
SeimiCrawler 是一个敏捷的、独立部署的、支持分布式的 Java 爬虫框架,希望能在最大程度上降低新手开发一个可用性高且性能不差的爬虫系统的门槛,以及提升开发爬虫系统的开发效率。在 SeimiCrawler 的世界里,绝大多数人只需关心去写抓取的业务逻辑就够了,其余的 Seimi 帮你搞定。设计思想上 SeimiCrawler 受 Python 的爬虫框架 Scrapy 启发,同时融合了 Java 语言本身特点与 Spring 的特性,并希望在国内更方便且普遍的使用更有效率的 XPath 解析 HTML,所以 SeimiCrawler 默认的 HTML 解析器是 JsoupXpath (独立扩展项目,非 jsoup 自带),默认解析提取 HTML 数据工作均使用 XPath 来完成(当然,数据处理亦可以自行选择其他解析器)。并结合 SeimiAgent 彻底完美解决复杂动态页面渲染抓取问题。V2.0 版本开始无缝支持 SpringBoot。
原理示例
基本原理
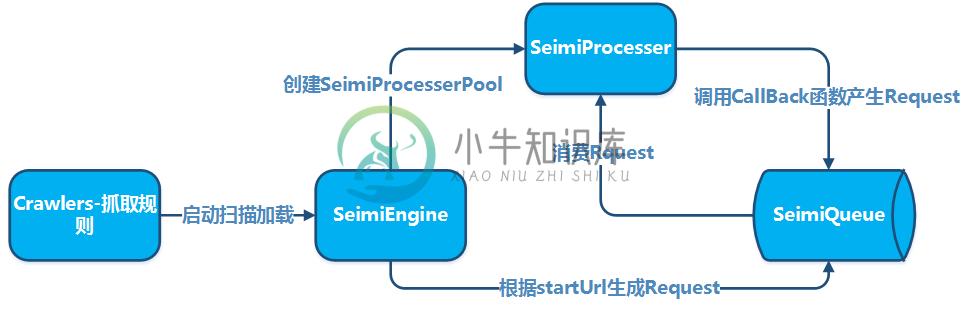
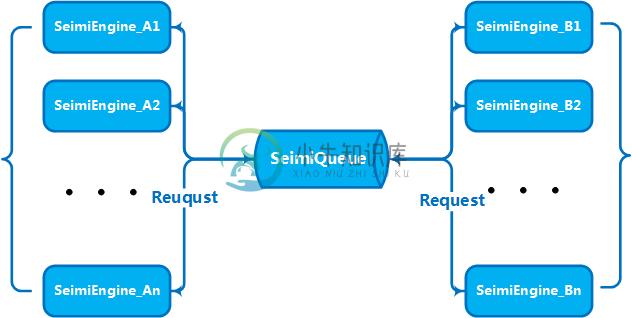
集群原理
快速开始
添加 maven 依赖 (已经同步到中央 maven 库,最新版本参见项目主页):
cn.wanghaomiao
SeimiCrawler
x.x.x
在包 crawlers 下添加爬虫规则,例如:
@Crawler(name = "basic")
public class Basic extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
return new String[]{"http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s:urls){
push(new Request(s.toString(),Basic::getTitle));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void getTitle(Response response){
JXDocument doc = response.document();
try {
logger.info("url:{} {}", response.getUrl(), doc.sel("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()"));
//do something
} catch (Exception e) {
e.printStackTrace();
}
}
}
然后随便某个包下添加启动 Main 函数,启动 SeimiCrawler:
public class Boot {
public static void main(String[] args){
Seimi s = new Seimi();
s.start("basic");
}
}
以上便是一个最简单的爬虫系统开发流程。
更多文档
目前可以参考 demo 工程中的样例,基本包含了主要的特性用法。更为细致的文档移步 SeimiCrawler 主页 中进一步查看。
-
最近在扒一些数据,原本使用jsoup,但是发觉这个框架爬取的效率不高,用起来也不是很方便,了解了一些爬虫框架之后,决定使用SeimiCrawler来爬取数据。 开发环境:ideal+mybatis+SeimiCrawler 环境配置,具体的不解释,做过Java开发的明白,直接上配置文件:注意:SeimiCrawler相关的配置必须以seimi开头; 全局配置:seimi.xml <?xml ver
-
本文将介绍如何使用SeimiCrawler将页面中信息提取为结构化数据并存储到数据库中,这也是大家非常常见的使用场景。数据抓取将以抓取博客园的博客为例。 建立基本数据结构 为了演示,简单起见只建立一个用来存储博客标题和内容两个主要信息的表即可。表如下: CREATE TABLE `blog` ( `id` int(11) NOT NULL AUTO_INCREMENT, `title` varch
-
SeimiCrawler2.0 https://blog.csdn.net/zhegexiaohuozi/article/details/80809922 demo:https://github.com/zhegexiaohuozi/SeimiCrawler/tree/master/spring-boot-example
-
变更日志 v1.2.0 OkhttpDownloader支持处理contentType头中没有指定编码的中文页面 支持通过@Crawler注解中的httpTimeOut属性自定义http请求的超时时间,默认15000ms v1.1.0 可通过实现SeimiCrawler的List<Request> startRequests();来实现更复杂的起始触发请求 SemiQueue实现按需加载 修复抓取
-
Java分布式爬虫seimicrawler: https://blog.csdn.net/z2464342708m/article/details/80689030
-
变更日志 v1.0.0 http请求处理器重构,并默认改由okhttp3实现,且支持通过@Crawler注解中的httpType自由切换为apache httpclient 部分代码优化 支持通过seimiAgent获取页面快照(png/pdf) 简介 SeimiCrawler是一个敏捷的,独立部署的,支持分布式的Java爬虫框架,希望能在最大程度上降低新手开发一个可用性高且性能不差的爬虫系统的门
-
Change log v0.3.0 内置支持SeimiAgent,完美解决动态页面渲染抓取问题 修复自动跳转在某些情况存在的bug 简介 SeimiCrawler是一个敏捷的,独立部署的,支持分布式的Java爬虫框架,希望能在最大程度上降低新手开发一个可用性高且性能不差的爬虫系统的门槛,以及提升开发爬虫系统的开发效率。在SeimiCrawler的世界里,绝大多数人只需关心去写抓取的业务逻辑就够了,
-
Change log v0.2.7 内嵌http接口在可以接收单个Json形式Request基础上增加支持接收Json数组形式的多个Request Request对象支持设置skipDuplicateFilter用来告诉seimi处理器跳过去重机制,默认不跳过 增加定时调度使用Demo 回调函数通过Request传递自定义参数值类型由Object改为String,方便明确处理 Fix:修复一个打日
-
主要内容:Scrapy下载安装,创建Scrapy爬虫项目,Scrapy爬虫工作流程,settings配置文件Scrapy 是一个基于 Twisted 实现的异步处理爬虫框架,该框架使用纯 Python 语言编写。Scrapy 框架应用广泛,常用于数据采集、网络监测,以及自动化测试等。 提示:Twisted 是一个基于事件驱动的网络引擎框架,同样采用 Python 实现。 Scrapy下载安装 Scrapy 支持常见的主流平台,比如 Linux、Mac、Windows 等,因此你可以很方便的安装它
-
有的时候,当我们的爬虫程序完成了,并且在本地测试也没有问题,爬取了一段时间之后突然就发现报错无法抓取页面内容了。这个时候,我们很有可能是遇到了网站的反爬虫拦截。 我们知道,网站一方面想要爬虫爬取网站,比如让搜索引擎爬虫去爬取网站的内容,来增加网站的搜索排名。另一方面,由于网站的服务器资源有限,过多的非真实的用户对网站的大量访问,会增加运营成本和服务器负担。 因此,有些网站会设置一些反爬虫的措施。我
-
这一章将会介绍使用一些新的模块(optparse,spider)去完成一个爬虫的web应用。爬虫其实就是一个枚举出一个网站上面的所有链接,以帮助你创建一个网站地图的web应用程序。而使用Python则可以很快的帮助你开发出一个爬虫脚本. 你可以创建一个爬虫脚本通过href标签对请求的响应内容进行解析,并且可以在解析的同时创建一个新的请求,你还可以直接调用spider模块来实现,这样就不需要自己去写
-
WebMagic是我业余开发的一款简单灵活的爬虫框架。基于它你可以很容易的编写一个爬虫。 这本小书以WebMagic入手,一方面讲解WebMagic的使用方式,另一方面讲解爬虫开发的一些惯用方案。
-
根据使用场景,网络爬虫可分为 通用爬虫 和 聚焦爬虫 两种. 通用爬虫 通用网络爬虫 就是 捜索引擎抓取系统,目的是将互联网上的所有的网页下载到本地,形成一个互联网内容的镜像备份。 它决定着整个搜索引擎内容的丰富性和时效性,因此它的性能优劣直接影响着搜索引擎的效果。 通用搜索引擎(Search Engine)工作原理 第一步:抓取网页 搜索引擎网络爬虫的基本工作流程如下: 首先选取一部分的初始UR
-
本文向大家介绍python爬虫框架talonspider简单介绍,包括了python爬虫框架talonspider简单介绍的使用技巧和注意事项,需要的朋友参考一下 1.为什么写这个? 一些简单的页面,无需用比较大的框架来进行爬取,自己纯手写又比较麻烦 因此针对这个需求写了talonspider: •1.针对单页面的item提取 - 具体介绍点这里 •2.spider模块 - 具体介绍点这里 2.介
-
爬虫项是什么呢?比如采集文章列表、文章详情页,他们都是不同的采集项。 定义示例: 继承Yurun\Crawler\Module\Crawler\Contract\BaseCrawlerItem类。 <?php namespace Yurun\CrawlerApp\Module\YurunBlog\Article; use Imi\Bean\Annotation\Bean; use Yurun\C
-
拼多多爬虫工程师面试题 电话面: http协议、tcp协议(几次握手) top命令 Linux/Mac 下虚拟内存(Swap) 线程、进程、协程 Async 相关、事件驱动相关 阻塞、非阻塞 Python GIL 布隆过滤器原理:如何实现、一般要几次哈希函数 给我留下了一个作业:抓取天猫超市上某些商品的可以配送省份信息。(当时做这个也花了很久,主要是需要解决PC端的登陆问题,后来通过h5接口) 现