
Python 正则表达式的高级用法

对于Python来说,学习正则就要学习模块re的使用方法。本文将展示一些大家都应该掌握的高级技巧。
编译正则对象
re.compile函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。用法上略有区别,举个例子, 匹配一个字符串可用如下方式:
如果使用compile,将变成:
为什么要这么用呢?其实就是为了提高正则匹配的速度,重复利用正则表达式对象。我们对比一下2种方式的效率:
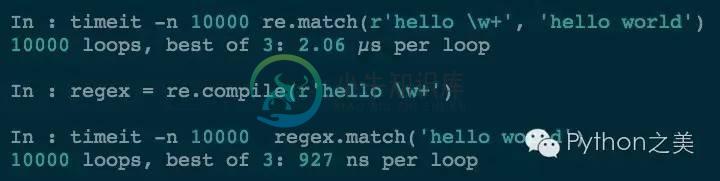
可以看到第二种方式要快很多。在实际的工作中你会发现越多的使用编译好的正则表达式对象,效果就越好。
分组(group)
你可能已经见过对匹配的内容进行分组的用法了:
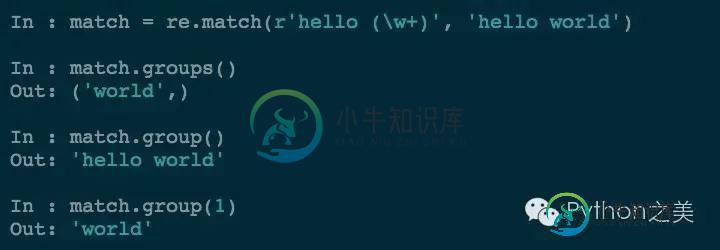
通过对要匹配的对象添加括号,就可以精确的对应符合的结果了。我们还可以进行嵌套的分组:

分组可以满足需求,但是有时候可读性很差,那可以对分组进行命名:
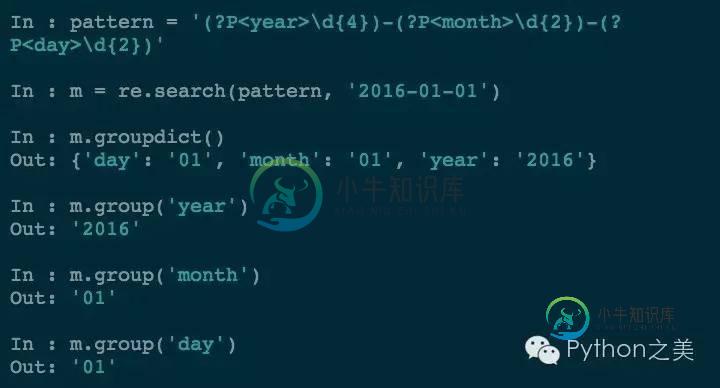
现在可读性就非常高了。
字符串匹配
学过sed的同学可能见过如下替换用法:
这个\1表示前面正则匹配到的结果。上面的sed也就是给匹配到的结果加上中括号。
在re模块中也存在这样的用法:

用命名分组也是可以的:

附近匹配(Look around)
re模块也支持附近匹配,看看例子就懂了:

正则匹配的时候使用函数
之前我们看到的大部分内容都是匹配的是一个表达式,但是有时候需求要复杂得多,尤其是在替换的时候。
举个例子,通过Slack的API能获取聊天记录,比如下面这句:
其中<@U1EAT8MG9>和<@U0K1MF23Z>是2个真实的用户,但是被Slack封装了,需要通过其他接口获取这个对应关系,
其结果类似这样:
在解析对应关系之后,还希望吧尖括号也去掉,替换后的结果是「@xiaoming, @laolin 嗯 确实是这样的 」
用正则怎么实现呢?

所以pattern当然也可以是一个函数
-
问题内容: 假设我想要一个正则表达式,使其与“从iPhone发送”和“从iPod发送”都匹配。我该如何写这样的表达? 我尝试过类似的事情: 但似乎不起作用。 问题答案:
-
问题内容: 我试图在Python 2.7.2中使用正则表达式从字符串中提取所有出现的带标记单词。或者简单地说,我想提取标签内的所有文本。这是我的尝试: 印刷产品 要获取的正确正则表达式是: 或。 谢谢。:) 问题答案: 产量 regex与unicode完全相同,但难于阅读。 第一个括号组告诉重新任何列表中的字符应匹配,并且同样与第二组括号。那你想什么都不要。所以, 卸下外围的方括号。(也除去杂散前
-
问题内容: 我正在尝试抓取“ ”标记后的所有内容并将其删除,但是我的代码似乎没有执行任何操作。难道不支持正则表达式? 问题答案: 否。Python中的正则表达式由模块处理。 一般来说:
-
昨天,我需要向正则表达式添加一个文件路径,创建一个如下所示的模式: 一开始正则表达式不匹配,因为包含几个正则表达式特定的符号,如 或 。作为快速修复,我将它们替换为 和 . 与 . 然而,我问自己,是否没有一种更可靠或更好的方法来清除正则表达式特定符号中的字符串。 Python 标准库中是否支持此类功能? 如果没有,您是否知道一个正则表达式来识别所有正则表达式并通过替代品清理它们?
-
问题内容: 我需要替换字符串的一部分。我浏览了Python文档并发现了re.sub。 我期望这能打印,而不是“酒吧”。 谁能告诉我我做错了什么? 问题答案: 除了捕获要 替换 的零件外,您还可以捕获要 保留 的零件,然后使用引用对其进行引用以将它们包括在替换字符串中。 尝试以下方法: 另外,假设这是HTML,则应考虑使用HTML解析器来执行此任务,例如Beautiful Soup 。
-
问题内容: 我正在研究道格·海尔曼(Doug Hellman)的“示例Python标准库”,并发现了这一点: “ 1.3.2编译表达式re包含用于将正则表达式作为文本字符串使用的模块级函数,但是编译程序经常使用的表达式更为有效。” 对于这种情况,我无法理解他的解释。他说“模块级功能维护编译后的表达式的缓存”,并且由于“缓存的大小”受到限制,因此“直接使用编译后的表达式可以避免缓存查找开销。” 如果