
PySipder 是一个 Python 爬虫程序
演示地址:http://demo.pyspider.org/
使用 Python 编写脚本,提供强大的 API
Python 2&3
强大的 WebUI 和脚本编辑器、任务监控和项目管理和结果查看
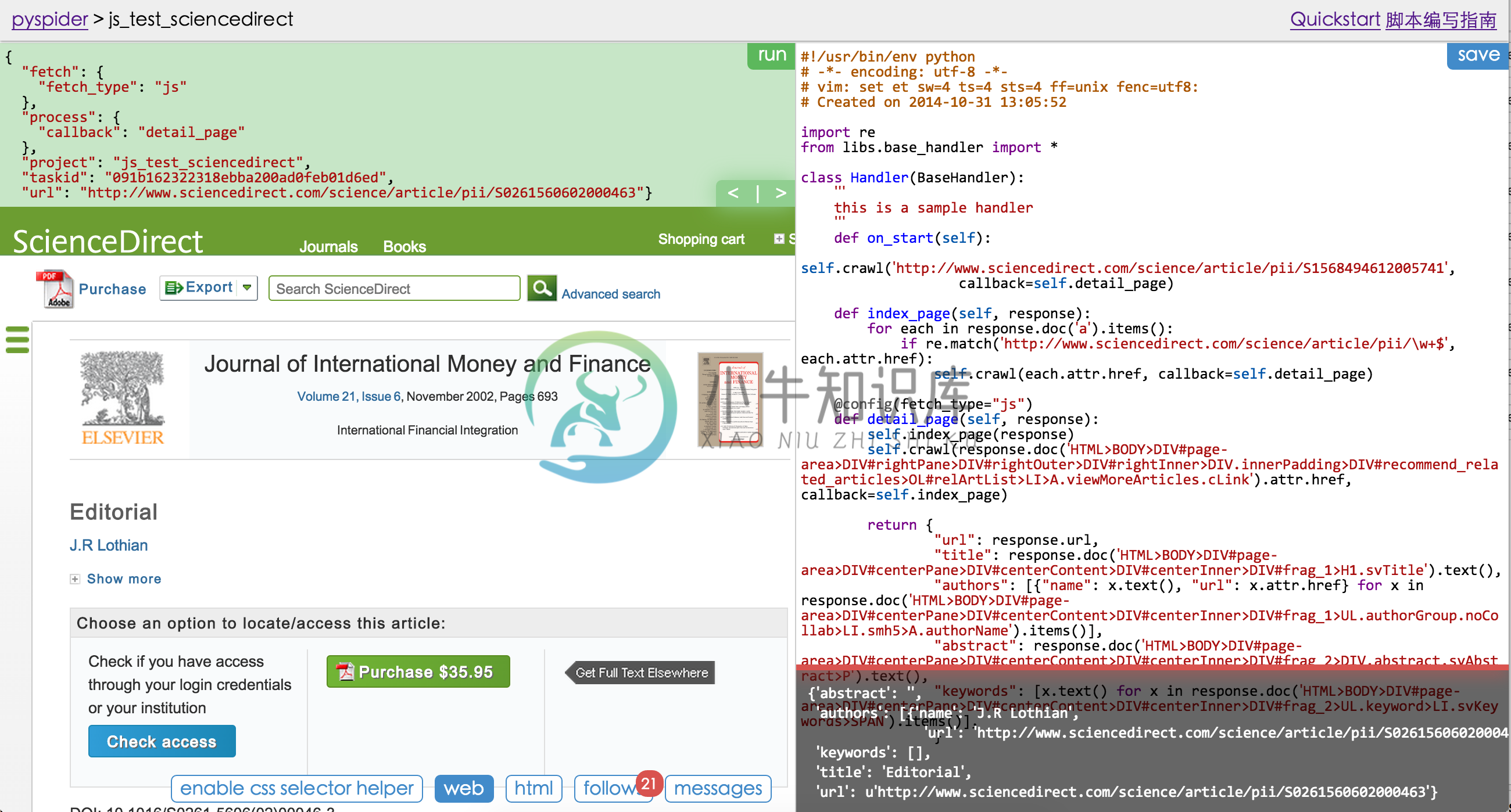
支持 JavaScript 页面
后端系统支持:MySQL, MongoDB, SQLite, Postgresql
支持任务优先级、重试、定期抓取等
分布式架构
示例代码:
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://scrapy.org/', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
}
-
概述 最近使用pyspider作为调度部署一个项目,因为客户方提供需要使用redis集群作为消息队列。所以在网上搜索了好多,都说不支持redis集群。静下心来一想,这么常规的需求不应该不支持呀。本着一切都在源码中的宗旨,打开了pyspider的源码,果然让我发现了其实是支持redis集群的。但是如果redis集群需要认证的话,就不支持了。因此,需要对pyspider的代码做一个改造,让它支持red
-
有的时候,当我们的爬虫程序完成了,并且在本地测试也没有问题,爬取了一段时间之后突然就发现报错无法抓取页面内容了。这个时候,我们很有可能是遇到了网站的反爬虫拦截。 我们知道,网站一方面想要爬虫爬取网站,比如让搜索引擎爬虫去爬取网站的内容,来增加网站的搜索排名。另一方面,由于网站的服务器资源有限,过多的非真实的用户对网站的大量访问,会增加运营成本和服务器负担。 因此,有些网站会设置一些反爬虫的措施。我
-
这一章将会介绍使用一些新的模块(optparse,spider)去完成一个爬虫的web应用。爬虫其实就是一个枚举出一个网站上面的所有链接,以帮助你创建一个网站地图的web应用程序。而使用Python则可以很快的帮助你开发出一个爬虫脚本. 你可以创建一个爬虫脚本通过href标签对请求的响应内容进行解析,并且可以在解析的同时创建一个新的请求,你还可以直接调用spider模块来实现,这样就不需要自己去写
-
主要内容:多线程使用流程,Queue队列模型,多线程爬虫案例网络爬虫程序是一种 IO 密集型程序,程序中涉及了很多网络 IO 以及本地磁盘 IO 操作,这些都会消耗大量的时间,从而降低程序的执行效率,而 Python 提供的多线程能够在一定程度上提升 IO 密集型程序的执行效率。 如果想学习 Python 多进程、多线程以及 Python GIL 全局解释器锁的相关知识,可参考《Python并发编程教程》。 多线程使用流程 Python 提供了两个支持多线
-
根据使用场景,网络爬虫可分为 通用爬虫 和 聚焦爬虫 两种. 通用爬虫 通用网络爬虫 就是 捜索引擎抓取系统,目的是将互联网上的所有的网页下载到本地,形成一个互联网内容的镜像备份。 它决定着整个搜索引擎内容的丰富性和时效性,因此它的性能优劣直接影响着搜索引擎的效果。 通用搜索引擎(Search Engine)工作原理 第一步:抓取网页 搜索引擎网络爬虫的基本工作流程如下: 首先选取一部分的初始UR
-
爬虫项是什么呢?比如采集文章列表、文章详情页,他们都是不同的采集项。 定义示例: 继承Yurun\Crawler\Module\Crawler\Contract\BaseCrawlerItem类。 <?php namespace Yurun\CrawlerApp\Module\YurunBlog\Article; use Imi\Bean\Annotation\Bean; use Yurun\C
-
本文向大家介绍java能写爬虫程序吗,包括了java能写爬虫程序吗的使用技巧和注意事项,需要的朋友参考一下 我们经常会使用网络爬虫去爬取需要的内容,提到爬虫,可能大家伙都会想到python,其实除了python,还有java。java的编程语言简单规范,是很好的爬虫工具。而且java爬虫的语言运行速度比python快,另外,java的多线程是可以利用多核的。 1、java为什么可以应用于网络爬虫?
-
主要内容:获取网页html信息,常用方法本节编写一个最简单的爬虫程序,作为学习 Python 爬虫前的开胃小菜。 下面使用 Python 内置的 urllib 库获取网页的 html 信息。注意,urllib 库属于 Python 的标准库模块,无须单独安装,它是 Python 爬虫的常用模块。 获取网页html信息 1) 获取响应对象 向百度( http://www.baidu.com/)发起请求,获取百度首页的 HTML 信息,代码
-
网络爬虫(又称为网页蜘蛛,网络机器人,在 FOAF 社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。