
python 画出使用分类器得到的决策边界

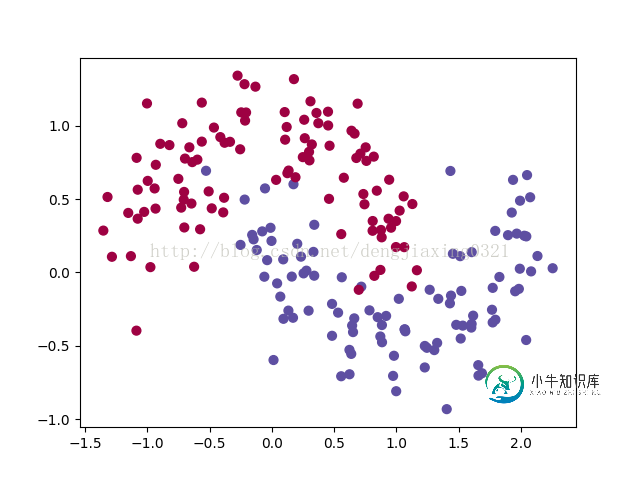
获取数据集,并画图代码如下:
import numpy as np from sklearn.datasets import make_moons import matplotlib.pyplot as plt # 手动生成一个随机的平面点分布,并画出来 np.random.seed(0) X, y = make_moons(200, noise=0.20) plt.scatter(X[:,0], X[:,1], s=40, c=y, cmap=plt.cm.Spectral) plt.show()
得到图如下:
定义决策边界函数:
# 咱们先顶一个一个函数来画决策边界 def plot_decision_boundary(pred_func): # 设定最大最小值,附加一点点边缘填充 x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5 y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5 h = 0.01 xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) # 用预测函数预测一下 Z = pred_func(np.c_[xx.ravel(), yy.ravel()]) Z = Z.reshape(xx.shape) # 然后画出图 plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral) plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Spectral)
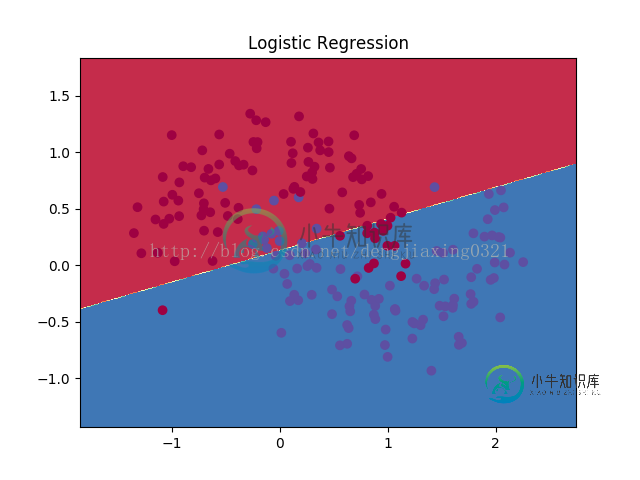
定义分类函数,并画出决策边界图代码如下:
from sklearn.linear_model import LogisticRegressionCV
#咱们先来瞄一眼逻辑斯特回归对于它的分类效果
clf = LogisticRegressionCV()
clf.fit(X, y)
# 画一下决策边界
plot_decision_boundary(lambda x: clf.predict(x))
plt.title("Logistic Regression")
plt.show()
画图如下:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
我是新来的ML在Python和非常困惑如何实现一个决策树与分类变量,因为他们得到自动编码的和在。 我想做一个具有两个分类独立特征和一个依赖类的决策树。 我使用的数据帧如下所示: 我知道分类特征需要使用labelencoder和/或一个热编码器在scikit learn中编码。 首先,我尝试只使用标签编码器,但这并不能解决问题,因为开始将编码的变量视为连续变量。然后我从这篇文章中读到:OneHotE
-
问题内容: 我对matplotlib非常陌生,并且正在从事一些简单的项目以熟悉它。我想知道如何绘制决策边界,决策边界是[w1,w2]形式的权重向量,它使用matplotlib将两个类(例如C1和C2)基本分开。 如果是这样,是否像从(0,0)到点(w1,w2)画一条线一样简单(因为W是权重“向量”),如果需要,如何像在两个方向上一样进行扩展? 现在我要做的是: 提前致谢。 问题答案: 决策边界通常
-
问题内容: 显然,我没有正确使用此测试装置。我的servlet在tomcat中工作得很好,但是当我尝试使用此模拟程序时,找不到多部分边界。“该请求被拒绝,因为未找到多部分边界”。 此处有一个答案,显示了如何通过文本文件使用此答案,但该答案明确设置了边界字符串并将该文件嵌入为test。我认为我不需要手动处理诸如 ockerrequest.addFile (…)之类的方法 我在这里没有设置什么或者我做
-
问题内容: 关于如何将分类数据编码到Sklearn决策树中,有几篇文章,但是从Sklearn文档中,我们得到了这些。 决策树的一些优点是: (…) 能够处理数字和分类数据。其他技术通常专用于分析仅具有一种类型的变量的数据集。有关更多信息,请参见算法。 但是运行以下脚本 输出以下错误: 我知道在R中可以通过Sklearn传递分类数据,这可能吗? 问题答案: 与接受的答案相反,我更愿意使用Scikit
-
主要内容:决策树算法应用,决策树实现步骤,决策树算法应用本节基于 Python Sklearn 机器学习算法库,对决策树这类算法做相关介绍,并对该算法的使用步骤做简单的总结,最后通过应用案例对决策树算法的代码实现进行演示。 决策树算法应用 在 sklearn 库中与决策树相关的算法都存放在 模块里,该模块提供了 4 个决策树算法,下面对这些算法做简单的介绍: 1) .DecisionTreeClassifier() 这是一个经典的决策树分类算法,它提供
-
1 决策树理论 1.1 什么是决策树 所谓决策树,顾名思义,是一种树,一种依托于策略抉择而建立起来的树。机器学习中,决策树是一个预测模型;他代表的是对象属性与对象值之间的一种映射关系。 树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,从根节点到叶节点所经历的路径对应一个判定测试序列。决策树仅有单一输出,若欲有复数输出,可以建立独立的决策树以处理不同输出。 1.2 决策树学习流