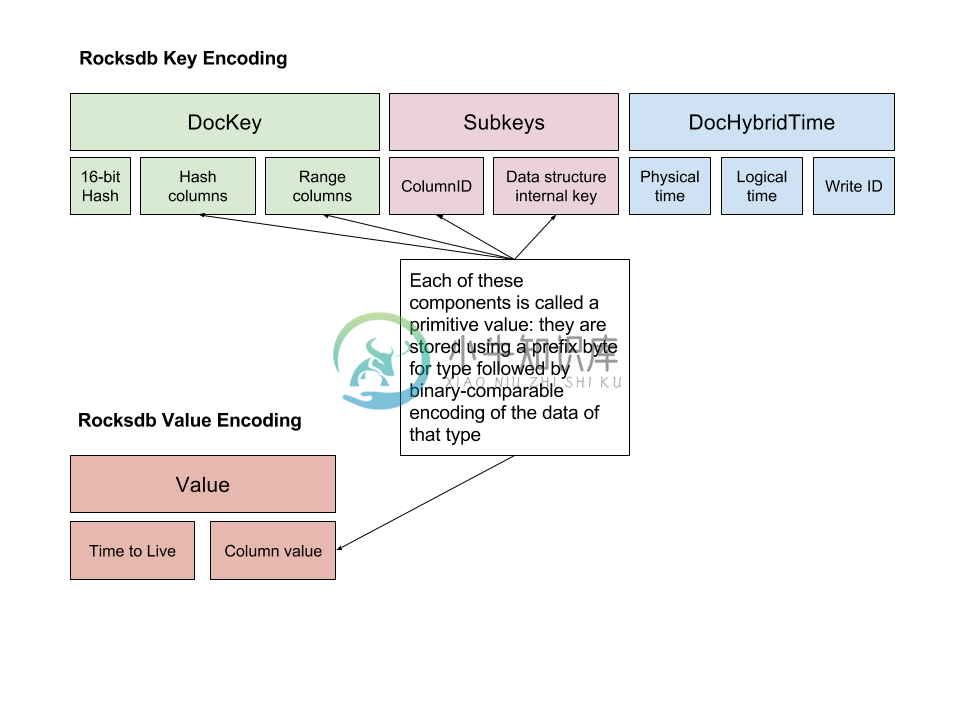
YugaByte DB 的存储层是基于 RocksDB 的,结构如下:
-
YugaByte DB 分布式 开源 关系型数据库介绍 什么是YugaByte DB? YugaByte DB是一个高性能的分布式SQL数据库,用于为全球互联网规模的应用程序提供支持。YugaByte DB使用高性能文档存储,自动分片,每分片分布式共识复制和多分片ACID事务(受Google Spanner启发)的独特组合构建,提供横向扩展RDBMS和低规模的Internet规模OLTP工作负
-
分布式支持 数据访问层支持分布式数据库,包括读写分离,要启用分布式数据库,需要开启数据库配置文件中的deploy参数: return [ // 启用分布式数据库 'deploy' => 1, // 数据库类型 'type' => 'mysql', // 服务器地址 'hostname' => '192.168.1.1,19
-
YugaByte 是用于构建关键任务应用程序的云原生数据库。此 repo 是 YugaByte Community Edition。 YugaByte 同时提供了 SQL 和 NoSQL,保证了正确性和可用性。它允许应用程序在云中、本地或跨混合环境中轻松伸缩规模,而不会增加运营复杂度或增加停机风险。 在数据模型和 API 方面,YugaByte 在通用核心数据平台之上支持以下内容: Cassand
-
这里我的疑问是,如果我使用多个分布式数据库,cam如何在配置(application.properties)中提到不同的DB源URL?目前我正在使用以下结构来使用一个数据库, 就像上面那样。 所以,如果我使用多个DB用于多个区域,我如何在这里给出有条件的配置?我是微服务世界和分布式数据库设计模式的新手。
-
一个成功的技术,现实的优先级必须高于公关,你可以糊弄别人,但糊弄不了自然规律。 ——罗杰斯委员会报告(1986) 在本书的第一部分中,我们讨论了数据系统的各个方面,但仅限于数据存储在单台机器上的情况。现在我们到了第二部分,进入更高的层次,并提出一个问题:如果多台机器参与数据的存储和检索,会发生什么? 你可能会出于各种各样的原因,希望将数据库分布到多台机器上: 可扩展性 如果你的数据量、读取负载、写
-
主要内容:1.UUID,2.数据库自增Id,3.基于数据库集群模式,4.基于数据库的号段模式,5.Redis,6.Snowflake,7.百度(uid-generator),8.Leaf,9.TinyId生成方式: 1.UUID 2.数据库自增ID 3.数据库多主模式 4.号段模式 5.Redis 6.雪花算法(SnowFlake) 7.滴滴出品(TinyID) 8.百度 (Uidgenerator) 9.美团(Leaf) 1.UUID UUID的生成简单到只有一行代码,输出结果 c2b8c2b
-
要想搞明云原生的未来,首先我们要弄明白云原生是什么。CNCF给出的定义是: 容器化 微服务 容器可以动态调度 我认为云原生实际上是一种理念或者说是方法论,它包括如下四个方面: 容器化:作为应用包装的载体 持续交付:利用容器的轻便的特性,构建持续集成和持续发布的流水线 DevOps:开发与运维之间的协同,上升到一种文化的层次,能够让应用快速的部署和发布 微服务:这是应用开发的一种理念,将单体应用拆分
-
本文向大家介绍NoSQL数据库的分布式算法详解,包括了NoSQL数据库的分布式算法详解的使用技巧和注意事项,需要的朋友参考一下 今天,我们将研究一些分布式策略,比如故障检测中的复制,这些策略用黑体字标出,被分为三段: 数据一致性。NoSQL需要在分布式系统的一致性,容错性和性能,低延迟及高可用之间作出权衡,一般来说,数据一致性是一个必选项,所以这一节主要是关于 数据复制 和 数据恢复 。 数据放置
-
在前面我们已经掌握了Scrapy框架爬虫,虽然爬虫是异步多线程的,但是我们只能在一台主机上运行,爬取效率还是有限。 分布式爬虫则是将多台主机组合起来,共同完成一个爬取任务,将大大提高爬取的效率。 16.1 分布式爬虫架构 回顾Scrapy的架构: Scrapy单机爬虫中有一个本地爬取队列Queue,这个队列是利用deque模块实现的。 如果有新的Request产生,就会放到队列里面,随后Reque