
C#使用HtmlAgilityPack抓取糗事百科内容实例

本文实例讲述了C#使用HtmlAgilityPack抓取糗事百科内容的方法。分享给大家供大家参考。具体实现方法如下:
Console.WriteLine("*****************糗事百科24小时热门*******************");
Console.WriteLine("请输入页码,输入0退出");
string page = Console.ReadLine();
while (page!="0") {
HtmlWeb htmlWeb = new HtmlWeb();
HtmlDocument htmlDoc = htmlWeb.Load("http://www.qiushibaike.com/hot/page/"+page);
HtmlNodeCollection qiuNodeList = htmlDoc.DocumentNode.SelectNodes("//*[@class='content']");
foreach (HtmlNode qiuCont in qiuNodeList) {
Console.WriteLine(qiuCont.InnerHtml);
Console.WriteLine("******************************************************************************");
}
Console.WriteLine("请输入页码,输入0退出");
page = Console.ReadLine();
}
运行效果如下图所示:
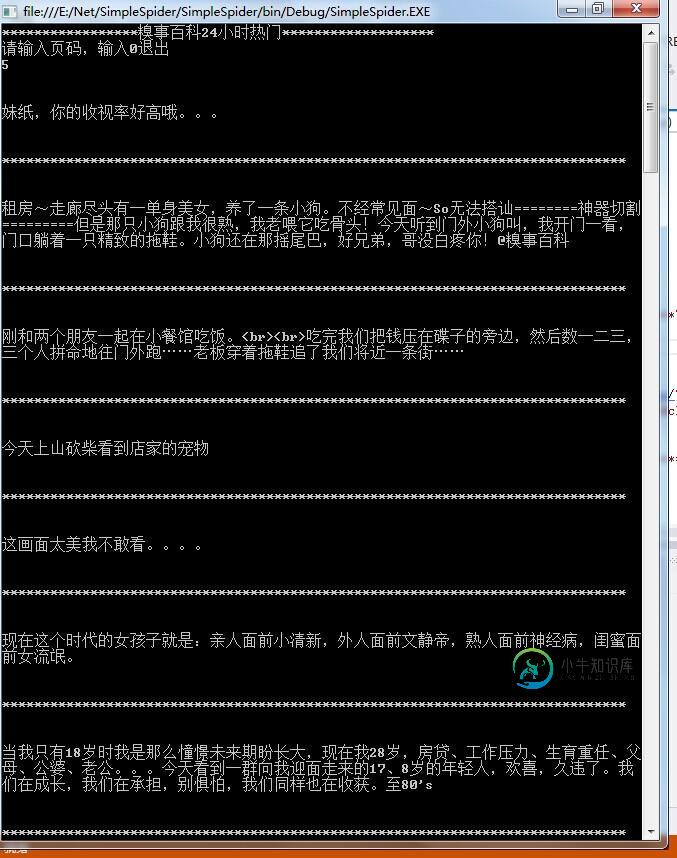
希望本文所述对大家的C#程序设计有所帮助。
-
本文向大家介绍NodeJS爬虫实例之糗事百科,包括了NodeJS爬虫实例之糗事百科的使用技巧和注意事项,需要的朋友参考一下 1.前言分析 往常都是利用 Python/.NET 语言实现爬虫,然现在作为一名前端开发人员,自然需要熟练 NodeJS。下面利用 NodeJS 语言实现一个糗事百科的爬虫。另外,本文使用的部分代码是 es6 语法。 实现该爬虫所需要的依赖库如下。 request: 利用 g
-
糗事百科的客户端,功能齐全,可以浏览帖子图片。 开发者说:自己写的糗事百科的客户端,没有广告,滑动也不卡。 [Code4App.com]
-
本文向大家介绍Python 制作糗事百科爬虫实例,包括了Python 制作糗事百科爬虫实例的使用技巧和注意事项,需要的朋友参考一下 早上起来闲来无事做,莫名其妙的就弹出了糗事百科的段子,转念一想既然你送上门来,那我就写个爬虫到你网站上爬一爬吧,一来当做练练手,二来也算找点乐子。 其实这两天也正在接触数据库的内容,可以将爬取下来的数据保存在数据库中,以待以后的利用。好了,废话不多说了,先来看看程序爬
-
本文向大家介绍PHP实现抓取HTTPS内容,包括了PHP实现抓取HTTPS内容的使用技巧和注意事项,需要的朋友参考一下 最近在研究Hacker News API时遇到一个HTTPS问题。因为所有的Hacker News API都是通过加密的HTTPS协议访问的,跟普通的HTTP协议不同,当使用PHP里的函数 file_get_contents() 来获取API里提供的数据时,出现错误,使用的代码是
-
问题内容: 我想使用Python在这样的网页上抓取“正在寻找这些作者:”框中的内容:http : //academic.research.microsoft.com/Search?query=lander 不幸的是,盒子的内容是由JavaScript动态加载的。通常在这种情况下,我可以阅读Javascript来了解发生了什么,或者可以使用Firebug之类的浏览器扩展来了解动态内容的来源。这次没有
-
问题内容: 免责声明:我在StackOverflow上看到过许多其他类似的帖子,并尝试以相同的方式进行操作,但是它们似乎在此网站上不起作用。 我正在使用Python-Scrapy从koovs.com获取数据。 但是,我无法获得动态生成的产品尺寸。具体来说,如果有人可以引导我从此链接的下拉菜单中获取“不可用”尺寸标签,我将不胜感激。 我可以静态获取尺寸列表,但这样做只能得到尺寸列表,但不能获得其中的