
oracle索引的测试实例代码

前言
在测试oracle索引性能时大意了,没有仔细分析数据特点,将情况特此记录下来。
需求: 对一张100w记录的表的 stuname列进行查询,测试在建立索引与不建立索引的区别. 以下是开始用的创建代码及执行效果.
1. 随机数据生成代码分析
--为测试索引而准备的随机数据生成代码,先分析一下
select rownum as id,
'smith'||trunc(dbms_random.value(0, 100)) as stu_name,
dbms_random.string('x', 20) stu_pwd,
to_char(add_months(sysdate,-DBMS_RANDOM.VALUE(100,200)) + rownum / 24 / 3600, 'yyyy-mm-dd hh24:mi:ss') as birthday ,
decode( TRUNC(DBMS_RANDOM.VALUE(1,5)),1,'湖南省',2,'湖北省',3,'江西省','北京市') as address
from dual
connect by level <= 100;
--先分析以下上面的代码
-- 伪列: rownum
-- dual : 测试表
-- || 字符串联接
--1. 测试生成100条记录 connect by level<=100 :
--a、利用Oracle特有的“connect by”树形连接语法生成测试记录,“level <= 100”表示要生成100记录;
--b、利用rownum虚拟列生成递增的整数数据;
--c、利用sysdate函数加一些简单运算来生成日期数据,本例中是每条记录的时间加1秒;
-- add_months(sysdate,-DBMS_RANDOM.VALUE(100,200)) 用当前时间 减去 至少100个月,最多200个月,来生成生日
--d、利用dbms_random.value函数生成随机的数值型数据,都是double型,所以都加了 trunc( )以截断小数位,本例中是生成0到100之间的随机整数;
--e、利用dbms_random.string函数生成随机的字符型数据,本例中是生成长度为20的随机字符串,字符串中可以包括字符或数字。
2. 生成测试表及数据
--2. 正式生成100W
drop table stu_test_100w; --如果原来有,则先删除原来的表
--创建表及数据
create table stu_test_100w
as
select rownum as id,
'smith'||trunc(dbms_random.value(0, 99)) as stu_name,
dbms_random.string('x', 20) stu_pwd,
to_char(add_months(sysdate,-DBMS_RANDOM.VALUE(100,200)) + rownum / 24 / 3600, 'yyyy-mm-dd hh24:mi:ss') as birthday ,
decode( TRUNC(DBMS_RANDOM.VALUE(1,5)),1,'湖南省',2,'湖北省',3,'江西省','北京市') as address
from dual
connect by level <= 1000000; -- 生成 100w测试数据
-- 查看当前用户模式下所有的表 select * from tab where tname='STU_TEST_100W'; --先执行一次查询, 注意查询所用的时间,此时并没有加入索引 select * from stu_test_100w where stu_name='smith13';
执行结果:
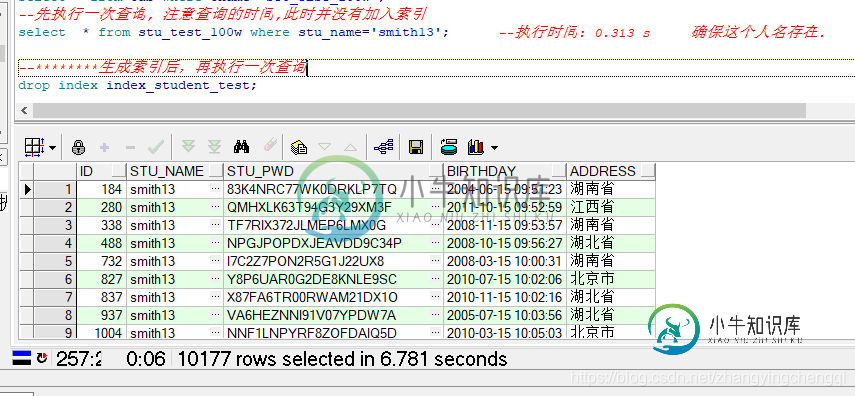
以上是没有用到索引时的执行用时 6.781秒.
下面创建索引后,再用同一查询来测试.
--********生成索引后,再执行一次查询 drop index index_student_test; create index index_student_test on stu_test_100w(stu_name); --索引是针对某个表的某个列 --先执行一次查询, 注意查询的时间,此时加入了索引 select * from stu_test_100w where stu_name='smith13';
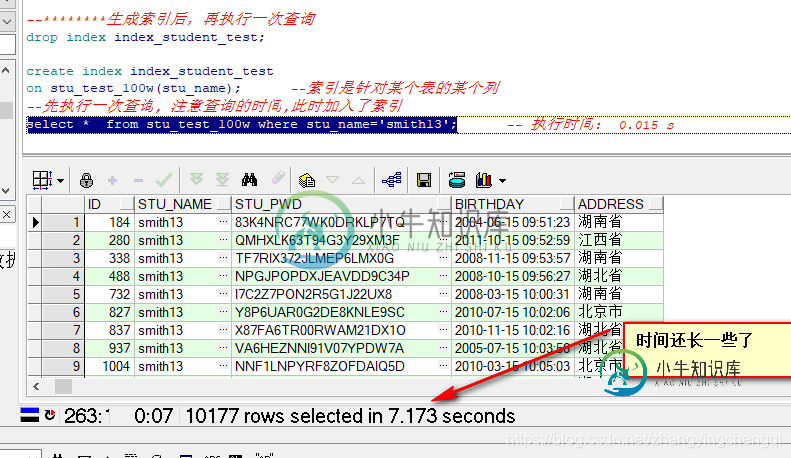
为什么用了索引后时间查询能还下降了呢????
分析如下:
1. 索引生成的字段的值分存得太密集了,查看上面的代码会发现我们stu_name只生成在了 smith0-99之间,即只有100种可能性, 对于100w数据则言,即每个名字都有约1w个.
2。 因为数据太密集了,所以以上查询的花的时间主要在1w条数据的显示上, 所以我们可以观察到不管是否用到了索引,都要共到6-7秒来显示结果.
3. 那为什么用了索引还慢一些呢? 这就与索引的存储结构有关系了.oracle默认使用的是B树索引, 当使用索引列查询时,查询必须先查看索引,通过索引去定位数据,而咱们的数据分布又比较密集,所以使用索引所导致的时间损耗要大于直接磁盘搜索的时间.
那么如何解决呢?
随机生成的姓名分布广一些(这与真实的数据也一样). 即将随机生成代码修改为 'smith'||trunc(dbms_random.value(0, 9999999)) as stu_name,
drop table stu_test_100w; --如果原来有,则先删除原来的表
--重新生成表及随机数据,注意 stu_name列的取值范围加大
create table stu_test_100w
as
select rownum as id,
'smith'||trunc(dbms_random.value(0, 9999999)) as stu_name,
dbms_random.string('x', 20) stu_pwd,
to_char(add_months(sysdate,-DBMS_RANDOM.VALUE(100,200)) + rownum / 24 / 3600, 'yyyy-mm-dd hh24:mi:ss') as birthday ,
decode( TRUNC(DBMS_RANDOM.VALUE(1,5)),1,'湖南省',2,'湖北省',3,'江西省','北京市') as address
from dual
connect by level <= 1000000;
--先执行一次查询, 注意查询的时间,此时并没有加入索引
select * from stu_test_100w where stu_name='smith8821228';
执行结果如下:
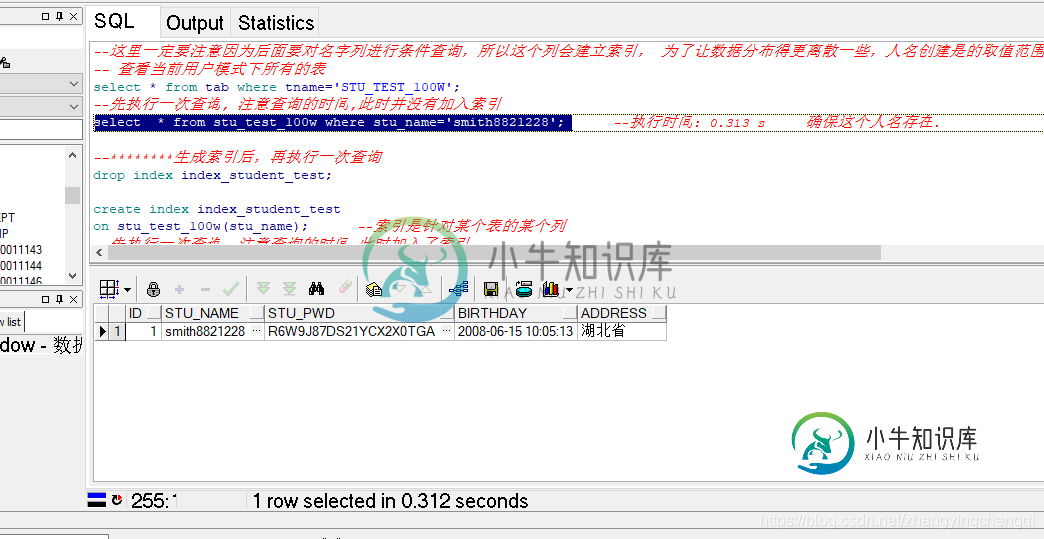
用时 0.312秒.
接着创建索引后,再测试同一个查询
--********生成索引后,再执行一次查询 drop index index_student_test; create index index_student_test on stu_test_100w(stu_name); --索引是针对某个表的某个列 --先执行一次查询, 注意查询的时间,此时加入了索引 select * from stu_test_100w where stu_name='smith8821228';
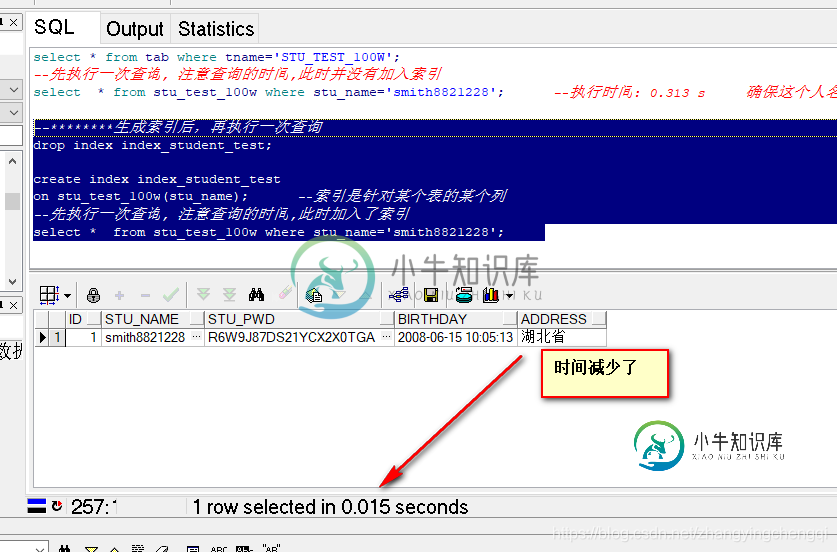
使用索引后,同一个查询只需0.015秒,在原来用时0.312的基础下,下降了n倍.
总结
到此这篇关于oracle索引测试的文章就介绍到这了,更多相关oracle索引测试内容请搜索小牛知识库以前的文章或继续浏览下面的相关文章希望大家以后多多支持小牛知识库!
-
本文向大家介绍python的unittest测试类代码实例,包括了python的unittest测试类代码实例的使用技巧和注意事项,需要的朋友参考一下 nittest单元测试框架不仅可以适用于单元测试,还可以适用WEB自动化测试用例的开发与执行,该测试框架可组织执行测试用例,并且提供了丰富的断言方法,判断测试用例是否通过,最终生成测试结果。今天笔者就总结下如何使用unittest单元测试框架来进行
-
本文向大家介绍Oracle 分区索引介绍和实例演示,包括了Oracle 分区索引介绍和实例演示的使用技巧和注意事项,需要的朋友参考一下 分区索引(或索引分区)主要是针对分区表而言的。随着数据量的不断增长,普通的堆表需要转换到分区表,其索引呢,则对应的转换到分区索引。分区索引的好处是显而易见的。就是简单地把一个索引分成多个片断,在获取所需数据时,只需要访问更小的索引片断(块)即可实现。同时把分区放在
-
本文向大家介绍Oracle触发器实例代码,包括了Oracle触发器实例代码的使用技巧和注意事项,需要的朋友参考一下 Oracle触发器,用于选单后修改选单的表的触发动作。 以上所述是小编给大家介绍的Oracle触发器实例代码,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对呐喊教程网站的支持!
-
问题内容: 可以说我有两个表,和。 我创建如下视图: 如果执行以下操作: 如果是index和index ,那么我们应该可以通过两个索引搜索来做到这一点。 但是,如果我可以在一个索引中对两个表建立索引,甚至对视图建立索引,那都会很好,如果源表(或)发生更改,该方法可以立即自动更新。 在Oracle中有没有办法做到这一点? 问题答案: 我不能与Oracle相提并论,但是我相信物化视图可以做到这一点。
-
本文向大家介绍react native带索引的城市列表组件的实例代码,包括了react native带索引的城市列表组件的实例代码的使用技巧和注意事项,需要的朋友参考一下 城市列表选择是很多app共有的功能,比如典型的美图app。那么对于React Native怎么实现呢? 要实现上面的效果,首先需要对界面的组成简单分析,界面的数据主要由当前城市,历史访问城市和热门城市组成,所以我们在提供Json
-
我正在开发一个用于信息检索的web应用程序(使用JSF),我正在使用Lucene读取和索引file.pdf。我读了前面的一个关于LockObtainFailedException的问题(在new IndexWriter()处),但是我仍然无法解决我的问题,所以我将简要地解释一下。 我有一个managedBean使用以下方法对文档进行索引: 当我启动我的应用程序(主页)时,我注意到Indexer和我