
RediSearch是一个高性能的全文搜索引擎,可作为一个Redis Module 运行在Redis上,是由RedisLabs团队开发的。

主要特性
RediSearch 是在Redis基础上从0开始开发的一个全文搜索索引,使用新的Redis Modules API来扩展Redis新命令和能力,它的主要特性包括:
简单,快速索引和搜索
数据存储在内存中,使用内存-有效的自定义数据结构
支持多种使用UTF-8编码的语言
文档和字段评分
结果的数值过滤
通过词干扩展查询
精确的短语搜索
按特定属性过滤结果(例如仅在标题中搜索“foo”)
强大的自动提示引擎
增量索引(不需要对索引进行优化和压缩)
支持用作存储在另一数据库中的文档的搜索索引
支持已经在Redis中存在的HASH对象作为文件的索引
扩展到多个Redis实例
性能
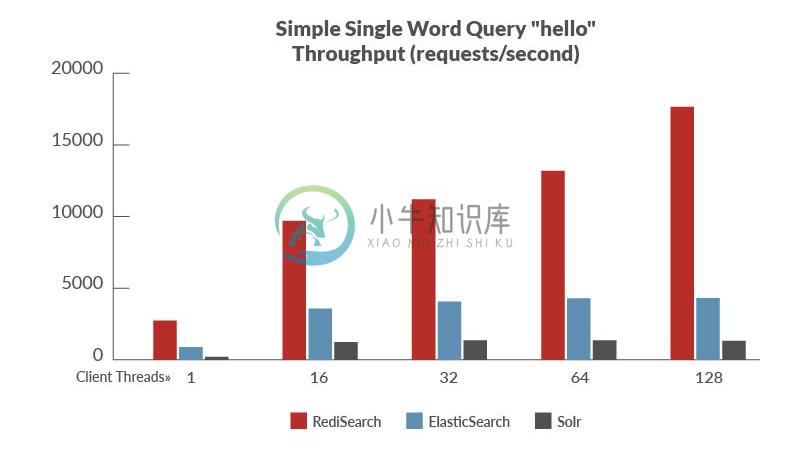
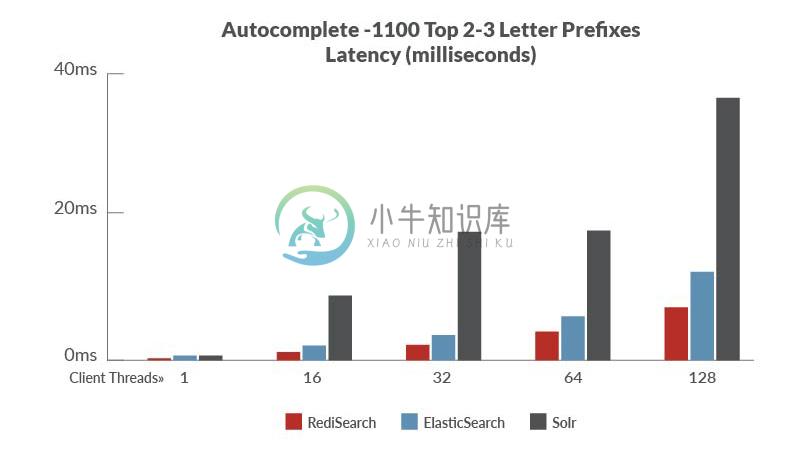
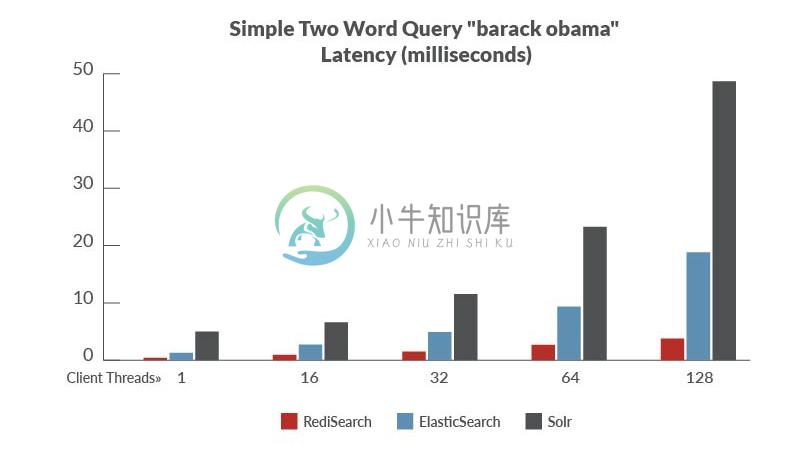
基准设置:
数据集:从维基百科页面提供的有用的英文摘要的转储,其中包括510万短摘要。
基准测试:我们针对不同的搜索引擎运行了几个具有不同配置文件的查询。并行的运行1, 8, 16、32和64个并发客户端执行每个查询。我们也跑了自动完成测试,从具有相同客户端并发配置文件的数据集中测试前1100名最受欢迎的2和3个字母前缀。
物理配置:2个 c4.4x large AWS EC2 Instance,每一个配置16核,32GB内存 和 SSD EBS 存储,一个用作client,另一个运行 servers
搜索引擎测试
RediSearch:5个分片运行在5个Redis Masters上,没有负载均衡,冗余或内置的缓存,此设置最多使用了Server机器的5个CPU核心。
ElasticSearch:一个实例有5个分片,过滤器缓存已禁用,在基准测试中,ElasticSearch使用了所有的16个CPU核心,因为它是多线程的。
Solr:solr-cloud的两个实例,每一个实例上面运行2个分片,缓存是完全禁用的,在基准测试过程中,Solr也是使用了所有的16个CPU核心。
-
RediSearch 介绍 原文文档 1、介绍 RediSearch is a Redis module that provides querying, secondary indexing, and full-text search for Redis. To use RediSearch, you first declare indexes on your Redis data. You ca
-
1,资料 github: https://github.com/RedisJSON/RedisJSON website: https://oss.redis.com/redisjson/ 社区:https://university.redis.com/#courses 2,介绍 RedisJSON是什么 RedisJSON是一个Redis模块,它实现了JSON数据交换标准ECMA-404,作为原
-
添加依赖 创建一个spring boot 应用 添加依赖 <dependency> <groupId>com.redislabs</groupId> <artifactId>spring-redisearch</artifactId> <version>3.0.1</version> </dep
-
下载PHP redisearch composer require macfja/redisearch 这个客户端支持redis扩展 ,predis等 GitHub - MacFJA/php-redisearch: PHP Client for RediSearch https://redis.io/commands/ft.create/ 我这里命令执行创建索引 ft.CREATE userId
-
安装库 pip install redis 函数方法使用 获取redis实例 import redis def getRedis(): url='192.168.20.3' port=6379 pool = redis.ConnectionPool(host=url, port=port, db=0) return redis.Redis(connection_p
-
12.7.1. 布尔全文搜索 12.7.2. 全文搜索带查询扩展 12.7.3. 全文停止字 12.7.4. 全文限定条件 12.7.5. 微调MySQL全文搜索 MATCH (col1,col2,...) AGAINST (expr [IN BOOLEAN MODE | WITH QUERY EXPANSION]) MySQL支持全文索引和搜索功能。MySQL中的全文索引类型FULLTEXT的索
-
回顾 在前面的章节(分页),我们已经加强了数据库查询,因此能够在页面上获取各种查询。 今天,我们会继续探讨数据库的话题,只是领域不同。所有存储内容的应用程序必须提供搜索能力。 许多其它类型的网站可能使用了谷歌、必应等索引所有的内容并且提供查询结果。这个对于大多数静态页面的网站,像论坛,是很好用。我们应用程序 microblog 的基本单元是用户短小的 blog,不是整个页面。我们希望搜索结果是动态
-
我有大量相同类型的实体,每个实体都有大量属性,并且我只有以下两种选择来存储它们: 将每个项存储在索引中并执行多索引搜索 将所有enties存储在单个索引中,并且只搜索1个索引。 一般而言,我想要一个时间复杂度之间的比较搜索“N”实体与“M”特征在上述每一种情况!
-
本文向大家介绍Python中使用haystack实现django全文检索搜索引擎功能,包括了Python中使用haystack实现django全文检索搜索引擎功能的使用技巧和注意事项,需要的朋友参考一下 前言 django是python语言的一个web框架,功能强大。配合一些插件可为web网站很方便地添加搜索功能。 搜索引擎使用whoosh,是一个纯python实现的全文搜索引擎,小巧简单。 中文
-
问题内容: 我们有两个节点的集群(私有云中的VM,64GB的RAM,每个节点8个核心CPU,CentOS),几个小索引(约100万个文档)和一个大索引,约有2.2亿个文档(2个分片,170GB)的空间)。每个盒上分配了24GB的内存用于elasticsearch。 文件结构: 运行以下查询大约需要1-2秒: 我们是在此时达到硬件极限,还是有办法优化查询或数据结构以提高性能? 提前致谢! 问题答案:
-
问题内容: 我尝试在elasticsearchJava API上使用正则表达式运行全文搜索。我的过滤器是这样的: 但是它只与一个单词匹配,而没有短语匹配。我的意思是,例如: 如果soruce中有一个字符串,例如:“ ”,而当我的文本字符串如下:“ ”,“ ”,“ ” …时,它就起作用了。 但是,当我的realTimeTextIn字符串为“ ”时,全文搜索将不起作用。我搜索的单词不能超过一个。 我在
-
我尝试在弹性搜索java api上使用正则表达式运行全文搜索。我的过滤器是这样的: 但是它只与一个单词匹配,而不是与短语匹配。我的意思是,例如: 如果soruce中有一个字符串,如:“
-
主要内容:1 独立的列,2 前缀索引和索引选择性,3 多列(组合、联合)索引,3.1 多个单列索引的问题,3.2 使用多列索引,4 选择适合的索引列顺序,5 聚簇(聚集)索引,6 覆盖索引详细介绍了各种高性能的索引使用策略,比如联合索引、索引顺序、聚簇索引、覆盖索引等等,以及常见索引失效的情况。 前面我们已经介绍了各种类型的索引结构及其对应的优缺点: BTREE索引的数据结构以及具体实现原理深入解析 哈希索引的数据结构以及索引的优缺点 正确的创建和使用索引是实现高性能查询的基础。我们通常会看到一