
Milvus 向量数据库能够帮助用户轻松应对海量非结构化数据(图片/视频/语音/文本)检索。单节点 Milvus 可以在秒内完成十亿级的向量搜索(请参考:在线教程),分布式架构亦能满足用户的水平扩展需求。
Milvus 向量数据库的应用场景包括:互联网娱乐(图片搜索/视频搜索)、新零售(以图搜商品)、智慧金融(用户认证)和智能物流(车辆识别)等领域。
希望 Milvus 向量数据库能帮助更多的用户应对非结构数据和AI带来的机遇与挑战。
数据智能的挑战
随着信息化技术的不断进步,人们正经历爆炸式的数据增长。非结构数据(如图片、视频、语音和文字)比传统的结构化数据增长更快,数据量更大。之所以称其为非结构数据,是因为这些数据无法以传统方式进行处理与价值挖掘。如何从非结构数据中提取有价值的内容与信息,已经逐渐成为企业进一步挖掘数据价值的关键。
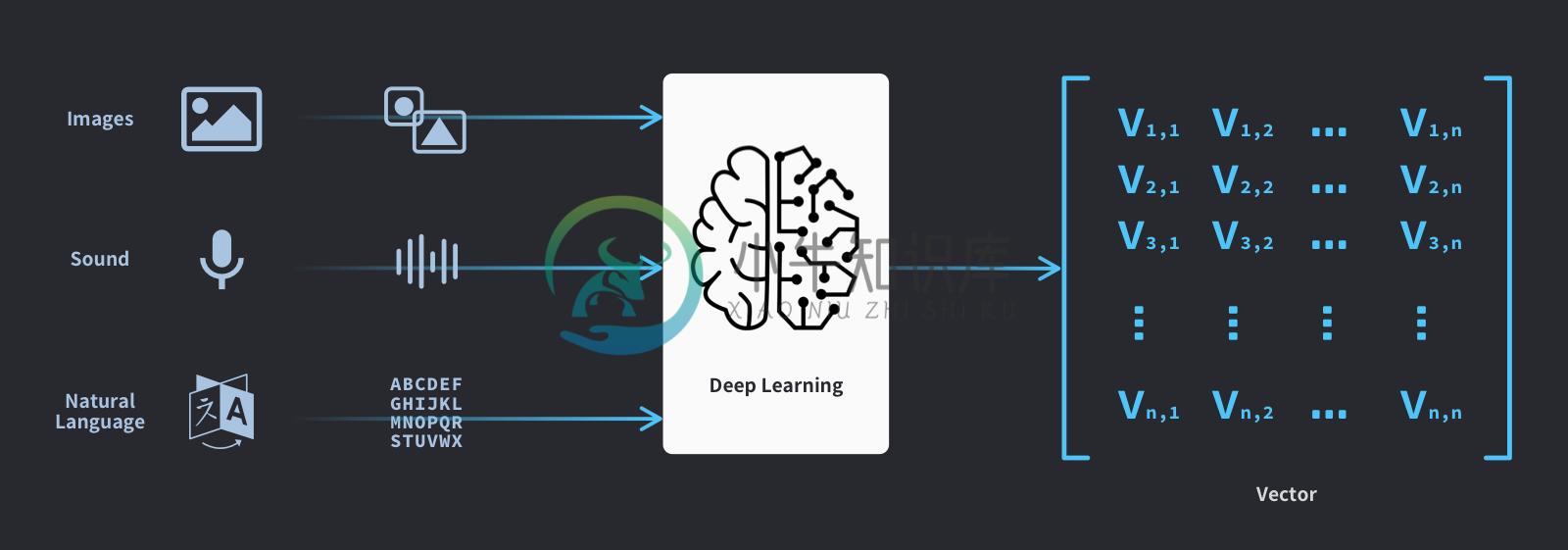
深度学习目前被认为是最有效的非结构数据处理方式之一。非结构数据经过深度学习模型的处理,会被向量化。于是,海量非结构数据的分析处理被转化为对海量向量的近似搜索。虽然处理图片,视频,语音和文字的深度学习模型各不相同,但最终的向量处理需求却是相同的。因此,向量数据库是 AI 应用的基石之一。
Milvus,开源 AI 基础组件
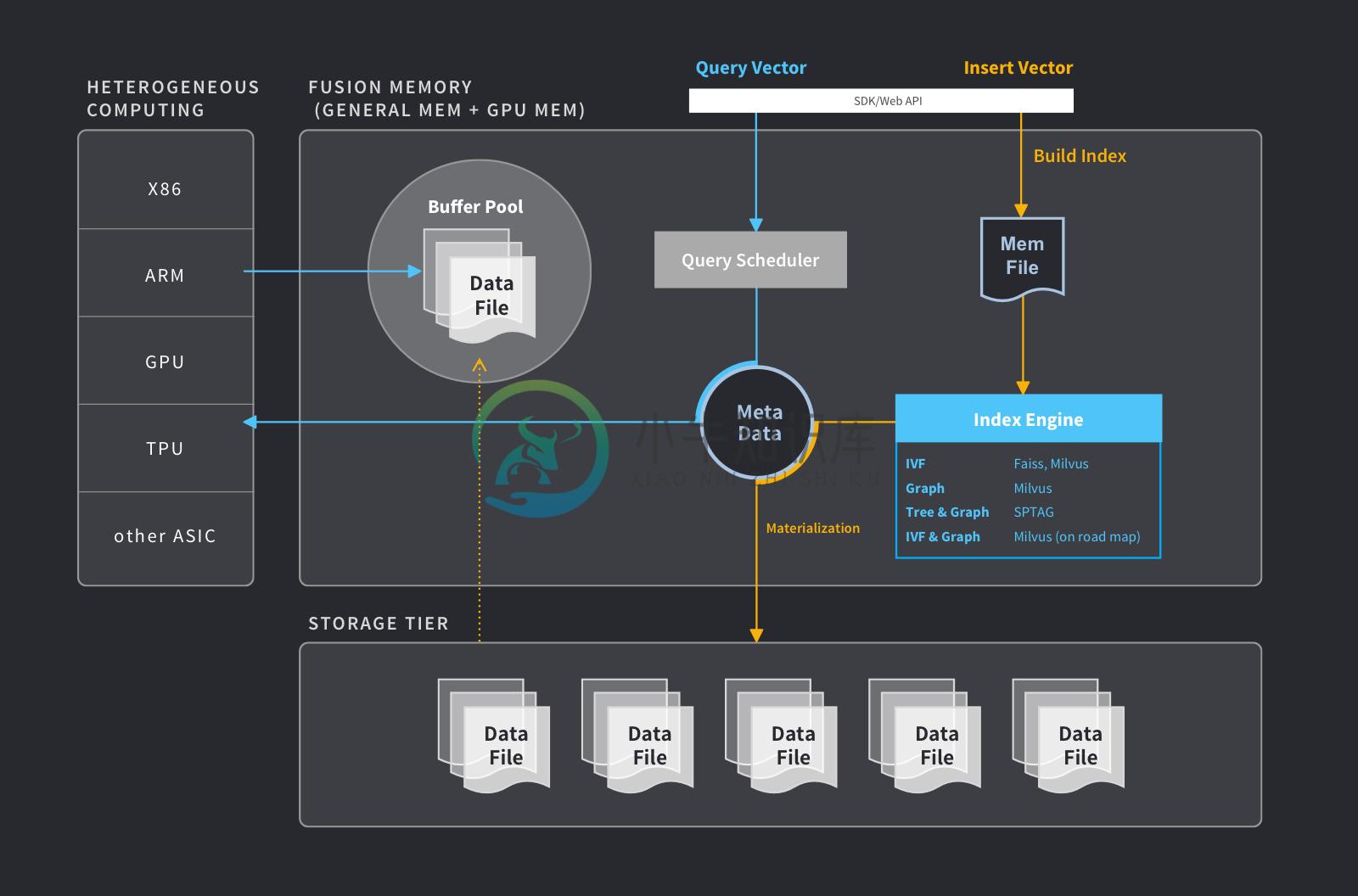
Milvus 是一个开源的分布式向量数据库。Milvus 数据库不但集成了业界成熟的向量相似度搜索技术,更在此基础上对高性能计算框架进行了大幅度优化。Milvus 为 AI 应用开发者带来了如下价值:
高性能
Milvus 数据库为海量向量搜索场景而设计。Milvus 不但集成了业界成熟的向量搜索技术如 Faiss 和 SPTAG,Milvus 也实现了高效的 NSG 图索引。同时,Milvus 团队针对 Faiss IVF 索引进行了深度优化,实现了 CPU 与多 GPU 的融合计算,大幅提高了向量搜索性能。Milvus 数据库可以在单机环境下完成 SIFT1b 十亿级向量搜索任务。
更多信息请参考 GitHub 文档:https://github.com/milvus-io/bootcamp/blob/master/docs/milvus101/hardware_platform.md
智能索引
针对不同应用场景,Milvus 数据库提供多种向量相似度计算方式和索引类型。Milvus 数据库目前支持主流的欧式距离、点积、余弦相似度(未来 Milvus 数据库会集成更多的相似度计算方式)。同时,Milvus 数据库提供适用于 n:N 查询的量化索引,适用于 1:N 查询的图索引或树图混合索引。
Milvus 索引类型:
- IVF:Faiss IVF(CPU计算,或GPU计算),Milvus 深度优化的IVF(CPU/GPU混合计算)
- Graph:Milvus 数据库实现的 NSG 索引
- Tree & Graph:集成微软 SPTAG
- IVF & Graph:Milvus 实现中
易于开发
Milvus 数据库为用户提供向量数据管理服务,以及集成的应用开发 SDK(Java/Python/C++/RESTful API)。相比直接调用 Faiss 和 SPTAG 那样的程序库,Milvus 数据库上的应用开发更便捷,数据管理更简单。
计算成本可控
Milvus 数据库不仅提供传统的 CPU 计算方案,通过引入 GPU 等高算力 ASIC,Milvus 数据库可以有效降低大规模向量搜索所需的硬件规模,从而降低系统的成本。
应用场景广泛
Milvus 向量数据库可以对接包括图片识别,视频处理,声音识别,自然语言处理等深度学习模型。为向量化后的非结构数据提供搜索分析服务。
欢迎加入Milvus社区
- 主页: milvus.io
- Github:github.com/milvus-io/milvus
- 知乎: zhuanlan.zhihu.com/milvus
- Slack: milvusio.slack.com
- Twitter:twitter.com/milvusio
- Facebook:www.facebook.com/io.milvus.5
-
Milvus安装 安装Docker 官网安装 在Docker中安装Milvus 在 Ubuntu/CentOS 上安装 Milvus 第一步 确认 Docker 状态 确认 Docker daemon 正在运行: $ docker info 如果无法正常打印 Docker 相关信息,请启动 Docker daemon. 提示:在 Linux 上,Docker 命令前面需加 sudo。若要在没有
-
一、手写动态链接 Milvus 代码库分为了 C++ 和 Go 两个部分,Go 部分负责系统主体架构、分布式系统、存储/查询链路等,C++ 部分负责查询、索引引擎专注于单机场景下的高性能,两者之间通过 cgo 接口调用。 为了维护两种语言的代码,就需要加入两种语言的生态。Go 作为一个年轻、现代的语言,开箱自带包管理、自动化测试框架和丰富的标准库;而经典的 C++ 就走向了另一个极端,虽然有极致的
-
一、简介 文档地址 1. Milvus介绍 Milvus 于 2019 年开源,主要用于存储、索引和管理通过深度神经网络和机器学习模型产生的海量向量数据。 Milvus 向量数据库专为向量查询与检索设计,能够为万亿级向量数据建立索引。与传统关系型数据库不同,Milvus 主要用于自下而上地处理非结构化数据向量。非结构化数据没有统一的预定义模型,因此可以转化为向量。 随着互联网不断发展,电子邮件、论
-
我有以下格式的数据。向量的第一个元素指的是标题,向量的第二个到底部指的是针对标题的值。我希望以表格/结构化格式(或带有标题和值的数据框)放置数据。
-
本文向大家介绍Node.js下向MySQL数据库插入批量数据的方法,包括了Node.js下向MySQL数据库插入批量数据的方法的使用技巧和注意事项,需要的朋友参考一下 项目(nodejs)中需要一次性插入多笔数据到数据库,数据库是mysql的,由于循环插入的性能太差,就像使用批量插入的方法提高数据的插入性能。 批量插入的数据库的表结构如下: 1.数据库连接 将插入数据转换成嵌套数组 例如要插入的两
-
所以我有这个方法: 数据库返回null,并将设置为null。 什么是我可以100%避免NPE的万无一失的方法?我知道从这里可以看出,tocasting不是一个保证 更新:在代码中,NPE被抛出。。。这对我来说毫无意义。我预计NPE会被抛出
-
有没有办法将数据帧转换为向量?例如 预期产出
-
前面两节课讲解到了顶点位置坐标数据、顶点颜色数据,这节课讲解第三种顶点数据:顶点法向量。 如果你有初高中物理的光学基础,应该会有漫反射、镜面反射的概念。比如太阳光照在一个物体表面,物体表面与光线夹角位置不同的区域明暗程度不同,WebGL中为了计算光线与物体表面入射角,你首先要计算物体表面每个位置的法线方向,在Threejs中表示物体的网格模型Mesh的曲面是由一个一个三角形构成,所以为了表示物体表
-
我创建了一个向MySql数据库插入数百万个值的程序。我读到过有关批插入的文章,它将优化我的程序并使其更快,但当我尝试这样做时,它以同样的方式工作。我没有将每个值插入数据库,而是每次将500个值保存在一个列表中,然后将它们插入一个大循环中,如下所示: 然后我删除列表中的所有值,并再次开始收集500个值。它不应该工作得更好吗? 我的插入代码是: 我有一些问题: 1。为什么当我批量插入时它不能更快地工作