
Orchestrator 是 MySQL 复制拓扑管理和可视化工具,支持:
检测和审查复制集群
安全拓扑重构:转移服务于另外一台计算机的系统拓扑S
整洁的拓扑可视化
复制问题可视化
通过简单的拖拽修改拓扑
维护模式声明和执行
审计操作
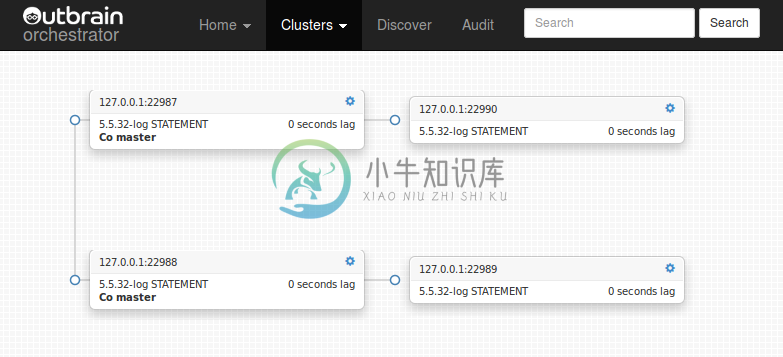
重构拓扑只需要简单的拖拽。Orchestrator 会保证安全,并且禁止非法复制拓扑。
-
沃趣科技作为国内领先的数据库云平台解决方案提供商,一直致力于企业级数据库云平台产品的研发,为用户提供高性能、高可用、可扩展的的数据库云环境及不同业务场景需求的数据库平台,满足客户对极致性能、数据安全、容灾备份、业务永续等需求。沃趣科技凭借专业的团队,优质的产品,前沿的技术,贴心的服务赢得了客户的信任与尊重,也获得了市场的认同。 前言 上篇文章讲了orchestrator的探测机制。本篇文章翻译自o
-
CSDN不保证及时更新, 最新文档翻译在https://github.com/Fanduzi/orchestrator-chn-doc 求star 配置参数详解-III ApplyMySQLPromotionAfterMasterFailover 类型: bool 默认值: true 当为true 时, orchestrator 将在选举出的新主库上执行reset slave all 和set
-
orchestrator的discover原理 当我们发出命令: orchestrator-client -c discover -i hostname:port 首先,orchestrator会发现给定的实例,即命令中的hostname:port这个实例,然后进而通过该实例来发现整个拓补结构。 具体如何进行发现?通过以下两步进行discover: 1、使用MySQLHostnameResolv
-
orchestrator-client是客户端命令(/usr/local/orchestrator/resources/bin) orchestrator是服务端命令(/usr/local/orchestrator) 1. 常用命令 在生产上部署Orchestrator,可以参考文档2。 1.Orchestrator首先需要确认本身高可用的后端数据库是用单个MySQL,MySQL复制还是本身的Ra
-
前言 上篇文章中:《orchestrator的discover模块》主要讲述的是在client发出discover这个命令后,orchestrator服务端所采取的动作,那么,后续的持续discover,是如何实现,并且如何探测到失败实例的呢,今天这篇文章就来讲述这方面的内容。 持续发现 入口函数在:logic/orchestrator.go文件: ContinuousDiscovery()函数调
-
Orchestrator解读 第一部分 最近在二次开发Orchestrator,所以研读了一下优雅切换部分的代码。 入口 首先,通过orchestrator-client来做为客户端请求入口来说明: 代码位于: orchestrator/resources/bin/orchestrator-client main: function main { check_requirements d
-
介绍 在MySQL高可用架构中,目前使用比较多的是Percona的PXC,Galera以及MySQL 5.7之后的MGR等,其他的还有的MHA,今天介绍另一个比较好用的MySQL高可用复制管理工具:Orchestrator(orch)。 Orchestrator(orch):go编写的MySQL高可用性和复制拓扑管理工具,支持复制拓扑结构的调整,自动故障转移和手动主从切换等。后端数据库用MySQL
-
一、自动切换 orchestrator自动切换需要满足以下条件: 主库是downtime的集群不进行故障切换。如果希望忽略集群故障,可以设置downtime。 处于故障活跃期的集群不进行故障切换(即in_active_period=1) 只对配置项RecoverMasterClusterFilters匹配的集群进行故障切换 会周期检测主库状态。 自动切换,会周期进行故障扫描,如果发现故障,条件满足
-
在准备拓扑优化时,我偶然发现了以下几点: 目前,Kafka Streams在启用时会执行两种优化: 1-源KTable将源主题重新用作变更日志主题。 2-如果可能,Kafka流会将多个重新分区主题压缩为单个重新分区主题。 这个问题是关于第一点的。我不完全明白这里发生了什么。只是为了确保我没有在这里做任何假设。有人能解释一下,以前是什么状态吗: 1-KTable使用内部变更日志主题吗?如果是,有人能
-
有人能告诉我如何复制我所在的行,就像大多数人在visual studio代码中做的那样,并为我列出一些快捷方式或我可以在哪里看到它们吗?/.
-
我正在运行一个3节点的Storm集群。我们正在提交一个包含10个工作者的拓扑结构,以下是拓扑结构的详细信息 我们每天处理800万到1000万个数据。问题是topolgy只运行了2到3天,而我们在kafka spout中看到了一些失败的元组,没有处理任何消息。当提交新的topolgy时,它工作良好,但在2到3天后,我们又看到了同样的问题。有人能给我们一个解决方案吗。下面是我的storm配置
-
为了表明计算机科学家可以把任何东西变成一个图问题,让我们考虑做一批煎饼的问题。 菜谱真的很简单:1个鸡蛋,1杯煎饼粉,1汤匙油 和 3/4 杯牛奶。 要制作煎饼,你必须加热炉子,将所有的成分混合在一起,勺子搅拌。 当开始冒泡,你把它们翻过来,直到他们底部变金黄色。 在你吃煎饼之前,你会想要加热一些糖浆。 Figure 27将该过程示为图。 Figure 27 制作煎饼的困难是知道先做什么。从 Fi
-
一、拓扑排序介绍 拓扑排序(Topological Order)是指,将一个有向无环图(Directed Acyclic Graph简称DAG)进行排序进而得到一个有序的线性序列。 这样说,可能理解起来比较抽象。下面通过简单的例子进行说明! 例如,一个项目包括A、B、C、D四个子部分来完成,并且A依赖于B和D,C依赖于D。现在要制定一个计划,写出A、B、C、D的执行顺序。这时,就可以利用到拓扑排序
-
我正在尝试使用Eclipse在Linux中运行Storm启动示例。我收到以下错误和函数从未被调用。 错误: 我的拓扑类: 我正在虚拟机环境中工作,所以不知道这是否是由于安装了Zookeeper。有什么想法吗?
-
8台机器一直在使用。每一个都有22个核心和512 GB的RAM。但是,我们的代码运行得真的很慢。传输600万个数据需要10分钟才能完成。 60个文件中的10 MB在一秒钟内传输到HDFS。我们正在努力优化我们的代码,但很明显我们做了一些非常错误的事情。 对于蜂巢表,我们有64个桶。 在HDFS喷口;.setmaxextending(50000); 在蜂巢喷口选项;.WithTxNsperBatch