
由前Facebook工程师创办的MemSQL,号称世界上最快的分布式关系型数据库,兼容MySQL但快30倍,能实现每秒150万次事务。原理是仅用内存并将SQL预编译为C++。
MemSQL 提供免费的开发者版本(数据限制32G)和全功能试用版本(试用期30天)
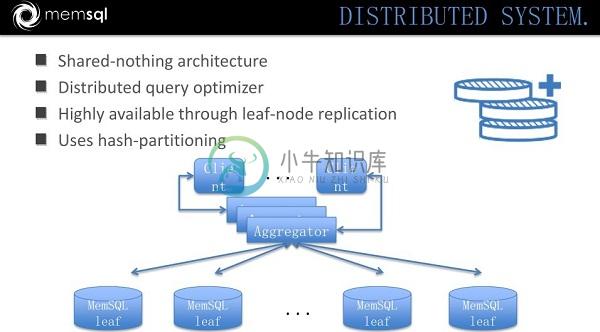
MemSQL 架构:
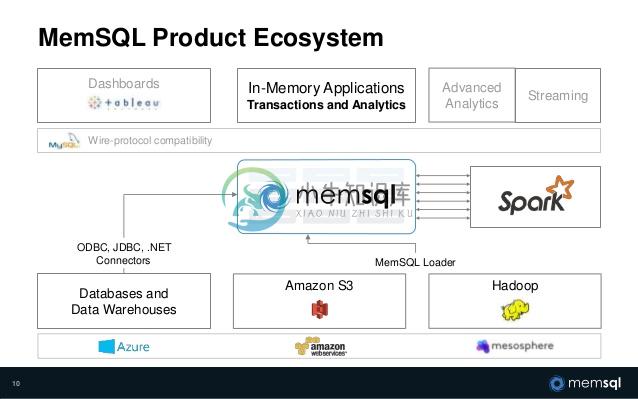
MemSQL 生态系统:
-
一. 查看memsql的分区 SHOW PARTITIONS; 二. 指数匹配(查询特性 ) CREATE TABLE a ( a1 int, a2 int, a3 int, SHARD KEY (a1, a2), KEY (a3) ); 匹配碎片键: 1. 这些查询将发送到一个分区 SELECT * FROM a WHERE a1 = 4 AND a2 = 10; SELECT a3, coun
-
1、Aggregators(汇聚器) MemSQL集群的一种节点,为访问MemSQL集群的网关,一个集群中可以有多个汇聚器,汇聚器主要负责向叶子节点发送DML请求、汇聚操作结果并返回给客户端 2、Master Aggregator(主汇聚器) 1、Aggregators(汇聚器) MemSQL集群的一种节点,为访问MemSQL集群的网关,一个集群中可以有多个汇聚器,汇聚器主要负责向叶子节点发送D
-
http://www.gxlcms.com/ -- 多主-从 http://www.gxlcms.com/ http://www.gxlcms.com/ 前facebook员工和前微软sql server工程师联合搞的一个分布式关系数据库 全部内存运行,将sql转化成速度更快的c++, 原理类似HipHop 有mysql api, 完全兼容mysql,没有学习使用成本 速度是mysql的30倍,每
-
mysqldump是MySQL客户端最常用的数据备份工具之一,它会生成一些列创建表和插入数据的SQL语句,因此用来恢复一个是最方便的。 当你确定要将数据迁移到MemSQL之前,有几个注意事项: 大多数MySQL存储引擎都是使用 B-tree来存储索引的,而 MemSQL是使用单向无锁的 skip 列表或者无锁的哈希表。选择正确的索引数据结构对应用程序的性能会有显著的提升。其中哈希表主要适合 key
-
2、配置测试环境 创建一个用户,方便后续使用: MemSQL> grant all on *.* to jss identified by "jss" with grant option; Query OK, 1 row affected (0.03 sec) 本来是可选的with grant option选项在MemSQL中是必选项。另外注意password在当前的MemSQL版本中没什么用
-
MemSQL使用一种叫做"code generation"的方法,将SQL语句编译成C++并缓存起来,这样下次执行就很快了,号称执行效率比传统的基于磁盘的关系型软件要快30倍。 前 Facebook 前工程师 EricFrenkiel 和 NikitaShamgunov创办了 MemSQL,对外宣称比MySQL快30倍。 现在Facebook的 MySQL工程师Domas Mituzas 出来说话
-
1、将DNS注释掉,强制本地安装 vi /etc/resolv.conf 注释掉nameserver 2、安装memsql-ops # tar -zxvf memsql-ops-6.0.7.tar.gz # ./install.sh --ops-datadir /opt/memdata --memsql-installs-dir /opt/meminstall 3、在其他节点安装memsql-a
-
本周数据库业界探讨最火热的话题就是MemSQL,究竟是不是“旧瓶装新酒”引发了诸多的辩论,同时也引发了究竟是产品技术重要还是DBA重要的疑问。网络中有一些关于MemSQL的介绍,基本上都是来自官方文档。在本文中,数据库行业的著名独立分析师Curt Monash也发表了他对MemSQL的看法。 MemSQL到底是什么? 内存关系型数据库 QL-92的子集 兼容MySQL(SQL覆盖问题除外) Mem
-
我需要首先指出,我绝不是一个数据库专家.我知道如何使用几种需要数据库后端的语言来编程应用程序,并且相对熟悉MySQL,Microsoft SQL Server和现在的MEMSQL – 但同样,不是数据库方面的专家,所以非常感谢您的输入. 我一直在开发一个必须交叉引用几个不同表的应用程序.我最近遇到的一个非常简单的问题是,我必须: >每天将600K到1M的记录下拉到临时表中. >比较这个新数据拉和旧
-
来自MemSQL的Mark L在这里.我想解决您的一些问题,并提供其他帮助来获取您要询问的信息/基准. MemSQL确实通过JDBC连接器支持链接表(实际上,该连接器的工作方式与MySQL一样),因此使它正常工作不会有任何问题.在分布式模式下运行MemSQL确实会提供很大的性能优势,您将在吞吐量和延迟方面看到全面的改进.我没有直接在H2和MemSQL之间找到直接比较-但是,您可以通过查看MemSQ
-
一种是关系数据库,典型代表产品:DB2; 另一种则是层次数据库,代表产品:IMS层次数据库。 非关系型数据库有MongoDB、memcachedb、Redis等。
-
每当我读到有关NoSQL分布式数据库的内容时,他们都会提到CAP定理,这意味着在分区系统中,您可以具有完全一致性,完全可用性或两者兼而有之,但不能完全两者兼而有之。 我不太清楚他们在谈论什么类型的一致性: 是数据新鲜度的一致性,其中一些客户端可能会获得比其他客户端更旧的数据吗? 或者是一致性,即事务可能仅部分完成,这可能会使数据处于不一致的状态? 第二种解释对我来说听起来很危险,不能真正接受。第一
-
关系数据库,是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。现实世界中的各种实体以及实体之间的各种联系均用关系模型来表示。关系模型由关系数据结构、关系操作集合、关系完整性约束三部分组成。
-
分布式支持 数据访问层支持分布式数据库,包括读写分离,要启用分布式数据库,需要开启数据库配置文件中的deploy参数: return [ // 启用分布式数据库 'deploy' => 1, // 数据库类型 'type' => 'mysql', // 服务器地址 'hostname' => '192.168.1.1,19
-
本文向大家介绍Hive与关系型数据库的关系?相关面试题,主要包含被问及Hive与关系型数据库的关系?时的应答技巧和注意事项,需要的朋友参考一下 没有关系,hive是数据仓库,不能和数据库一样进行实时的CURD操作。 是一次写入多次读取的操作,可以看成是ETL工具。
-
主要内容:数据定义,数据操作,数据控制就其布局和导航方面而言,Microsoft Access具有其他Microsoft Office产品的外观和感觉,但MS Access是一个数据库,更具体地说是一个关系数据库。 在MS Access 2007之前,文件扩展名是,但是在MS Access 2007中,扩展名已经更改为扩展名。 早期版本的Access无法读取accdb扩展,但MS Access 2007及更高版本可以读取和更改早期版本
-
Discovering models from relational databases(关系型数据库连接) 简介 基础步骤 discovery 案例 添加 discovery 方法 简介 Loopback可以很方便地从现有的关系型数据库创建model, 这个过程被称为 discovery ,由以下连接器的支持. MySQL 连接器 PostgreSQL 连接器 Oracle 连接器 SQL Se
-
本文向大家介绍关系数据模型,包括了关系数据模型的使用技巧和注意事项,需要的朋友参考一下 关系数据模型是最著名的数据模型,全世界大多数人都在使用它,它是一种简单而有效的数据模型,并具有以最佳方式处理数据的能力。 表用于处理关系数据模型中的数据。包含有关公司员工数据的表格示例如下- <员工> Emp_Number Emp_Name Emp_Designation Emp_Age Emp_Salary