
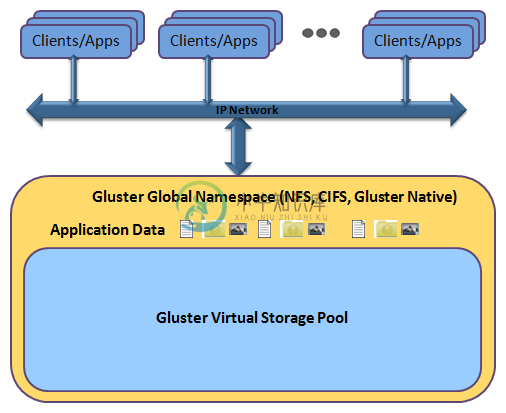
Gluster 是一个集群的文件系统,支持 PB 级的数据量。GlusterFS 通过 RDMA 和 TCP/IP 方式将分布到不同服务器上的存储空间汇集成一个大的网络并行文件系统。
-
glusterfs是一个大尺度的文件系统,分布部署在多个服务器上,实现文件的复制,存在和备份功能 1、Glusterfs安装 安装glusterfs需要至少两个节点 101.35.241.220 VM-4-8-centos 150.158.153.179 VM-4-16-centos 42.194.147.234 VM-8-15-centos 安装glusterfs(每一个节点) # 在每一个节点
-
前言 Glusterfs的安装可以在虚拟机上安装也可以在K8S以DS形式安装。本文讲解在虚拟机上安装实践。 分布式存储系统 k8s的数据卷是docker数据卷的扩展,K8S适配各种存储系统,包括本地存储EmptyDir,HostPath,网络存储NFS,GlusterFS,PV/PVC 分布式存储是一种数据存储技术,通过网络使用企业中的每台机器上的磁盘空间,并将这些分散的存储资源构成一个虚拟的存储
-
公共调优选项(以gluster 3.4为例) 下面的选项都可以通过如下命令进行设置。 gluster volume set VOLUME KEY VALUE 关键词 说明 备注 nfs.disable "on":关闭NFS服务 在当前无需求,建议关闭NFS服务 auth.allow auth.reject 指定可访问的客户端IP 指定拒绝访问的客户端IP cluster.min-free-di
-
CentOS 7 离线安装GlusterFS 7.9.1 环境 系统ip 主机名 添加磁盘并格式化 每个磁盘挂载点 192.168.32.128 servera /dev/sdb1 /brick/brick 192.168.32.132 serverb /dev/sdb1 /brick/brick 每台机器中均添加 192.168.32.128 servera 192.168.32.132 ser
-
一、快速部署GlusterFS 1.前期环境的准备 因为做实验我用的是VMware ,最少准备3台虚拟机,2台用来做服务端,1台用来做客户端,服务端的配置(1C2G,硬盘最少2块),客户端(1C2G)本人用自己的机子,大家可以按照自己的实际情况来配置。 首先我把两台服务端的虚拟机的主机名改成了node1,node2 接下来配hosts文件主机名会好记点。 node1信息 [root@node1 ~
-
Glusterfs介绍 GlusterFS是Scale-Out存储解决方案Gluster的核心,它是一个开源的分布式文件系统,具有强大的横向扩展能力,通过扩展能够支持数PB存储容量和处理数千客户端。GlusterFS借助TCP/IP或InfiniBand RDMA网络将物理分布的存储资源聚集在一起,使用单一全局命名空间来管理数据。GlusterFS基于可堆叠的用户空间设计,可为各种不同的数据负载提
-
最近在学习分布式存储,用到了开源工具GlusterFS,就写点东西吧。 新手上路,多多指教- 常见术语 Xlator=translator:glusterfs 模块的代名词 Brick :存储目录是Glusterfs的基本存储单元,由可信存储池中服务器上对外 输出的目录表示。存储目录的格式由服务器和目录的绝对路径构成,具体如下: SERVER:EXPORT.例如:myhostname:/expor
-
glusterfs源码分析,视频讲解,持续更新中... glusterfs源码分析-程林_哔哩哔哩_bilibili
-
1 安装相关软件 1) 安装服务 yum install -y glusterfs glusterfs-server glusterfs-fuse glusterfs-rdma 2) 启动服务 systemctl start glusterd.service systemctl enable glusterd.service 2 GlusterFS配置 在其中一台机器把其余所有机器添加到信任池 g
-
当两个或多个记录存储在同一文件中时,它称为群集。 这些文件在同一数据块中有两个或多个表,并且用于将这些表映射到一起的键属性仅存储一次。 该方法降低了在不同文件中搜索各种记录的成本。 当经常需要以相同条件连接表时,将使用群集文件组织。这些连接只会从两个表中提供几条记录。 在给定的示例中,仅检索指定部门的记录。此方法不能用于检索整个部门的记录。 在这种方法中,可以直接插入,更新或删除任何记录。 数据根
-
有关Kafka群集体系结构,请看下面的结构图。 它显示了Kafka的集群图。 下表描述了上图中显示的每个组件。 Broker - Kafka集群通常由多个代理组成,以保持负载平衡。 Kafka经纪人是无状态的,所以他们使用ZooKeeper维护他们的集群状态。 一个Kafka代理实例可以处理每秒数十万次的读写操作,每个Broker都可以处理TB消息,而不会影响性能。 Kafka经纪人的领导人选举可
-
我们复用 kubernetes 的三台主机做 glusterfs 存储。 安装 glusterfs 我们直接在物理机上使用 yum 安装,如果你选择在 kubernetes 上安装,请参考:https://github.com/gluster/gluster-kubernetes/blob/master/docs/setup-guide.md # 先安装 gluster 源 $ yum insta
-
GlusterFS是Scale-Out存储解决方案Gluster的核心,它是一个开源的分布式文件系统,具有强大的横向扩展能力,通过扩展能够支持数PB存储容量和处理数千客户端。GlusterFS借助TCP/IP或InfiniBand RDMA网络将物理分布的存储资源聚集在一起,使用单一全局命名空间来管理数据。GlusterFS基于可堆叠的用户空间设计,可为各种不同的数据负载提供优异的性能。
-
我在Kubernetes(GKE和kubeadm)上启动了MongoDB副本集。我没有遇到任何问题的豆荚进入储藏室。然而,当我使用Helm部署相同时,我面临这个问题。当我运行此命令时-( kubectl Description po Mongodb-Shard1-0--namespace=Kube-System) (这里,mongodb-shard1-0是创建的第一个也是唯一一个pod(在所需的三
-
设置:GlusterFS在k8s(AKS)集群上; glusterfs使用gk-deploy部署时存在的问题;下面分享了一些错误片段,请建议解决方案,以使我的部署进行-提前感谢。 获取相同错误:事件:来自消息的类型原因年龄-----------------------------------------------------------------------------------------