
kk-anti-reptile是,适用于基于spring-boot开发的分布式系统的反爬虫组件。
系统要求
- 基于spring-boot开发(spring-boot1.x, spring-boot2.x均可)
- 需要使用redis
工作流程
kk-anti-reptile使用基于Servlet规范的的Filter对请求进行过滤,在其内部通过spring-boot的扩展点机制,实例化一个Filter,并注入到Spring容器FilterRegistrationBean中,通过Spring注入到Servlet容器中,从而实现对请求的过滤
在kk-anti-reptile的过滤Filter内部,又通过责任链模式,将各种不同的过滤规则织入,并提供抽象接口,可由调用方进行规则扩展
Filter调用则链进行请求过滤,如过滤不通过,则拦截请求,返回状态码509,并输出验证码输入页面,输出验证码正确后,调用过滤规则链对规则进行重置
目前规则链中有如下两个规则
ip-rule
ip-rule通过时间窗口统计当前时间窗口内请求数,小于规定的最大请求数则可通过,否则不通过。时间窗口、最大请求数、ip白名单等均可配置
ua-rule
ua-rule通过判断请求携带的User-Agent,得到操作系统、设备信息、浏览器信息等,可配置各种维度对请求进行过滤
命中规则后
命中爬虫和防盗刷规则后,会阻断请求,并生成接除阻断的验证码,验证码有多种组合方式,如果客户端可以正确输入验证码,则可以继续访问
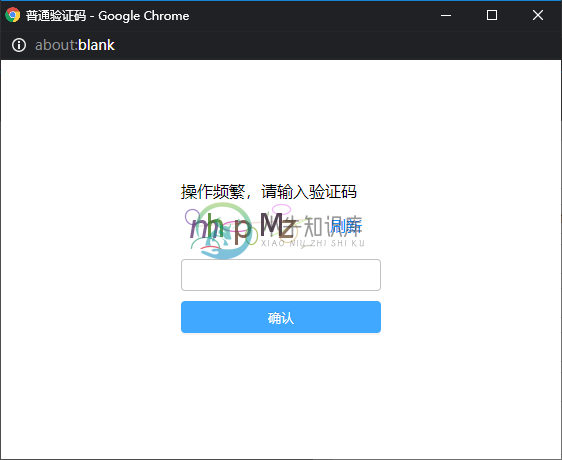
验证码有中文、英文字母+数字、简单算术三种形式,每种形式又有静态图片和GIF动图两种图片格式,即目前共有如下六种,所有类型的验证码会随机出现,目前技术手段识别难度极高,可有效阻止防止爬虫大规模爬取数据
![]()
![]()
![]()
![]()
![]()
![]()
接入使用
后端接入非常简单,只需要引用kk-anti-reptile的maven依赖,并配置启用kk-anti-reptile即可
加入maven依赖
<dependency>
<groupId>cn.keking.project</groupId>
<artifactId>kk-anti-reptile</artifactId>
<version>1.0.0-SNAPSHOT</version>
</dependency>
配置启用 kk-anti-reptile
anti.reptile.manager.enabled=true
前端需要在统一发送请求的ajax处加入拦截,拦截到请求返回状态码509后弹出一个新页面,并把响应内容转出到页面中,然后向页面中传入后端接口baseUrl参数即可,以使用axios请求为例:
import axios from 'axios';
import {baseUrl} from './config';
axios.interceptors.response.use(
data => {
return data;
},
error => {
if (error.response.status === 509) {
let html = error.response.data;
let verifyWindow = window.open("","_blank","height=400,width=560");
verifyWindow.document.write(html);
verifyWindow.document.getElementById("baseUrl").value = baseUrl;
}
}
);
export default axios;
注意
- apollo-client需启用bootstrap
使用apollo配置中心的用户,由于组件内部用到@ConditionalOnProperty,要在application.properties/bootstrap.properties中加入如下样例配置,(apollo-client需要0.10.0及以上版本)详见apollo bootstrap说明
apollo.bootstrap.enabled = true
- 需要有Redisson连接
如果项目中有用到Redisson,kk-anti-reptile会自动获取RedissonClient实例对象; 如果没用到,需要在配置文件加入如下Redisson连接相关配置
spring.redisson.address=redis://192.168.1.204:6379 spring.redisson.password=xxx
配置一览表
在spring-boot中,所有配置在配置文件都会有自动提示和说明,如下图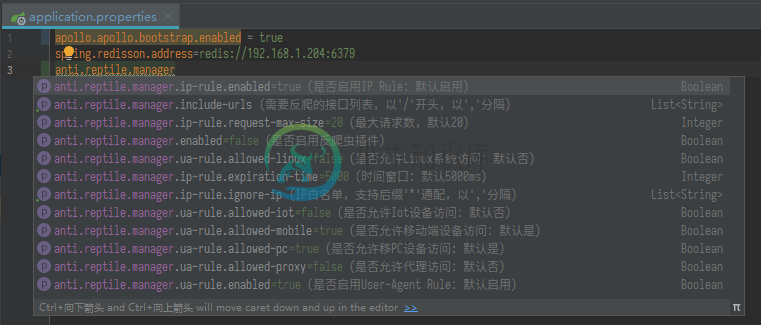
所有配置都以anti.reptile.manager为前缀,如下为所有配置项及说明
| NAME | 描述 | 默认值 | 示例 |
|---|---|---|---|
| enabled | 是否启用反爬虫插件 | true | true |
| include-urls | 需要反爬的接口列表,以'/'开头,以','分隔 | 空 | /client,/user |
| ip-rule.enabled | 是否启用IP Rule | true | true |
| ip-rule.expiration-time | 时间窗口长度(ms) | 5000 | 5000 |
| ip-rule.request-max-size | 单个时间窗口内,最大请求数 | 20 | 20 |
| ip-rule.ignore-ip | IP白名单,支持后缀'*'通配,以','分隔 | 空 | 192.168.*,127.0.0.1 |
| ua-rule.enabled | 是否启用User-Agent Rule | true | true |
| ua-rule.allowed-linux | 是否允许Linux系统访问 | false | false |
| ua-rule.allowed-mobile | 是否允许移动端设备访问 | true | true |
| ua-rule.allowed-pc | 是否允许移PC设备访问 | true | true |
| ua-rule.allowed-iot | 是否允许物联网设备访问 | false | false |
| ua-rule.allowed-proxy | 是否允许代理访问 | false | false |
-
具体内容来自 github:https://github.com/kekingcn/kk-anti-reptile
-
有的时候,当我们的爬虫程序完成了,并且在本地测试也没有问题,爬取了一段时间之后突然就发现报错无法抓取页面内容了。这个时候,我们很有可能是遇到了网站的反爬虫拦截。 我们知道,网站一方面想要爬虫爬取网站,比如让搜索引擎爬虫去爬取网站的内容,来增加网站的搜索排名。另一方面,由于网站的服务器资源有限,过多的非真实的用户对网站的大量访问,会增加运营成本和服务器负担。 因此,有些网站会设置一些反爬虫的措施。我
-
本文向大家介绍Python反爬虫伪装浏览器进行爬虫,包括了Python反爬虫伪装浏览器进行爬虫的使用技巧和注意事项,需要的朋友参考一下 对于爬虫中部分网站设置了请求次数过多后会封杀ip,现在模拟浏览器进行爬虫,也就是说让服务器认识到访问他的是真正的浏览器而不是机器操作 简单的直接添加请求头,将浏览器的信息在请求数据时传入: 打开浏览器--打开开发者模式--请求任意网站 如下图:找到请求的的名字,打
-
本文向大家介绍关于爬虫和反爬虫的简略方案分享,包括了关于爬虫和反爬虫的简略方案分享的使用技巧和注意事项,需要的朋友参考一下 前言 爬虫和反爬虫日益成为每家公司的标配系统。 爬虫在情报获取、虚假流量、动态定价、恶意攻击、薅羊毛等方面都能起到很关键的作用,所以每家公司都或多或少的需要开发一些爬虫程序,业界在这方面的成熟的方案也非常多。 有矛就有盾,每家公司也相应的需要反爬虫系统来达到数据保护、系统稳定
-
这一章将会介绍使用一些新的模块(optparse,spider)去完成一个爬虫的web应用。爬虫其实就是一个枚举出一个网站上面的所有链接,以帮助你创建一个网站地图的web应用程序。而使用Python则可以很快的帮助你开发出一个爬虫脚本. 你可以创建一个爬虫脚本通过href标签对请求的响应内容进行解析,并且可以在解析的同时创建一个新的请求,你还可以直接调用spider模块来实现,这样就不需要自己去写
-
python爬虫时显示 [WinError 10061] 由于目标计算机积极拒绝,无法连接。 import csv import random import time import pandas as pd import requests from bs4 import BeautifulSoup import matplotlib.pyplot as plt plt.rcParams["font
-
13. 视频直播防盗链规则 13.1. 鉴权构造 用户访问加密防盗链 URL 地址构成 http://DomainName/AppName/StreamName?sign=xxxxxxxxx&stTime=xxxxxxx k=md5(“key”+“/AppName/”+“StreamName”+t) 参数 描述 key 后台生成的秘钥 AppName 流所属应用名称 StreamName 流名称