
Cobar是关系型数据的分布式处理系统,它可以在分布式的环境下像传统数据库一样为您提供海量数据服务。以下是快速启动场景:
-
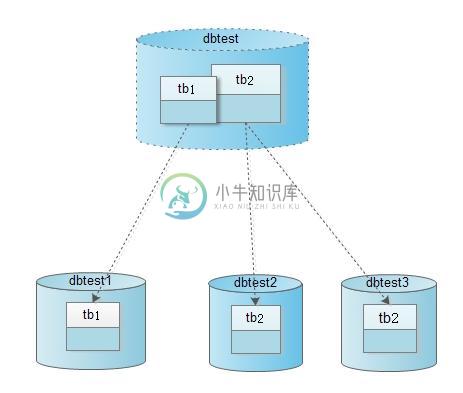
系统对外提供的数据库名是dbtest,并且其中有两张表tb1和tb2。
-
tb1表的数据被映射到物理数据库dbtest1的tb1上。
-
tb2表的一部分数据被映射到物理数据库dbtest2的tb2上,另外一部分数据被映射到物理数据库dbtest3的tb2上。
如下图所示:
产品约束
-
使用JDBC时,推荐使用5.1以上版本Driver进行连接
-
不支持跨库的关联操作:join、分页、排序、子查询。
-
不支持rewriteBatchedStatements=true参数设置。默认为false
-
不支持useServerPrepStmts=true参数设置。默认为false
-
BLOB, BINARY, VARBINARY字段不能使用。若特殊需求需要这三种字段,禁止使用PreparedStatement的setBlob()或setBinaryStream()方法设置参数。
-
不支持SAVEPOINT操作。
-
不支持SET语句的执行,事务和字符集设置语句除外
-
对于拆分表(一个表的数据被映射到多个MySQL数据库),不能更新已有记录的拆分字段(分库字段)值
-
只支持MySQL数据节点。
-
对于拆分表,插入操作须给出列名,必须包含拆分字段。
-
关于淘宝Cobar中间件使用中一些问题总结,会在使用中不断完善该文档 1、LOAD DATA LOCAL FILE ...不支持 mysql> load data local infile "/usr/jfy/tmp/scpcdr.txt" into table scpcdr fields TERMINATED by '|'; ERROR 1148 (42000): The used
-
一,什么是cobar: cobar是提供关系型数据库(MYSQL)分布式服务的中间件,它可以让传统的数据库得到良好的线性扩展,并看上去还是一个数据库,对应用保持透明。 二,为什么要用cobar: 当数据不断上升,单库里面的表记录不断增加的时候,查询和索引的更变就会变得异常的缓慢,这时候我们会想到分库和分表(水平拆分和竖直拆分),cobar这个中间件就是专门用来分库和分表的。 当然新生儿mycat也
-
一,什么是cobar: cobar是提供关系型数据库(MYSQL)分布式服务的中间件,它可以让传统的数据库得到良好的线性扩展,并看上去还是一个数据库,对应用保持透明。 二,为什么要用cobar: 当数据不断上升,单库里面的表记录不断增加的时候,查询和索引的更变就会变得异常的缓慢,这时候我们会想到分库和分表(水平拆分和竖直拆分),cobar这个中间件就是专门用来分库和分表的。 当然新生儿mycat也
-
由于Cobar遵循MySQL协议,访问Cobar的方式与访问MySQL数据库完全相同 mysql命令行访问如下: mysql -h127.0.0.1 -utest -ptest -P8066 -Ddbtest 支持JDBC方式访问,支持用户使用JDBC连接池 jdbc:mysql://172.16.88.131:8066/testdb?user=test&password=test 也可以如下:
-
一种是关系数据库,典型代表产品:DB2; 另一种则是层次数据库,代表产品:IMS层次数据库。 非关系型数据库有MongoDB、memcachedb、Redis等。
-
本文向大家介绍Hive与关系型数据库的关系?相关面试题,主要包含被问及Hive与关系型数据库的关系?时的应答技巧和注意事项,需要的朋友参考一下 没有关系,hive是数据仓库,不能和数据库一样进行实时的CURD操作。 是一次写入多次读取的操作,可以看成是ETL工具。
-
每当我读到有关NoSQL分布式数据库的内容时,他们都会提到CAP定理,这意味着在分区系统中,您可以具有完全一致性,完全可用性或两者兼而有之,但不能完全两者兼而有之。 我不太清楚他们在谈论什么类型的一致性: 是数据新鲜度的一致性,其中一些客户端可能会获得比其他客户端更旧的数据吗? 或者是一致性,即事务可能仅部分完成,这可能会使数据处于不一致的状态? 第二种解释对我来说听起来很危险,不能真正接受。第一
-
问题内容: 让我们看一个例子-书。一本书可以有1..n位作者。作者可以拥有1..m本书。代表一本书的所有作者的一种好方法是什么? 我想到了一个创建Books表和Authors表的想法。Authors表具有一个主要AuthorID密钥,即作者的姓名。图书表具有主要的图书ID和有关图书的元数据(书名,出版日期等)。但是,需要一种将书籍链接到作者以及将作者链接到书籍的方法。这就是问题所在。 假设我们有三
-
关系数据库,是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。现实世界中的各种实体以及实体之间的各种联系均用关系模型来表示。关系模型由关系数据结构、关系操作集合、关系完整性约束三部分组成。
-
本文向大家介绍关系数据模型,包括了关系数据模型的使用技巧和注意事项,需要的朋友参考一下 关系数据模型是最著名的数据模型,全世界大多数人都在使用它,它是一种简单而有效的数据模型,并具有以最佳方式处理数据的能力。 表用于处理关系数据模型中的数据。包含有关公司员工数据的表格示例如下- <员工> Emp_Number Emp_Name Emp_Designation Emp_Age Emp_Salary
-
本文向大家介绍常见的关系型数据库管理系统产品有?相关面试题,主要包含被问及常见的关系型数据库管理系统产品有?时的应答技巧和注意事项,需要的朋友参考一下 答:Oracle、SQL Server、MySQL、Sybase、DB2、Access等。
-
出身背景 我们选择Cassandra作为我们的存储引擎,因为我们有一个应用程序,必须处理网站上许多用户之间的异步消息传递和事件存储(某些类型的分析,现场发生的事情以及何时发生等)。此外,我们有一个投票平台,所以我们每天为每个用户存储投票,Cassandra在这些用例中很好。 最近,我们有了在现有系统之上构建关系模型的新需求(至少我们认为它是关系的)。一些类型的政治候选人有工作、教育、历史投票、支持