
使用keras框架cnn+ctc_loss识别不定长字符图片操作

我就废话不多说了,大家还是直接看代码吧~
# -*- coding: utf-8 -*- #keras==2.0.5 #tensorflow==1.1.0 import os,sys,string import sys import logging import multiprocessing import time import json import cv2 import numpy as np from sklearn.model_selection import train_test_split import keras import keras.backend as K from keras.datasets import mnist from keras.models import * from keras.layers import * from keras.optimizers import * from keras.callbacks import * from keras import backend as K # from keras.utils.visualize_util import plot from visual_callbacks import AccLossPlotter plotter = AccLossPlotter(graphs=['acc', 'loss'], save_graph=True, save_graph_path=sys.path[0]) #识别字符集 char_ocr='0123456789' #string.digits #定义识别字符串的最大长度 seq_len=8 #识别结果集合个数 0-9 label_count=len(char_ocr)+1 def get_label(filepath): # print(str(os.path.split(filepath)[-1]).split('.')[0].split('_')[-1]) lab=[] for num in str(os.path.split(filepath)[-1]).split('.')[0].split('_')[-1]: lab.append(int(char_ocr.find(num))) if len(lab) < seq_len: cur_seq_len = len(lab) for i in range(seq_len - cur_seq_len): lab.append(label_count) # return lab def gen_image_data(dir=r'data\train', file_list=[]): dir_path = dir for rt, dirs, files in os.walk(dir_path): # =pathDir for filename in files: # print (filename) if filename.find('.') >= 0: (shotname, extension) = os.path.splitext(filename) # print shotname,extension if extension == '.tif': # extension == '.png' or file_list.append(os.path.join('%s\\%s' % (rt, filename))) # print (filename) print(len(file_list)) index = 0 X = [] Y = [] for file in file_list: index += 1 # if index>1000: # break # print(file) img = cv2.imread(file, 0) # print(np.shape(img)) # cv2.namedWindow("the window") # cv2.imshow("the window",img) img = cv2.resize(img, (150, 50), interpolation=cv2.INTER_CUBIC) img = cv2.transpose(img,(50,150)) img =cv2.flip(img,1) # cv2.namedWindow("the window") # cv2.imshow("the window",img) # cv2.waitKey() img = (255 - img) / 256 # 反色处理 X.append([img]) Y.append(get_label(file)) # print(get_label(file)) # print(np.shape(X)) # print(np.shape(X)) # print(np.shape(X)) X = np.transpose(X, (0, 2, 3, 1)) X = np.array(X) Y = np.array(Y) return X,Y # the actual loss calc occurs here despite it not being # an internal Keras loss function def ctc_lambda_func(args): y_pred, labels, input_length, label_length = args # the 2 is critical here since the first couple outputs of the RNN # tend to be garbage: # y_pred = y_pred[:, 2:, :] 测试感觉没影响 y_pred = y_pred[:, :, :] return K.ctc_batch_cost(labels, y_pred, input_length, label_length) if __name__ == '__main__': height=150 width=50 input_tensor = Input((height, width, 1)) x = input_tensor for i in range(3): x = Convolution2D(32*2**i, (3, 3), activation='relu', padding='same')(x) # x = Convolution2D(32*2**i, (3, 3), activation='relu')(x) x = MaxPooling2D(pool_size=(2, 2))(x) conv_shape = x.get_shape() # print(conv_shape) x = Reshape(target_shape=(int(conv_shape[1]), int(conv_shape[2] * conv_shape[3])))(x) x = Dense(32, activation='relu')(x) gru_1 = GRU(32, return_sequences=True, kernel_initializer='he_normal', name='gru1')(x) gru_1b = GRU(32, return_sequences=True, go_backwards=True, kernel_initializer='he_normal', name='gru1_b')(x) gru1_merged = add([gru_1, gru_1b]) ################### gru_2 = GRU(32, return_sequences=True, kernel_initializer='he_normal', name='gru2')(gru1_merged) gru_2b = GRU(32, return_sequences=True, go_backwards=True, kernel_initializer='he_normal', name='gru2_b')( gru1_merged) x = concatenate([gru_2, gru_2b]) ###################### x = Dropout(0.25)(x) x = Dense(label_count, kernel_initializer='he_normal', activation='softmax')(x) base_model = Model(inputs=input_tensor, outputs=x) labels = Input(name='the_labels', shape=[seq_len], dtype='float32') input_length = Input(name='input_length', shape=[1], dtype='int64') label_length = Input(name='label_length', shape=[1], dtype='int64') loss_out = Lambda(ctc_lambda_func, output_shape=(1,), name='ctc')([x, labels, input_length, label_length]) model = Model(inputs=[input_tensor, labels, input_length, label_length], outputs=[loss_out]) model.compile(loss={'ctc': lambda y_true, y_pred: y_pred}, optimizer='adadelta') model.summary() def test(base_model): file_list = [] X, Y = gen_image_data(r'data\test', file_list) y_pred = base_model.predict(X) shape = y_pred[:, :, :].shape # 2: out = K.get_value(K.ctc_decode(y_pred[:, :, :], input_length=np.ones(shape[0]) * shape[1])[0][0])[:, :seq_len] # 2: print() error_count=0 for i in range(len(X)): print(file_list[i]) str_src = str(os.path.split(file_list[i])[-1]).split('.')[0].split('_')[-1] print(out[i]) str_out = ''.join([str(x) for x in out[i] if x!=-1 ]) print(str_src, str_out) if str_src!=str_out: error_count+=1 print('################################',error_count) # img = cv2.imread(file_list[i]) # cv2.imshow('image', img) # cv2.waitKey() class LossHistory(Callback): def on_train_begin(self, logs={}): self.losses = [] def on_epoch_end(self, epoch, logs=None): model.save_weights('model_1018.w') base_model.save_weights('base_model_1018.w') test(base_model) def on_batch_end(self, batch, logs={}): self.losses.append(logs.get('loss')) # checkpointer = ModelCheckpoint(filepath="keras_seq2seq_1018.hdf5", verbose=1, save_best_only=True, ) history = LossHistory() # base_model.load_weights('base_model_1018.w') # model.load_weights('model_1018.w') X,Y=gen_image_data() maxin=4900 subseq_size = 100 batch_size=10 result=model.fit([X[:maxin], Y[:maxin], np.array(np.ones(len(X))*int(conv_shape[1]))[:maxin], np.array(np.ones(len(X))*seq_len)[:maxin]], Y[:maxin], batch_size=20, epochs=1000, callbacks=[history, plotter, EarlyStopping(patience=10)], #checkpointer, history, validation_data=([X[maxin:], Y[maxin:], np.array(np.ones(len(X))*int(conv_shape[1]))[maxin:], np.array(np.ones(len(X))*seq_len)[maxin:]], Y[maxin:]), ) test(base_model) K.clear_session()
补充知识:日常填坑之keras.backend.ctc_batch_cost参数问题
InvalidArgumentError sequence_length(0) <=30错误
下面的代码是在网上绝大多数文章给出的关于k.ctc_batch_cost()函数的使用代码
def ctc_lambda_func(args): y_pred, labels, input_length, label_length = args # the 2 is critical here since the first couple outputs of the RNN # tend to be garbage: y_pred = y_pred[:, 2:, :] return K.ctc_batch_cost(labels, y_pred, input_length, label_length)
可以注意到有一句:y_pred = y_pred[:, 2:, :],这里把y_pred 的第二维数据去掉了两列,说人话:把送进lstm序列的step减了2步。后来偶然在一篇文章中有提到说这里之所以减2是因为在将feature送入keras的lstm时自动少了2维,所以这里就写成这样了。估计是之前老版本的bug,现在的新版本已经修复了。如果依然按照上面的写法,会得到如下错误:
InvalidArgumentError sequence_length(0) <=30
'<='后面的数值 = 你cnn最后的输出维度 - 2。这个错误我找了很久,一直不明白30哪里来的,后来一行行的检查代码是发现了这里很可疑,于是改成如下形式错误解决。
def ctc_lambda_func(args): y_pred, labels, input_length, label_length = args return K.ctc_batch_cost(labels, y_pred, input_length, label_length)
训练时出现ctc_loss_calculator.cc:144] No valid path found或loss: inf错误
熟悉CTC算法的话,这个提示应该是ctc没找到有效路径。既然是没找到有效路径,那肯定是label和input之间哪个地方又出问题了!和input相关的错误已经解决了,那么肯定就是label的问题了。再看ctc_batch_cost的四个参数,labels和label_length这两个地方有可疑。对于ctc_batch_cost()的参数,labels需要one-hot编码,形状:[batch, max_labelLength],其中max_labelLength指预测的最大字符长度;label_length就是每个label中的字符长度了,受之前tf.ctc_loss的影响把这里都设置成了最大长度,所以报错。
对于参数labels而言,max_labelLength是能预测的最大字符长度。这个值与送lstm的featue的第二维,即特征序列的max_step有关,表面上看只要max_labelLength<max_step即可,但是如果小的不多依然会出现上述错误。至于到底要小多少,还得从ctc算法里找,由于ctc算法在标签中的每个字符后都加了一个空格,所以应该把这个长度考虑进去,所以有 max_labelLength < max_step//2。没仔细研究keras里ctc_batch_cost()函数的实现细节,上面是我的猜测。如果有很明确的答案,还请麻烦告诉我一声,谢了先!
错误代码:
batch_label_length = np.ones(batch_size) * max_labelLength
正确打开方式:
batch_x, batch_y = [], [] batch_input_length = np.ones(batch_size) * (max_img_weigth//8) batch_label_length = [] for j in range(i, i + batch_size): x, y = self.get_img_data(index_all[j]) batch_x.append(x) batch_y.append(y) batch_label_length.append(self.label_length[j])
最后附一张我的crnn的模型图:
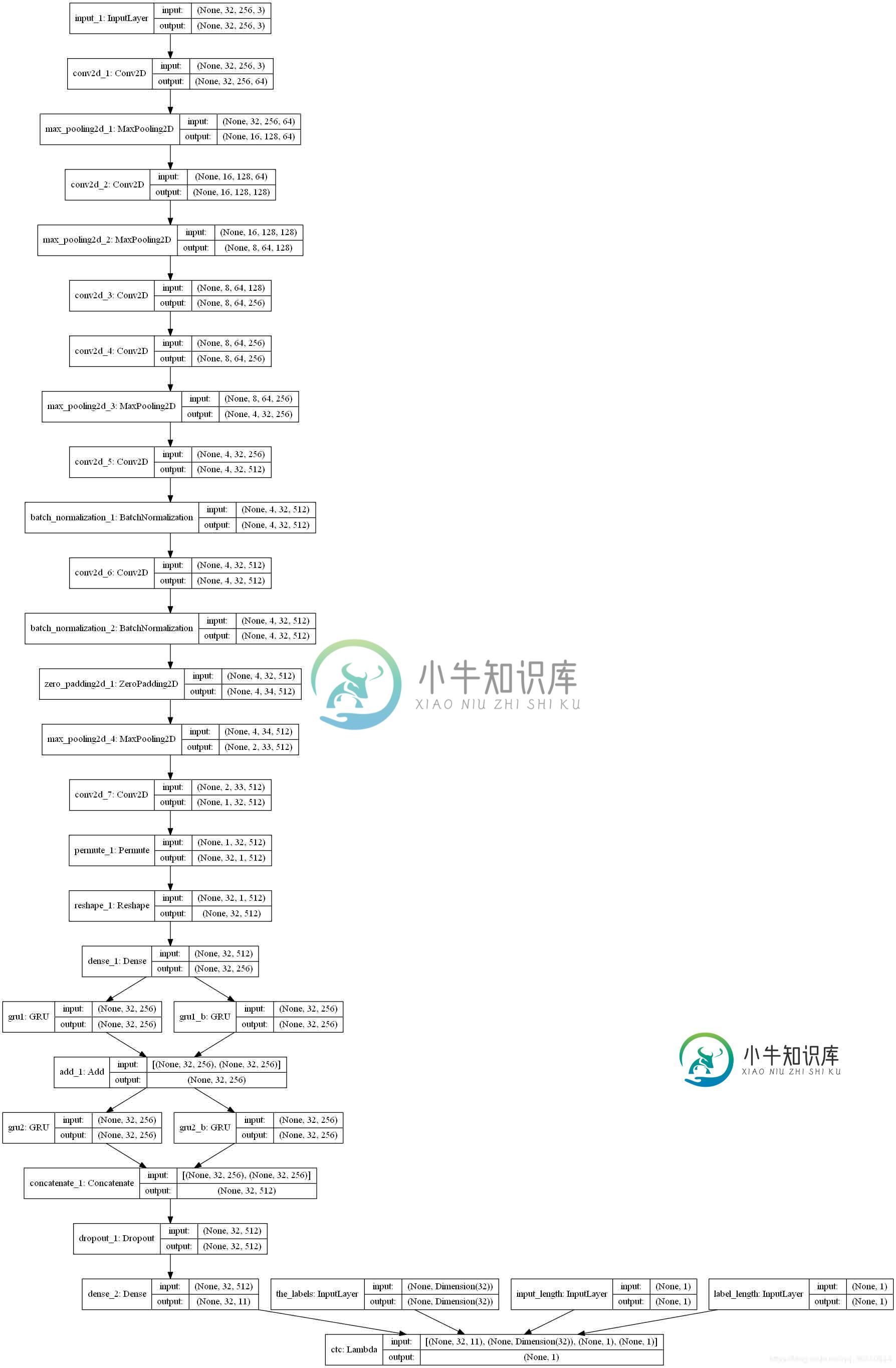
以上这篇使用keras框架cnn+ctc_loss识别不定长字符图片操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持小牛知识库。
-
我想在我的教程django项目中使用rest_framework。 我按照指示步骤添加了rest_frameworksettings.py如下所示。 但是,pycharm无法识别“rest_框架”,并且在我尝试运行服务器时出现错误: 未能在模块“DjangoProject”上获取实际命令:python进程在django中的代码1:Traceback(最近一次调用):文件“E:\PyCharm 20
-
本文向大家介绍pytorch cnn 识别手写的字实现自建图片数据,包括了pytorch cnn 识别手写的字实现自建图片数据的使用技巧和注意事项,需要的朋友参考一下 本文主要介绍了pytorch cnn 识别手写的字实现自建图片数据,分享给大家,具体如下: 图片和label 见上一篇文章《pytorch 把MNIST数据集转换成图片和txt》 结果如下: 以上就是本文的全部内容,希望对大家的学习
-
问题内容: 我正在寻找一个Java框架来帮助进行一些特定于图像的数据挖掘。我们有一组历史图像,我想对其进行分类和分类。我希望找到类似weka的东西http://www.cs.waikato.ac.nz/ml/weka/或Marsyas http://marsyas.sness.net,但更特定于通过图像数据进行筛选以找到图案。有什么建议? 问题答案: 如何使用OpenCV 库进行处理?从技术上讲,
-
综述 Web框架[*]识别是信息收集过程简单重要的子任务。知道一个已知类型的框架而且被渗透测试过,这自然而然是一个巨大的优势。除了发现在未打补丁版本中的已知漏洞,还有了解在框架中特定的错误配置和已知文件目录框架使这一识别过程变得非常重要。 一些不同开发商不同版本的web框架被广泛使用。了解框架的信息对测试过程有极大帮助,也能帮助改进测试方案。这些信息可以从一些常见的地方仔细分析推断出来。大多数的w
-
本文向大家介绍C#识别出图片里的数字和字母,包括了C#识别出图片里的数字和字母的使用技巧和注意事项,需要的朋友参考一下 一个图片识别小工具,原先主要是识别以前公司的软件注册码截图里的数字和字母(每次要一个一个框复制出来粘贴到注册器里,很麻烦!),因为注册码出现的字母和数字基本就那几个,所以识别库的范围设定的比较少。 原理和算法在代码中做了详细说明,功能存在很大的局限性,但我的想法是把这个思路和实现