
Atlas 是一个可伸缩和可扩展的核心功能治理服务。企业可以利用它高效的管理 Hadoop 以及整个企业数据生态的集成。
核心功能包括:数据分类、集中审计、搜索、安全和策略引擎
架构:
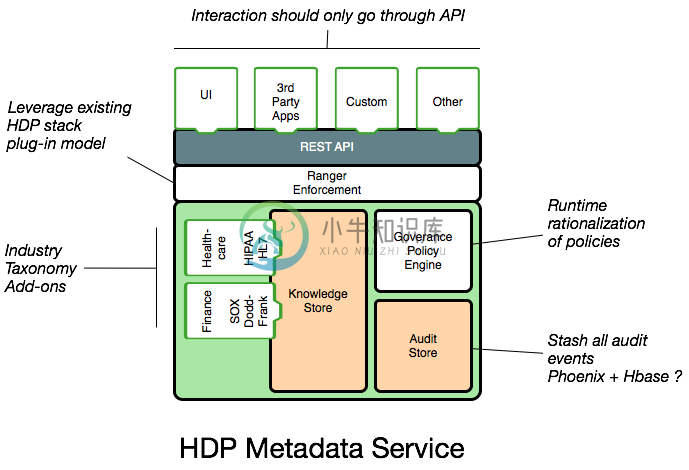
-
安装前环境准备 hadoop 3.1.0 hbase 2.3.4 hive 3.1.3 solr 7.7.3 zookeeper 3.5.7 kafka 2.11-2.4.1 atlas 2.3.0 大数据组件准备 **提示:apache组件历史版本下载地址https://archive.apache.org/dist/组件名字** **例如:hadoop:https://archive.apac
-
导览 本小节主要介绍 Apache ShardingSphere 分布式治理的相关功能 注册中心 第三方组件依赖
-
一、事务 概念 ACID AUTOCOMMIT 二、并发一致性问题 丢失修改 读脏数据 不可重复读 幻影读 三、封锁 封锁粒度 封锁类型 封锁协议 MySQL 隐式与显示锁定 四、隔离级别 未提交读(READ UNCOMMITTED) 提交读(READ COMMITTED) 可重复读(REPEATABLE READ) 可串行化(SERIALIZABLE) 五、多版本并发控制 基本思想 版本号 Un
-
SOFADashboard 服务治理主要是对 SOFARpc 的服务进行管理。 目前已经支持基于 ZK 和 SofaRegistry 两个注册中心。 功能展示 1、基于服务维度 服务列表 服务提供者详情: 2、基于应用维度 应用列表 应用服务详情
-
服务治理配置 黑白名单 "Server": { "Name": "sample", "Ip": "192.168.3.11", "Port": "5003", "Security": { "Whitelist": "*", //白名单 格式:ip1|ap2|1p3,默认 * "BlackList": "" //黑名单 格式:ip1|ap2|1p3,默认 "" } } 负载
-
分而治之 方法介绍 对于海量数据而言,由于无法一次性装进内存处理,导致我们不得不把海量的数据通过hash映射分割成相应的小块数据,然后再针对各个小块数据通过hash_map进行统计或其它操作。 那什么是hash映射呢?简单来说,就是为了便于计算机在有限的内存中处理big数据,我们通过一种映射散列的方式让数据均匀分布在对应的内存位置(如大数据通过取余的方式映射成小数存放在内存中,或大文件映射成多个小
-
服务治理 服务治理主要作用是改变运行时服务的行为和选址逻辑,达到限流,权重配置等目的,主要有以下几个功能: 应用级别的服务治理 在Dubbo2.6及更早版本中,所有的服务治理规则都只针对服务粒度,如果要把某条规则作用到应用粒度上,需要为应用下的所有服务配合相同的规则,变更,删除的时候也需要对应的操作,这样的操作很不友好,因此Dubbo2.7版本中增加了应用粒度的服务治理操作,对于条件路由(包括黑白
-
本章介绍 Kubernetes 服务治理,包括容器应用管理、Service Mesh 以及 Operator 等。 目前最常用的是手动管理 Manifests,比如 kubernetes github 代码库就提供了很多的 manifest 示例 https://github.com/kubernetes/kubernetes/tree/master/examples https://github
-
ShardingSphere-Proxy 支持使用 SPI 方式接入分布式治理,实现配置和元数据统一管理以及实例熔断和从库禁用等功能。 Zookeeper ShardingSphere-Proxy 默认提供了 Zookeeper 解决方案,实现了注册中心功能。 配置规则同 ShardingSphere-JDBC YAML 保持一致。 其他第三方组件 详情请参考支持的第三方组件。 使用 SPI 方式