
Cloudata 是一个分布式的大规模结构化数据存储解决方案,是 Google Bigtable 的开源 Java 实现。它是 DBMS(Database Management System) ,但不是关系型 DBMS,可存储超过 P 级的数据。
数据模型:
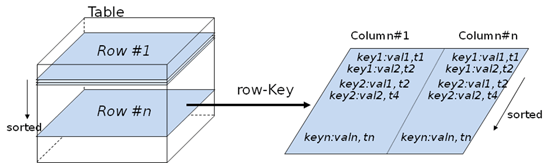
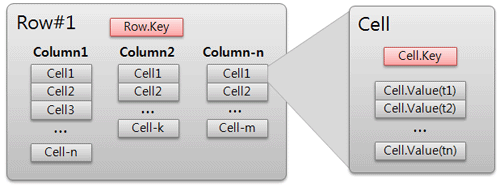
组件模型:
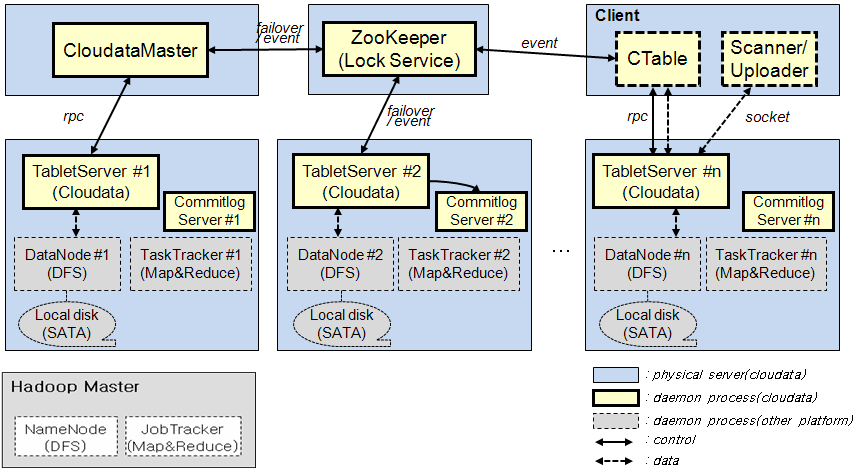
特性:
- 基本数据服务
- 单行操作(get, put)
- 多行操作(like, between, scanner)
- 数据上传(DirectUploader)
- MapReduce(TabletInputFormat)
- 简单 cloudata 查询和支持 JDBC 驱动
- 表管理
- 分表
- 分布
- 压缩
- 工具
- 基于 Web 的监控器
- CLI Shell
- 故障转移
- 主节点故障转移
- TabletServer 故障转移
- 更改日志服务器
- 可靠、快速、追加式的更改日志服务器
- 支持语言
- Java, RESTful API, Thrift
-
这里我的疑问是,如果我使用多个分布式数据库,cam如何在配置(application.properties)中提到不同的DB源URL?目前我正在使用以下结构来使用一个数据库, 就像上面那样。 所以,如果我使用多个DB用于多个区域,我如何在这里给出有条件的配置?我是微服务世界和分布式数据库设计模式的新手。
-
分布式支持 数据访问层支持分布式数据库,包括读写分离,要启用分布式数据库,需要开启数据库配置文件中的deploy参数: return [ // 启用分布式数据库 'deploy' => 1, // 数据库类型 'type' => 'mysql', // 服务器地址 'hostname' => '192.168.1.1,19
-
null 假设我有100张唱片。缓存只能保存40条记录(最常用)和100条记录在磁盘文件(不在任何其他数据库中)。 所以,如果从这100条记录中请求任何东西,我就不必去实际的数据库(例如Sybase db)? 如果在100条记录中找到了密钥,但它不存在于内存缓存中(40条记录),则获取该密钥,放入内存缓存中,并使用驱逐策略将其他密钥交换到磁盘文件中(但在磁盘上,我总是有100条记录) 如果缓存和磁
-
我们已经使用Drools引擎几年了,但是我们的数据已经增长了,我们需要找到一个新的分布式解决方案来处理大量数据。我们有复杂的规则,可以查看几天的数据,这就是为什么Drools非常适合我们,因为我们的内存中只有数据。 你对类似于流口水但分布式/可扩展的东西有什么建议吗? 我确实对这件事进行了研究,但我找不到任何符合我们要求的东西。 谢谢
-
问题内容: 我正在寻找Java分布式缓存解决方案。我们希望功能喜欢: 我们已经分析了Terracotta这样的框架,它似乎是缓存框架中我们想要的一切……但是,似乎需要一个中央缓存节点,这成为我们的单点故障。 除了推出我们自己的解决方案之外,还有其他想法吗? 问题答案: 我建议使用JBossCache或EhCache(使用分布式缓存侦听器)。我都用过,我都喜欢,它们都适合您的要求。
-
一个成功的技术,现实的优先级必须高于公关,你可以糊弄别人,但糊弄不了自然规律。 ——罗杰斯委员会报告(1986) 在本书的第一部分中,我们讨论了数据系统的各个方面,但仅限于数据存储在单台机器上的情况。现在我们到了第二部分,进入更高的层次,并提出一个问题:如果多台机器参与数据的存储和检索,会发生什么? 你可能会出于各种各样的原因,希望将数据库分布到多台机器上: 可扩展性 如果你的数据量、读取负载、写