
Citus 是一个基于最新 PostgreSQL 构建的分布式数据库。CitusDB 可对 PostgreSQL 数据库进行伸缩以适合大数据的处理。可在集群中进行自动分片和碎片复制,运行在云端或者混合系统中。数据库的查询可在集群中进行分布式处理,充分利用集群中每个节点的计算能力。CitusDB 可提升 PostgreSQL 的高并发性和 JSON 支持,可用作事务以及分析数据库场景。
CitusDB 将你的数据库在集群中进行分布,对你的应用来说 CitusDB 就像是一个单一节点的 PostgreSQL 服务,对应用来说是透明的。集群中可轻松添加节点。
CitusDB 可将查询分布到集群中的每个节点,可用于快速处理查询以及并行处理。这比单一节点的 PG 数据库速度要快很多,理论上在20个节点的集群里运行速度是单一节点的 20 倍。
CitusDB 基于最新版本的 PG 数据库构建,是一个 PostgreSQL 的扩展,因此应用可以无缝的切换到 CitusDB 上。
CitusDB 架构:
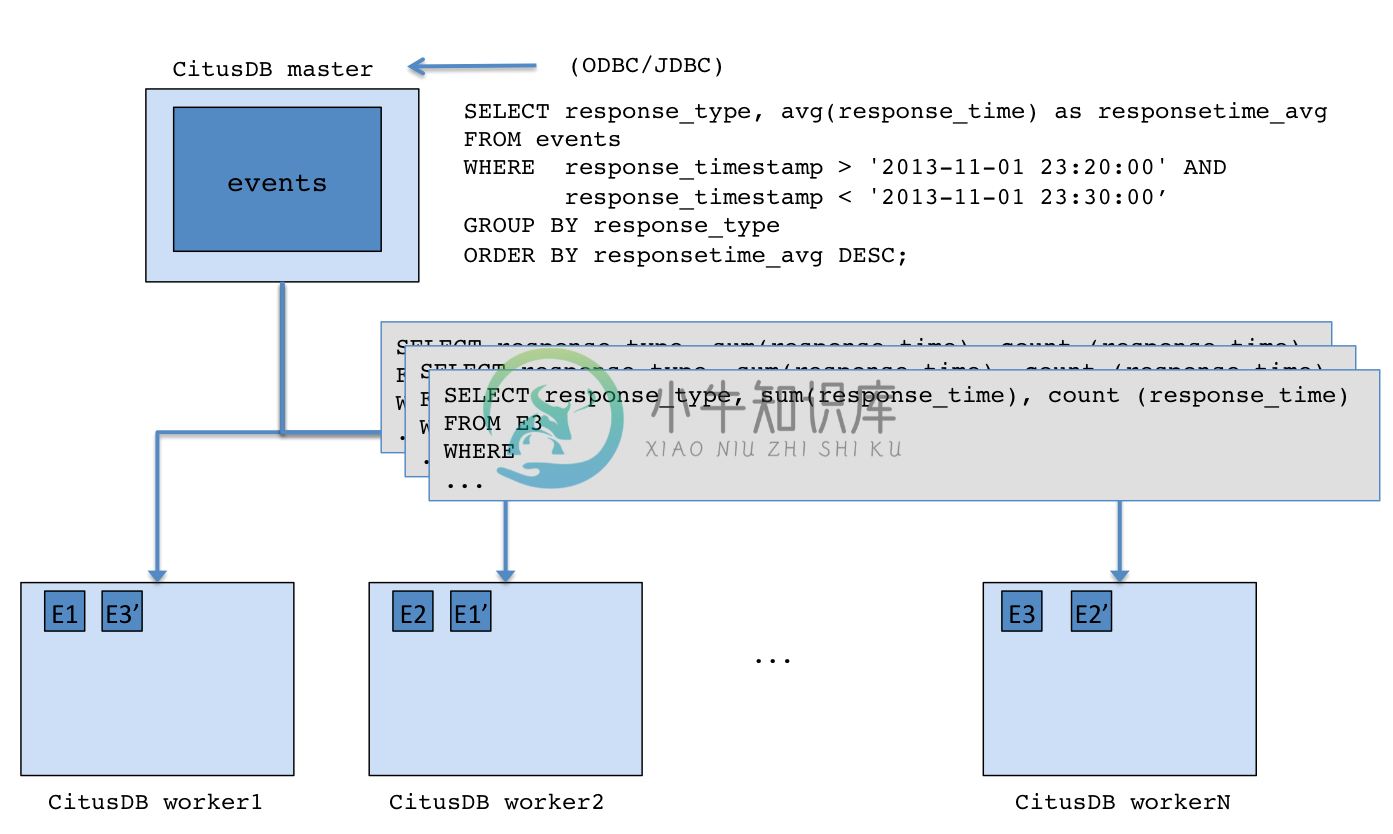
-
CitusData:Citus DB分布式数据库系统是一个将SQL的表现力、关系型数据库的性能,以及Hadoop的可扩展性与可用性有效地整合的数据库产品。 <p>CitusDB分布式数据库特点:</p> <p>1、强大的数据处理引擎可以在两个设备间同时运转。</p> <p>2、无限量的增加节点,可以快速的处理大量数据。</p> <p>3、通过切除数据库为一个个小块,复制那些数据,在
-
本文讲的是分析数据库CitusDB:提供弹性计算能力,企业数据库市场很庞大,在这个领域既有Oracle这样行家,也有IBM(DB2)和微软(SQL Server)这样的跨界巨头。它们都与中小企业常用到的开源数据库MySQL一样,都属于传统关系型数据库。似乎数据库市场已经发展得很成熟,基本格局也已确定,所以创业者再无机会? 事实上并非如此,新技术的出现与发展,总是会带来新的机遇。正如面向对象编程
-
[url]http://www.oschina.net/p/citusdb[/url] CitusDB 是一个基于最新 PostgreSQL 构建的分布式数据库。CitusDB 可对 PostgreSQL 数据库进行伸缩以适合大数据的处理。可在集群中进行自动分片和碎片复制,运行在云端或者混合系统中。数据库的查询可在集群中进行分布式处理,充分利用集群中每个节点的计算能力。CitusDB 可提升 Po
-
#导出成csv COPY (select * from tableName) to ‘/opt/a.csv’ with csv ; #导入csv \COPY tableNameFROM ‘/opt/a.csv’ WITH (format CSV)
-
单机citus安装 环境 centos6.5 postgres9.5 citus5.2 安装postgres (yum安装方式:https://yum.postgresql.org/repopackages.php) cd /opt wget https://download.postgresql.org/pub/repos/yum/9.5/redhat/rhel-6-x86_64/pgdg-ce
-
前言 从可靠性和使用便利性来讲单机RDBMS完胜N多各类数据库,但当数据量到了一定量之后,又不得不寻求分布式,列存储等等解决方案。citus是基于PostgreSQL的分布式实时分析解决方案,由于其只是作为PostgreSQL的扩展插件而没有动PG内核,所有随快速随PG主版本升级,可靠性也非常值得信任。 citus在支持SQL特性上有一定的限制,比如不支持跨库事务,不支持部分join和子查询的写法
-
CitusDB的upsert功能 postgresql9.5 版本支持 "UPSERT" 特性, 这个特性支持 INSERT 语句定义 ON CONFLICT DO UPDATE/IGNORE 属性,当插入 SQL 违反约束的情况下定义动作,而不抛出错误。 环境 citus62_96(默认安装的postgresql9.6) $ psql -V psql (PostgreSQL) 9.6.3 测试
-
现在k8s在2.3中直接与spark集成了,我的spark submit从控制台在kuberenetes master上正确执行,而没有运行任何spark master pods,spark处理k8s的所有细节: 我正在尝试做的是做一个火花-提交通过AWS lambda到我的k8s集群。以前,我直接通过spark master REST API(不使用kubernetes)使用该命令: 而且奏效了
-
本文向大家介绍基于docker搭建redis集群的方法,包括了基于docker搭建redis集群的方法的使用技巧和注意事项,需要的朋友参考一下 下载redis镜像 取别名 删除原先的镜像标签 启动6个节点的redis容器 注意网络用的是net1 创建的容器默认是没有启动,所以需要一个一个启动 进入任意一个容器例如r1 然后利用ruby脚本启动集群 输入yes即可创建成功,执行脚本时终端输出
-
本文向大家介绍postgresql 备份整个集群,包括了postgresql 备份整个集群的使用技巧和注意事项,需要的朋友参考一下 示例 通过为每个数据库建立一次与服务器的多个连接并pg_dump在其上执行,该操作在后台进行。 有时,您可能会倾向于将其设置为cron作业,因此您想查看备份作为文件名一部分的日期: 但是,请注意,这可能会每天产生大量文件。Postgresql具有更好的常规备份机制-W
-
本文向大家介绍Java基于elasticsearch实现集群管理,包括了Java基于elasticsearch实现集群管理的使用技巧和注意事项,需要的朋友参考一下 这篇文章主要介绍了java基于elasticsearch实现集群管理,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 本篇文章主要是查看集群中的相关信息,具体请看代码和注释 以上就是本文
-
本文向大家介绍基于redis集群设置密码的实例,包括了基于redis集群设置密码的实例的使用技巧和注意事项,需要的朋友参考一下 注意事项: 1.如果是使用redis-trib.rb工具构建集群,集群构建完成前不要配置密码,集群构建完毕再通过config set + config rewrite命令逐个机器设置密码 2.如果对集群设置密码,那么requirepass和masterauth都需要设置,
-
问题内容: 我最近一直念叨如何和作品。我的理解很简单(如果有错,请纠正我): 的数据结构,其背和IS :根据索引列(或键)对数据进行物理排序。每个只能有一个。如果在创建表的过程中未指定No ,则服务器将在上自动创建一个。 问题1 :由于数据是根据索引进行物理排序的,因此这里不需要额外的空间。这样对吗?那么,当我删除创建的索引时会发生什么? :在中,树的包含列值和指向数据库中实际行的指针(行定位符)