
-
RocksDB是FaceBook起初作为实验性质开发的,旨在充分实现快存上存储数据的服务能力。由Facebook的Dhruba Borthakur于2012年4月创建的LevelDB的分支,最初的目标是提高服务工作负载的性能,最大限度的发挥闪存和RAM的高度率读写性能。 Key和value是任意大小的字节流支持原子的读和写。除此外,RocksDB深度支持各种配置,可以在不同的生产环境(纯内存、Fl
-
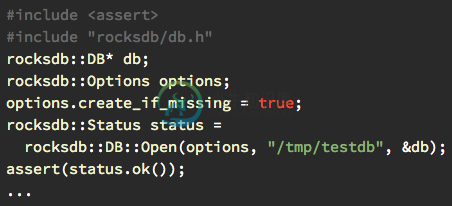
基本操作 该库提供持久性键值存储。键和值是任意字节数组。键根据用户指定的比较器功能在键值存储中排序。rocksdb 打开数据库 数据库具有与文件系统目录相对应的名称。数据库的所有内容都存储在此目录中。下面的示例演示如何打开数据库,并在必要时创建数据库:rocksdb #include <cassert> #include "rocksdb/db.h" rocksdb::DB* db;
-
(Owed by: 春夜喜雨 http://blog.csdn.net/chunyexiyu) 翻译来源:https://github.com/facebook/rocksdb 翻译来源:https://github.com/facebook/rocksdb/wiki RocksDB:一个持久化到闪存和磁盘等存储器的键值存储数据库 RocksDB是被facebook数据库引擎团队开发出来并维护着。
-
RocksDB是使用C ++编写的嵌入式kv存储引擎,其键值均允许使用二进制流。由Facebook基于levelDB开发,提供向后兼容的levelDB API。 RocksDB针对Flash存储进行优化,延迟极小.RocksDB使用LSM存储引擎,纯C ++编写.Java版本RocksJava正在开发中。参见RocksJavaBasic。 RocksDB依靠大量灵活的配置,使之能针对不同的生产环境
-
标签: rocksdb是在leveldb的基础上优化而得,解决了leveldb的一些问题。 主要的优化点 1.增加了column family,这样有利于多个不相关的数据集存储在同一个db中,因为不同column family的数据是存储在不同的sst和memtable中,所以一定程度上起到了隔离的作用。 2.采用了多线程同时进行compaction的方法,优化了compact的速度。 3.增加了
-
RocksDB中文网 | 一个持久型的key-value存储 高度分层架构 RocksDB是一种可以存储任意二进制kv数据的嵌入式存储。RocksDB按顺序组织所有数据,他们的通用操作是Get(key), Put(key), Delete(Key)以及NewIterator() RocksDB有三种基本的数据结构:mentable,sstfile以及logfile。mentable是一种内存数据结
-
WAL Learning Write Ahead Log Overview 在RocksDB中每一次数据的更新都会涉及到两个结构,一个是内存中的memtable(后续会刷新到磁盘成为SST),第二个是WAL(WriteAheadLog)。在默认情况下,RocksDB通过在每次用户写时调用flush (刷盘)WAL文件来保持一致性。 WAL主要的功能是当RocksDB异常退出后,能够恢复出错前的内存
-
compaction主要包括两类:将内存中imutable 转储到磁盘上sst的过程称之为flush或者minor compaction;磁盘上的sst文件从低层向高层转储的过程称之为compaction或者是major compaction。对于myrocks来说,compaction过程都由后台线程触发,对于minor compaction和major compaction分别对应一组线程,通
-
三、持久化流程 MemTable 的持久化 参考 https://developer.aliyun.com/article/643754#comment 分析 RocksDB 合适以及如何 Flush 内存数据(MemTable)到 SST的。在 RocksDB 中,每一个 column family 都有自己的 MemTable,当它超过固定大小时,会被设置为 immutable 然后会有后台线
-
1 介绍 使用YCSB测试rocksdb(自己修改的代码)的性能,运行环境: 操作系统:ubuntu 14.04 rocksdb的版本:5.18.3 YCSB的版本:0.15.0 2 rocksdb的jni包生成 2.1 rocksdb的版本代码 通过github获取rocksdb版本5.18.3的代码作为基础: > git clone https://github.com/facebook/ro
-
谢了。
-
简介 Lumen 有很棒的文件系统抽象层,是基于 Frank de Jonge 的 Flysystem 扩展包。 Lumen 集成的 Flysystem 提供了简单的接口,可以操作本地端空间、 Amazon S3 、 Rackspace Cloud Storage 。更好的是,它可以非常简单的切换不同保存方式,但仍使用相同的 API 操作! 配置文件 文件系统的配置文件放在 config/file
-
问题内容: 在做的选择谷歌浏览器,在那里我的文件系统做文件获取写的?在构建和调试此应用时,我想将文件放到那里并让Chrome与它们交互。 问题答案: 对我来说,至少在Mac OSX上,它们对于我来说存储在下面。如果您使用的是个人资料,则会有而不是的个人资料目录。但是,每个来源的已保存文件/文件夹都被混淆在您难以与之交互的目录下。 要调试Filesystem API,您可以选择以下几种方法: 使用此
-
本文向大家介绍Django文件存储 自己定制存储系统解析,包括了Django文件存储 自己定制存储系统解析的使用技巧和注意事项,需要的朋友参考一下 要自己写一个存储系统,可以依照以下步骤: 1.写一个继承自django.core.files.storage.Storage的子类。 2.Django必须可以在无任何参数的情况下实例化MyStorage,所以任何环境设置必须来自django.conf.
-
一、介绍 HDFS (Hadoop Distributed File System)是 Hadoop 下的分布式文件系统,具有高容错、高吞吐量等特性,可以部署在低成本的硬件上。 二、HDFS 设计原理 2.1 HDFS 架构 HDFS 遵循主/从架构,由单个 NameNode(NN) 和多个 DataNode(DN) 组成: NameNode : 负责执行有关 文件系统命名空间 的操作,例如打开,
-
FILESYSTEM AND STORAGE DEVICE MANAGEMENT 如果您来自 Windows 环境,那么 Linux 表示和管理存储设备的方式在您看来将非常不同。您已经看到,文件系统没有驱动器的物理表示形式,就像 Windows 中的 C:、D:或 E:系统一样,而是有一个文件树结构,其顶部或根目录是/。本章将介绍 Linux 如何表示存储设备,如硬盘驱动器、闪存驱动器和其他存储设
-
我试图理解哪些系统变量具有这个值。我执行这段代码并得到some_string。 inetAddress.getLocalHost().getCanonicalHostName(); 在此之后,我将打印所有系统环境 system.getEnv().foreach((k,v)->system.out.println(“k=”+k+“v=”+v)); 我找到所有具有some_string变量,并将所有值
-
问题内容: 我编写了一个简单的测试应用程序,以将某些内容记录到日志文件中。我正在使用 linux mint ,在应用程序执行后,我尝试使用以下命令查看日志: 但是文件消息既不经过测试也不存在。在下面可以找到我的代码。也许我做错了什么,文件没有存储在那儿,或者我需要启用Linux Mint中的登录功能。 问题答案: 在我的Ubuntu机器上,我可以在看到输出。 在RHEL / CentOS计算机上,